1 Prelude: Examples of Dynamic Programs
Dynamic programming is a recursive technique for solving optimization problems. While initially developed for intertemporal problems (inventory management, investment planning, optimal savings and consumption, etc.), it has since been applied to various atemporal problems, ranging from genome sequencing and matrix multiplication to the structure of production chains. Creators of machine learning and artificial intelligence routinely use dynamic programming.
The sheer breadth of applications currently being tackled with dynamic programming is a challenge for presenting a modern theory. As well as the vast range of concrete problems faced in applied settings, researchers are adding features to their models that require extensions of the foundations of dynamic programming. Such new features include time-varying discount rates, nonlinear discounting, risk-sensitive control, ambiguity aversion, nonlinear time aggregation, and so on. Researchers added these features in their quests to create new models capable of coming closer to data sets of interest.
To set the scene, we begin with some problems that can be handled using classic methods. Then we discuss extensions and transformations that require more sophisticated theoretical foundations. Since our purpose here is to set the stage for the abstract theory that is the main focus of this Volume, our presentation here is mathematically informal at many points. Results stated in this chapter are special cases of the abstract theory, which begins in Chapter 2.
1.1A Firm Problem¶
This section uses a firm valuation and control problem to introduce core dynamic programming concepts. We begin with traditional methods, showing how recursive representations lead to the Bellman equation and optimal policies. We then discuss extensions involving unbounded rewards, time-varying discount rates, and risk-sensitive preferences.
1.1.1Models of a Firm¶
We first consider firm valuation under a Markov profit process, deriving a recursive representation for expected present value. Next, by giving the manager an option to sell the firm at a time of their choosing, we add a control. A Bellman type of optimality is then stated and proved. This material establishes a template for dynamic programs that recur throughout this chapter.
1.1.1.1Valuation¶
A firm generates a random flow of profits . At time , a manager wants to calculate the present value of the profit process. Current profits are known but future values are not. The manager knows the distribution of the process . Consequently the manager can compute the expected present value, namely
Here is a discount factor, often reparameterized as when is a discount rate. Thus, is time profits discounted to the present date . The symbol denotes mathematical expectation conditional on time information.
We can switch to a recursive representation of the sequence of valuations by first writing
and then applying the law of iterated expectations . This leads to
This expression will be important for us because the theory of dynamic programming is built around recursive relationships. Later we will see many variations of (1.1).
To make further progress in computing , let’s assume that , where is a discrete time Markov process taking values in a measurable space . We assume that is driven by a stochastic kernel (see Section A.5.4.1), so that is the probability that given current state . The function is assumed to be in , the set of bounded, -measurable functions from to . We understand as representing the “state of the world”, including all factors affecting firm profits. Figure 1.1 shows multiple realizations of the profit process in the case where , is the Borel sets, , and is a discretization of an AR(1) process with and .
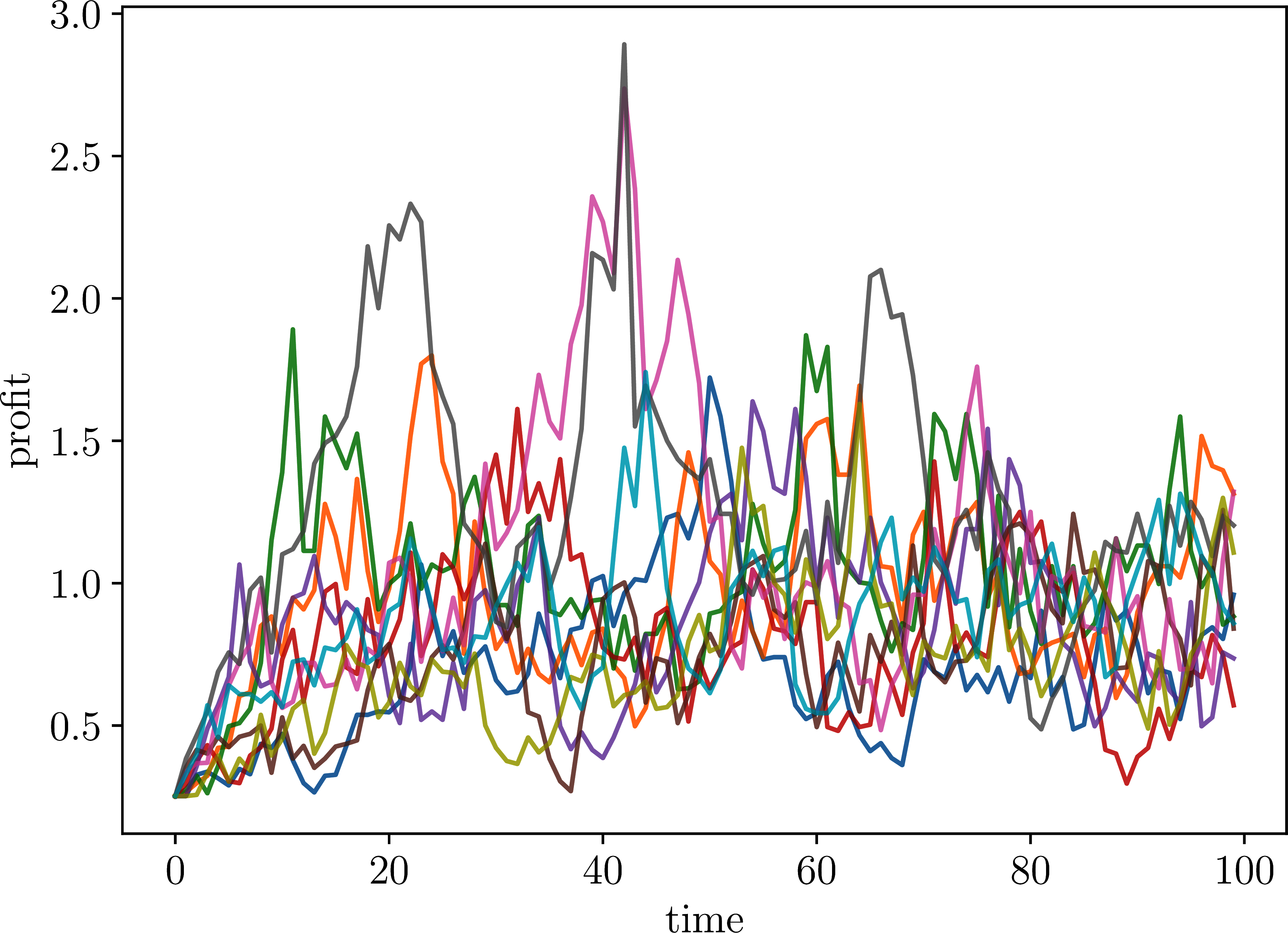
Figure 1.1:Sample profit paths
Under the Markov profits assumption, will depend on the current state , since knowing the state helps predict future profits. At the same time, the Markov assumption means that earlier values will not aid prediction once is known. This leads us to conjecture that for some fixed function . Inserting this conjecture into (1.1) and evaluating at yields
Defining , which is consistent with the operator-theoretic notation in Section A.5.4, we can rewrite (1.2) as . Using the fact that , and that the spectral radius of is (Lemma A.5.30), this equation has a unique solution for in whenever . The Neumann series lemma (Theorem A.4.10) tells us that the solution has the form

Figure 1.2:Value of the firm for different discount factors
Figure 1.2 plots over the state space for several choices of the discount factor . The environment is the same as the one underlying Figure 1.1. As increases, the firm places greater weight on future profits, resulting in higher valuations across all states.
Notice how the difficult problem of computing a stochastic process has been converted into the much easier problem of calculating .
1.1.1.2Control¶
So far our manager has had no choice to make. Let’s now give the manager the option to sell the firm to an outside buyer at the start of each period (before receiving current profits) for the fixed price . We will describe the manager’s decision with a binary policy function that selects between selling the firm in the current period, after observing the current state , and not selling — in which case the manager again faces the option to sell the firm at the beginning of the next period. The same policy is applied in every period, with being the current decision. Modifying (1.2) appropriately to a -dependent value function, we obtain the Bellman equation
where is the total value of the firm under the policy , conditional on state . If , then the manager sells at payoff and the process ends, so is the total value received. Otherwise , indicating no sale, profit is received, and the process continues, with discounted expected payoff . This is the second term in (1.4). In what follows we call the -value function.
Let be the set of all policies, defined as all -measurable functions mapping to . For each , let be the function defined recursively in (1.4). We can use the Neumann series lemma to show that is uniquely defined in . Alternatively, we can introduce the operator via
We call the policy operator defined by . In operator form it can be expressed as
Evidently, solves (1.4) if and only if is a fixed point of .
One easily shows that is contracting (see Section A.2.2.2 for the definition) on the complete space , where is the supremum norm, defined by for all . Indeed, for arbitrary ,
where the absolute value is applied pointwise (and the last inequality is by the triangle inequality for integrals — or, if you prefer, by the inequality for positive operators in Exercise A.5.17). From the last expression we get
Taking the supremum over the left-hand side, we find that is a contraction of modulus on . Hence, the -value function is the unique fixed point of in the candidate space .

Figure 1.3:Policies and their lifetime value functions
Figure 1.3 shows the value functions and for two possible policies and . The policies are shown on the left and the value functions are on the right. The environment is the same as Figure 1.2 with set to 0.96. The first policy sells when the state is below 1.0 and continues otherwise. The second policy oscillates between selling and continuing. Each value function is computed as the fixed point of the corresponding policy operator in . The horizontal dashed line indicates the sale price . In terms of value, policy is outperformed by everywhere on the state space.
Now let’s consider optimality. A policy is called optimal if for all and all . The value function , sometimes called the optimal value function, is defined by
Evidently is an optimal policy if and only if .
The problem of finding an optimal policy appears nontrivial, since is a large set whenever is large. Indeed, each is just an indicator function of a measurable set, so the cardinality of is the same as . However, it turns out that we can find, characterize, and compute optimal policies relatively easily, using the theory of dynamic programming. In particular, we can state the following result, which is proved below in Section 1.1.1.4.
Theorem 1.1.1 is a simple consequence of Richard Bellman’s (1920–1984) beautiful theory of dynamic programming Bellman, 1957. Equation (1.6) is called the Bellman equation.
The characterization in (1.7) has the following natural interpretation. The expression is the payoff (expected present value) for choosing to continue, receiving current profits, and then behaving optimally (since we are valuing future states with ). The best decision at is to continue if this is larger than , which is achieved by setting . Otherwise the manager should set and stop.
We shall repeatedly use a term related to Theorem 1.1.1. Thus, given , we will agree to say that is -greedy whenever
With this terminology, we can repeat the policy optimality characterization in Theorem 1.1.1 by saying that a policy is optimal if and only if it is -greedy. This idea is a cornerstone of our theory.
1.1.1.3The Bellman Operator¶
We noted above that a policy is optimal if and only if it is -greedy. This provides a direct avenue for computing optimal policies: First calculate and then take a -greedy policy. A straightforward way to approximate is to iterate on the Bellman operator, which, in the present setting, is the self-map on defined at by
In operator-theoretic notation, we write as . Evidently solves the Bellman equation if and only if is a fixed point of .
Note that is a contraction of modulus on . Indeed, fixing and applying the elementary bound
we get
The rest of the argument is identical to the one for contractivity of in Section 1.1.1.2.
From this and Theorem 1.1.1, we see that has a unique fixed point in and that the fixed point is the value function . Moreover, for any in , we have as . In other words, fixed point iteration (also called successive approximation) allows us to approximate arbitrarily well.

Figure 1.4:Optimal policy and value function
Figure 1.4 shows an approximate optimal policy and an approximation to the value function . The latter was computed by iterating with the Bellman operator from initial condition and monitoring for convergence (waiting for the step sizes to fall below some threshold). We then took the resulting function and computed a -greedy policy. We used the same parameters as in Figure 1.3. The optimal policy has a threshold structure: the manager sells the firm when the state is below a critical value and continues operating otherwise. The value function dominates the sale price everywhere, reflecting the value of the option to wait and sell later.
1.1.1.4Proving Theorem 1.1.1¶
In this book we will prove far more general results than Theorem 1.1.1. So providing an immediate proof of the theorem here is actually redundant and postpones our presentation of some sample applications. Nevertheless, we now sketch a short proof of Theorem 1.1.1, but alert readers that they can safely move on without digesting it now.
1.1.1.5How About More General Policies?¶
Up to now we have focused on stationary Markov policies, which, in our language, are measurable maps from to . Restricting our attention to such policies prevents the manager from making decisions based on a longer history of states and actions, or from changing policies at some date. We have also ignored the possibility that the manager might wish to randomize actions, meaning that the choice is a probability of selling, rather than a fixed selection from .
It turns out that focusing exclusively on stationary Markov policies is appropriate in the current setting. We show in Section 3.1.4 that allowing nonstationary policy choices cannot lead to higher expected present value, and that this result holds far more generally. Moreover, randomization cannot improve outcomes in this setting. For a proof in a similar environment, see our discussion of mixed strategies in Section 9.2.1.6 of Sargent & Stachurski (2025).
1.1.2Extensions¶
The theory stated so far is elegant and can be extended in some directions with relatively little effort. For example, we can ask the manager to control inventories, capital stocks, and the size and disposition of a labor force across tasks. The same fundamental ideas still govern optimality, and the same solution approaches still work.
But some extensions are more challenging and require moving beyond standard dynamic programs. We describe some of these challenges next.
1.1.2.1Beyond Constant Discount Rates¶
One restrictive assumption in Section 1.1.1 is that the discount factor is constant. In fact discount rates vary considerably. For example, market interest rates fluctuate substantially, responding to changes in monetary policy, inflation expectations, and risk premia. Interest rates charged to risky borrowers can fluctuate even more widely than benchmark rates. For a firm weighing the decision to continue operating versus exiting, the cost of capital at which future profits are discounted will have a substantial impact on optimal decisions. In practice, firms routinely incorporate time-varying discount rates into their strategic planning.
Figure 1.5 illustrates the extent of this variation using US data from the Federal Reserve. The top panel shows the federal funds rate, which transmits to firm financing costs through the credit channel. The bottom panel plots the real interest rate, computed as the 10-year Treasury yield minus twelve-month CPI inflation. Both sets of rates affect the intertemporal tradeoffs that firms face: when rates are high, future profits are discounted more heavily, reducing the present value of long-lived investments and making exit or disinvestment more attractive. Conversely, low or negative rates reduce the cost of waiting and encourage firms to invest, expand capacity, or delay exit from declining markets. The relative importance of real vs nominal rates varies across firms. The swings visible in Figure 1.5 underscore the issues with assuming a fixed discount factor when studying intertemporal choices of firms.

Figure 1.5:US nominal and real interest rates.
To accommodate dependence of discount factors on firm-specific or macroeconomic variables, we can specify that for some suitable function . Fortunately, this modification can be accommodated in the current setting. A discussion can be found in Section 4.2.1.3. But the associated theory can become more complicated when the controller’s actions affect state components that affect the discount factor. This happens, for example, in models of firms who face higher borrowing costs because they pursue high-risk strategies that involve occasionally running down their cash reserves. That makes the dynamic programming problem more challenging, particularly if we assume that interest rates are occasionally negative; such cases break contractivity properties of policy and Bellman operators. Optimality results for the finite state case can be found in Sargent & Stachurski (2025). We study more general cases in Chapter 6.
1.1.2.2Unbounded Rewards¶
Another—more technical—issue with our analysis in Section 1.1.1 is that is bounded. This directly embeds the problem in the space of bounded functions and pairs naturally with the supremum norm. The contraction and optimality proofs unfold smoothly when working in such an environment. But assuming that is bounded can be overly restrictive.
It turns out that we can drop the boundedness assumption without too much difficulty. One way is to assume instead that where and is the -weighted norm defined by . This approach is discussed in Section 7.2.2.2.
Another option is to embed the problem in the class of integrable functions for a suitable measure on . (For background see Section A.4.2.4.) For example, suppose that is a stationary distribution (see Section A.5.4.4) of the stochastic kernel and that . The policy operators then send into itself. Indeed, if and we fix , then , so is in when is -integrable. This is true by stationarity of --- see (i) of Lemma A.5.32 and the surrounding discussion. Moreover, is a contraction map on , as can be seen by integrating both sides of the bound with respect to and using (A.33) to obtain . One can also show that the Bellman operator is a contraction with respect to the norm on and then proceed to adapt proofs in Theorem 1.1.1.
Rather than provide all details here, we defer further discussion to Section 4.2.1.2.
1.1.3Beyond Risk Neutrality¶
A limitation of the preceding analysis is how it treats risk. We assumed that the manager wants to maximize the expected present value of cash flow generated by the firm across different strategies (policies). But what if the manager wants something else?
Canonical theories of firm behavior suggest that expected present value is the appropriate criterion. In complete and frictionless markets, a firm’s shareholders can hedge firm-specific risks by trading other securities, so the firm’s manager should not worry about that Modigliani & Miller, 1958Smith & Stulz, 1985. But maybe financial markets are incomplete and maybe shareholders lack enough information about risks or financial sophistication to develop optimal hedging strategies. Maybe managers’ incentives are not aligned with shareholders’ interests. Managers might be concerned about a firm’s survival and overweight downside risks relative to shareholders. Indeed, various studies offer evidence for such risk-averse decision-making within both small and large firms (see, e.g., Graham et al. (2013), Kerr et al. (2019), or Almeida et al. (2024)).
In this section we consider adjusting the manager’s problem to incorporate some of these considerations.
1.1.3.1Distributions of Rewards¶
Let’s return to our jump-off point for optimization, where we decided to seek a policy that solves for all . We know that is the expected lifetime value of policy given initial condition . As such, we can also write
where
Here is the date at which the firm is sold at price (with convention , so that if the firm is never sold). Evidently is a random payoff, depending on the policy and the random path . The random variable depends on the initial state but we have chosen to suppress this in the notation.
The left-hand subfigure in Figure 1.6 shows the distribution of , lifetime value under the optimal policy , computed by fixing an initial condition , simulating 100,000 profit paths from a given initial state, and then computing the discounted payoff along each path. (Parameter values were the same as in Figure 1.3.) The mean of the distribution is , which is also . The policy is regarded as optimal because the mean of the distribution is larger than the mean of under any other policy, and given any other initial condition . The right-hand subfigure compares with , where is the policy that never sells.

Figure 1.6:Distributions of the random payoff defined in (1.11).
Let’s consider these distributions from the perspective of firm managers when markets are not frictionless, and information is not perfect. In this case, as discussed at the start of Section 1.1.3, managers care about more than just the mean of these distributions. While the mean will surely be of interest, these managers are likely to also care about factors such as variance, upside risk and downside risk. Let’s now consider how we might insert preferences over such factors into our model.
1.1.3.2Distributional Dynamic Programming¶
Some researchers have begun to construct a theory of “distributional dynamic programming” where the core idea is to track the distribution of the payoff across policies and initial conditions. In our context, this means choosing so that has an “optimal” distribution. For example, a manager might want a distribution with a relatively high mean and low downside risk. Bellemare et al. (2023) show that, for a relatively broad class of dynamic programming problems, a distributional version of the Bellman equation can be constructed, where the left- and right-hand sides of the Bellman equation are both distributions. We formalize this idea within the abstract dynamic programming framework in Section 2.3.4.
In practice, the theory of distributional dynamic programming is constrained by the fact that there is no natural extension of the idea of a greedy policy to the setting of distributional Bellman equations. As such, we focus on environments where agents are able to specify loss or reward functions over distributions. The next few sections investigate such cases, while still preserving concern for tail properties and additional moments beyond the mean.
1.1.3.3Mean-Variance Analysis¶
Let be a random payoff that we want to evaluate. Mean-variance analysis proposes the criterion , where parameterizes risk-aversion. In the context of our manager’s problem, the mean-variance criterion tells us to solve
Assuming that the initial condition is , the first term is just . The second term is harder to calculate but its role is clear: it downweights policies that generate high variance payoffs, with the extent of downweighting depending on the size of . More risk averse managers will use larger values of and their preferred policies will deviate more from what we previously defined to be optimal—that is, the policy that solves for all .
1.1.3.4Alternatives to Mean-Variance¶
The mean-variance criterion is not the only way to formulate concerns about risk. An alternative formulation solves
Here again denotes the mathematical expectation with respect to the probability distribution of the random payoff, which the decision maker is assumed to know. The map is called an entropic certainty equivalent. The parameter parameterizes risk aversion. When , the decision maker values below . We say that risk aversion is higher when is larger. An introduction to these ideas is provided in Section 7.2.2 of Sargent & Stachurski (2025).
The entropic criterion is attractive for several reasons. One is that, with sufficiently many finite moments, a Taylor expansion produces
where is the -th cumulant
This tells us that, with positive , the agent likes a high mean, dislikes variance, likes positive skewness (right tails), dislikes kurtosis (fat tails), etc. When higher moments are small we get
which connects us back to mean-variance analysis. The approximation above becomes exact when is normally distributed.
In addition, the entropic criterion can be regarded as an indirect utility function that emerges from a setting in which the manager doubts its probability model for . In particular, let denote the manager’s baseline model probability measure for the payoff . Then it can be shown that
where the minimum is over probability measures absolutely continuous with respect to and is a Kullback–Leibler statistical divergence for measuring the discrepancy between two probability distributions. Here the parameter controls the size of a penalty that the minimizer pays for distorting relative to baseline probability model ; larger ’s allow the minimizing “player” who chooses to range over a larger set of alternative models. Such an analysis connects entropic preferences to robust control and ambiguity aversion and will be discussed in Chapter 7.
The entropic criterion is a special case of a more general objective
where is a given function. Typically is concave, as is the case for when . Another example is the Kreps–Porteus expectation, which is obtained by setting .
A third option for inserting preferences over risk is to evaluate
where is a given constant. This objective is called value-at-risk and can be understood as the smallest cash injection such that the probability of a net loss is no more than . Intuitively, if has more downside risk, then increases, as more cash is needed to keep the loss probability below the threshold. Thus, a manager seeking a low-risk policy might look to minimize , or, equivalently, to solve .
Value-at-risk became industry standard in the 1990s, partly due to popularization through RiskMetrics, a risk management framework developed at J.P. Morgan. It has spawned a variety of alternatives and extensions, including conditional value-at-risk, entropic value-at-risk and relativistic value-at-risk. We will meet some of these ideas again in Chapter 7.
1.1.3.5Difficulties¶
While the risk-management concepts discussed above are all sensible, they complicate solving for an optimal policy because they make the objective be nonlinear. For example, consider the mean-variance problem (1.12), which we can write as
The function is nonlinear due to the presence of the variance term, and this nonlinearity prevents us from passing through the sum and thereby deriving a recursive expression for the value of a strategy similar to (1.4). To see this, recall the role that linearity of the expectations operator played in our derivation of representation (1.2).
Bellman’s dynamic programming theory requires having a recursive representation for valuations under alternative strategies. Without that, numerical strategies for solving global optimization problems like can be poorly behaved, very high dimensional, and virtually inaccessible to the theory of dynamic programming.
Even worse, there is an important sense in which the criterion of maximizing over is no longer the right one, since there is no guarantee that the best strategy for the manager is to choose a stationary Markov policy and apply it in every period. For example, in our new nonlinear setting, it might be optimal for the manager to apply a given policy in the first period and a second policy in all periods thereafter (see, e.g., Section 5 of Bäuerle & Jaśkiewicz (2024)). While this might still seem feasible—we need only to compute one more policy— time inconsistency arises. The manager must be committed to switching to in the second period, since re-optimization would lead to choosing again.
Unfortunately none of the alternatives to mean-variance analysis discussed in Section 1.1.3.4 offer a way out of the problem described above, since nonlinearity in the objective again prevents construction of a recursive representation. As with mean-variance, this lack of recursivity requires deploying dynamic programs in new ways.[1]
1.1.3.6Back to Recursion¶
In Section 1.1.3.5, we saw how nonlinearity intended to capture risk-preferences led to a breakdown of dynamic programming theory. Fortunately, there is a way to inject nonlinearity and risk-preferences into the manager’s problem without breaking recursivity and hence access to the core ideas of dynamic programming. The idea is to stop trying to apply risk-preferences directly to the net present value sum and instead apply them period-by-period. We can do this by starting with the risk-neutral recursive valuation (1.4) and modifying it to
where is a possibly nonlinear operator from to itself. For example, using the notation , we can set
to implement the mean-variance criterion, or
for entropic risk preferences.
This alternative approach to inserting risk preferences into the manager’s problem is somewhat less intuitive than the direct approach that we reviewed in Section 1.1.3.3 and Section 1.1.3.4. In addition, it introduces a new problem: is actually well-defined by the nonlinear functional equation (1.14)? On the other hand, it offers a major advantage: provided we can show that is in fact well-defined — which is a problem for fixed point theory — the valuations are recursive by construction. Exploiting this fact, we can extend Bellman’s original theory in very natural ways. This is one of the main subjects of this book.
We will attack this problem in stages, beginning with an abstract recursive setup in Chapter 2. The setup will be recursive in the sense that each valuation will be represented as the fixed point of a possibly nonlinear policy operator . Our approach will then be to rewrite Bellman’s optimality theory in this abstract setting and seek properties on the policy operators under which the main results go through. At the end of this process we will connect back to the applications from this chapter.
Before progressing to this abstract theory, we look at some other concrete examples, beginning with finite state Markov decision processes.
1.2Finite MDPs¶
Finite state Markov decision processes (MDPs) form the foundations of many quantitative modeling and reinforcement learning routines, as well as providing a benchmark setting for dynamic programming theory (see, e.g., Puterman (2005) or Chapter 5 of Sargent & Stachurski (2025)). In this section we introduce finite state MDPs and some extensions. As was the case for the firm problem considered in Section 1.1, our main objective is to introduce a class of dynamic programming problems that will motivate the abstract theory starting in Chapter 2.
While the presentation below is self-contained, readers wanting a slower pace and more examples might prefer to begin with Chapter 5 of Sargent & Stachurski (2025).
1.2.1Theory¶
In this section we introduce the finite MDP framework and state core optimality results—the Bellman equation and the greedy policy characterization of optimal policies. We then present three fundamental algorithms: value function iteration, Howard policy iteration, and optimistic policy iteration. We illustrate the main ideas with an application to firm cash management.
1.2.1.1The Discrete Time Model¶
A finite state Markov decision process (finite MDP) consists of
a finite set called the state space,
a finite set called the action space,
and a tuple , where
is a nonempty correspondence from to , which in turn defines the feasible state-action pairs
a reward function ,
a discount factor in , and
a stochastic kernel from to , which provides transition probabilities for the next period state given current state and action.
Since is a stochastic kernel, it satisfies for all .
Given an initial condition , the objective is to maximize the expected discounted sum
Here takes values in and takes values in . After observing state , the controller chooses action from the feasible set and the new state is drawn from the distribution . The constant is a discount factor and is a reward function. In maximizing this objective, the action sequence must also satisfy an information constraint: Each is required to be measurable with respect to the -algebra generated by . Thus, the controller can use information from the past and present but not the future.
As was the case for the firm problem in Section 1.1, it turns out that actions depending on all of are no better than actions that depend only on . We will show this formally in Section 3.1.4. As a result, we focus on stationary Markov policies, where the same deterministic function of the state is applied at every point in time. We call such stationary Markov policies feasible policies, the set of which is given by
For each , we set
It follows from our assumptions on that is a stochastic matrix, meaning that and all rows sum to one. By choosing a policy , the controller determines a reward function on the state and Markov dynamics for the state process. Following notation in Section A.5.4, we write
interpreting this value as the expectation of when and the controller uses policy .
The lifetime value of given is
when is a Markov chain generated by with initial condition . Since , the function can be expressed pointwise on as
where is the identity map on , the set of real-valued functions on . This representation on the right-hand side is essentially the same as (1.3). In particular, the second equality comes from the Neumann series lemma. See also Puterman (2005), Theorem 6.1.1, or Chapter 5 of Sargent & Stachurski (2025).
The policy operator associated with given for the finite MDP model takes the form
1.2.1.2Core Optimality Results¶
The definition of the value function is the same as that for the firm problem in Section 1.1.1.2:
Similarly, a policy is called optimal if for all .
The Bellman equation for this problem is
This is a functional equation that restricts . The Bellman operator is given by
By construction, solves the Bellman equation if and only if is a fixed point of the Bellman operator. In the next exercise, . Corollary A.5.13 may be helpful.
We say that is -greedy if
We can now state the following optimality result, which naturally mirrors our previous result for the firm problem (Theorem 1.1.1).
A full proof of Theorem 1.2.1 can be found in Chapter 5 of Sargent & Stachurski (2025). The proof is almost identical to that of Theorem 1.1.1, which we provided for the firm problem. We will also prove Theorem 1.2.1 in Section 2.3.3.2, as a special case of far more general results.
The next obvious step is to use the results in Theorem 1.2.1 to compute optimal policies. Next we consider algorithms designed for this purpose.
1.2.1.3Algorithms¶
The three most important algorithms for solving dynamic programming problems are value function iteration (VFI), Howard policy iteration, and optimistic policy iteration (OPI). In the present setting, they take the forms of Algorithm 1.2.1, Algorithm 1.2.2, and Algorithm 1.2.3.
VFI amounts to iterating times with from some initial condition (where is determined by a fixed tolerance level for error), producing an approximation to , and then computing a -greedy policy . This idea is natural, given that -greedy policies are optimal, since is a contraction mapping and is the unique fixed point (so that is close to ).
In HPI, one begins with a guess of the optimal policy and then iterates between computing the lifetime value of that policy (as given in (1.18)) and the corresponding greedy policy. In fact HPI is equivalent to Newton fixed point iteration applied to the Bellman operator. See, for example, Chapter 5 of Sargent & Stachurski (2025).
OPI can be thought of as a “convex combination” of VFI and HPI. Instead of computing the lifetime value of current policy guess , one computes instead , which is an approximation to (since is a contraction with fixed point ). There are two edge cases:
If is large, this approximation is tight, and hence OPI is close to HPI.
If , OPI reduces to VFI.
OPI usually outperforms both VFI and HPI for some intermediate values of . Further intuition and discussion is provided in Chapter 5 of Sargent & Stachurski (2025).
For the finite MDP setting, we can state the following results:
We shall prove these results after we discuss convergence of these algorithms in a general setting in Section 2.2.1.
1.2.1.4Solving MDPs via Linear Programming¶
Many dynamic programs can be formulated as linear programs. We illustrate with finite MDPs. To do so, we recall that a typical linear program has the form
Here is a vector in , the term is the inner product , is a matrix with columns and is a vector with the same length as . (Other LP formulations replace the inequality with or , or a mix of inequality and equality constraints. Standard LP algorithms and theory can be applied to all of these cases.)
To place the finite state MDP from Section 1.2.1.1 into this framework, we begin by setting
where is the Bellman operator. Recalling that represents the value function, we have the following result:
Now let be an everywhere positive element of and consider the linear program
Here and the minimization is over all that satisfy the stated constraint. As before, we require that is everywhere positive. Evidently (1.24) takes the form of (1.23) after suitable assignment of indices. Thus, (1.24) is a linear program. This leads us to
Proposition 1.2.4 implies that we can compute the value function and hence solve the MDP using linear programming techniques. The LP approach is useful for many models, such as those that incorporate additional linear constraints, e.g., bounds on expected rewards and resources, that are difficult to handle with iterative methods. On the other hand, the number of constraints in (1.24) equals , which can be large, so iterative methods are still often preferred. See Section 1.6 for references and further discussion.
1.2.1.5Example: Cash Management¶
To illustrate finite MDPs in a concrete setting, we now study a cash management problem faced by a firm that must balance cash holdings against returns from securities. This problem dates back to the work of Baumol (1952) and Tobin (1956), who developed inventory-theoretic models of the demand for money. In their models, the decision maker decides how much cash to hold versus interest-bearing assets, balancing the opportunity cost of holding idle cash against the transaction costs of converting assets to cash.
The decision maker manages fixed total wealth , which is divided between cash holdings and securities . Each period, the decision maker experiences random portfolio shocks and must decide whether to transfer funds between cash and securities. The decision maker earns returns on securities but pays transaction costs for transfers and faces penalties for insufficient cash. (Assuming that wealth is fixed allows us to get by tracking only , and not .)
The state space for cash is . At state , the feasible actions are transfers satisfying . Thus, . Portfolio shocks (cash payments, equity payments, debt restructuring, etc.) are IID, written as , and take values in a set with probability mass function . Transition probabilities are determined by the next-period state
where the max and min keep in the state space. The transition probabilities are, therefore,
Flow profits are given by
Here is the rate of return on securities, is a fixed transaction cost, is a proportional transaction cost, and is a penalty for insufficient cash (in this case, when ). To fit the problem into the MDP framework, we take expectations of flow profits to get the period reward
Future payoffs are discounted using discount factor .
The set of feasible policies is defined from in the usual way (see (1.16)). The lifetime value of any given policy can be computed from , as discussed in Section 1.2.1.1. Figure 1.7 illustrates by using this formula to compute -value functions for two policies. The first is a “do nothing” policy that sets for all states. The second is a target policy that always moves toward a fixed target cash level. As we will see, both policies are suboptimal.

Figure 1.7:Value of a do-nothing policy () and a target policy ()
Next let’s solve for an approximately optimal policy using VFI, as described in Algorithm 1.2.1. Figure 1.8 shows the resulting (approximately) optimal policy and value function. The policy shows the optimal transfer amount as a function of current cash holdings, while the value function shows the lifetime value of following the optimal policy. Here we set total wealth , return on securities , fixed transaction cost , proportional transaction cost , penalty for insufficient cash , and . The cash flow shocks are uniformly distributed on .
The optimal policy recommends that when cash holdings are low, the decision maker should move funds from securities to cash (take a positive action), and when cash holdings are high, move funds from cash to securities (a negative action). The value function declines for large cash balances because wealth is fixed and hence high cash balances mean low holdings of securities and reduced returns.

Figure 1.8:Optimal policy and value function for the cash management problem
Figure 1.9 shows iterates for the policy sequence and the value sequence under the HPI algorithm. The initial policy is a do-nothing policy. As mentioned in Theorem 1.2.2, HPI converges in a finite number of iterations. Here it converges in 5 iterations, so the last policy is the exact optimal policy (modulo floating point arithmetic), and the last -value function is the value function . The gap between the first value function associated with the do-nothing policy, and the final value function associated with the optimal policy, is value of active cash management. This gap is largest at extreme cash levels, where the do-nothing policy either leaves the firm exposed to cash shortfalls or forgoes returns on securities.

Figure 1.9:Iterating with HPI from the do-nothing policy
Figure 1.10 shows a simulated time path for cash and optimal cash transfers under the optimal policy. Cash is held unchanged in many time periods as a result of transaction costs.

Figure 1.10:Time path for cash and actions under the optimal policy
1.2.2Continuous Time¶
In this section we modify our finite state MDP model from Section 1.2.1.1 to a continuous time setting. With appropriate manipulations, our continuous time model can be embedded in the discrete time framework.
1.2.2.1Primitives and Values¶
As in the discrete time case, and are finite sets, while the controller is constrained by a feasible correspondence from to . The definitions of , , and are unchanged. Discounting is determined by a constant , referred to as the discount rate, while transitions are driven by an intensity kernel from to , which is a map from to that satisfies
Informally, over the short interval from to , the controller receives instantaneous reward and the state transitions to state with probability .
For a fixed , we obtain an intensity operator (i.e., an infinitesimal generator)
that determines a continuous time Markov chain with transition probabilities given by for all . In particular,
(For background see Chapter 10 of Sargent & Stachurski (2025).) Continuing to define , the lifetime value of following starting from state is
(Passing the expectation through the integral can be justified by Fubini’s theorem.) Using , we can rewrite as
The two representations for are the continuous time analogs of the discrete-time representations given in (1.18). A proof of the second equality is given in §10.2 of Sargent & Stachurski (2025).
(Readers familiar with semigroup theory will recognize the two representations in (1.30) as alternative expressions for the resolvent of the semigroup – see, for example, Engel & Nagel (2006), Theorem 1.10.)
1.2.2.2Uniformization¶
We can use the ADP framework to reformulate (1.30) by making be the fixed point of an order preserving policy operator. This process is called uniformization. The first step is to set
Then set
As in the discrete time case, for each , define and according to
From Exercise 1.2.5, we see that is the unique fixed point in of the policy operator
1.2.2.3Optimality¶
Since (1.33) becomes (1.19) after replacing with , we can apply the discrete time MDP theory in Section 1.2. The Bellman equation becomes
The optimality properties in Theorem 1.2.1 hold and, by Theorem 1.2.2, VFI, OPI and HPI all converge. With denoting the value function, a policy is optimal if and only if
The next two exercises unpack these equations and conditions to recover our original continuous time formulation.
Equation (1.35) connects the exposition above to the traditional theory of continuous time MDPs (see, e.g., Guo & Hernández-Lerma (2009)). It is sometimes called the Hamilton–Jacobi–Bellman (HJB) equation, although that name is more commonly used when the state process is a diffusion.
As in Exercise 1.2.6, it can be shown that is -greedy if and only if
1.2.2.4Example: Service Rate Control¶
Here we study a queue system where a firm controls service rates to maximize profit. The firm operates a service facility with finite capacity . Customers arrive according to a Poisson process with rate . The state represents the number of customers currently waiting for service. The firm can control the service rate by selecting from a finite set of actions . Each action corresponds to a service rate . Higher service rates allow faster customer processing but incur greater operating costs.
The intensity kernel associated with this problem is
When , we set in order to ensure at each .
All choices of are feasible, so for all . The instantaneous profit rate is
where is revenue per customer served, is holding cost per customer per unit time, and is the service cost rate for action . The first term represents revenue from serving customers, the second term captures the cost of customers waiting in the queue, and the third term is the cost of operating at service rate . The firm’s objective is to maximize expected discounted profit flow , where is the discount rate.
We solve the problem using the uniformization technique discussed in Section 1.2.2.2. The first step is to calculate the uniformization rate . Here
(only arrivals when empty),
for (both arrivals and departures), and
(only departures at capacity).
Hence
Thus, following the specifications in Section 1.2.2.2, we set
We then compute the optimal policy using VFI based on the Bellman equation (1.34).
Figure 1.11 shows the optimal policy and value function for a system with customers, arrival rate , service rates , revenue , holding cost , service costs , and discount rate . When the queue is empty, the firm uses the lowest service rate to minimize operating costs. As the queue length increases, the firm gradually raises the service rate to balance the increasing holding costs against service costs. The value function increases initially as queue length grows (reflecting the value of serving customers) but eventually decreases as holding costs dominate.

Figure 1.11:Optimal service rate policy and value function for the queue system
1.2.3Extensions¶
In this section we discuss extensions of the MDP framework that parallel those for the firm problem. These include nonlinear objectives including mean-variance and risk-sensitive preferences. As before, we find that nonlinearity forecloses a recursive structure, motivating resort to period-by-period reformulations that restore tractability. We also introduce ambiguity, where the controller faces uncertainty about transition probabilities.
1.2.3.1Nonlinear Criteria¶
Some extensions to the firm problem discussed in Section 1.1.2 have counterparts here. For example, we discussed maximization problems of the form
and is a nonlinear real-valued function. One example was given in (1.13), where was the mean-variance map in (1.12). In other examples, emerges from value-at-risk, conditional value-at-risk, risk sensitivity, or a desire for robustness.
There are obvious parallels for the MDP model we introduced in Section 1.2.1. We simply take the criterion from (1.36) and modify it to
Here is a Markov chain generated by with fixed initial condition and is again, some given real-valued function. As before, we can choose to inject concern for mean-variance trade-offs, value-at-risk, conditional value-at-risk, risk sensitivity and a desire for robustness.
1.2.3.2Back to Recursions¶
In Section 1.1.3.5 we discussed how optimization problems of the form (1.36) can be troublesome. The lack of a recursive structure prevents us from using Bellman machinery. The result is that we are left without a clear path to optimization, as well as the loss of time-consistency. Not surprisingly, all of these difficulties remain present when we switch to the MDP version in (1.37).
For the most part, theorists have responded in ways similar to ones discussed for the firm problem in Section 1.1.3.6, where recursive structure is enforced by applying nonlinear criteria period-by-period, rather than applying them directly to the sum representing lifetime value. For example, we can modify the policy operator (1.5) to
where, for each , the map is a given nonlinear operator. For example, by setting
we switch the MDP problem to entropic risk preferences.
As for the firm problem, this alternative approach to inserting risk preferences is less intuitive than the direct approach in (1.37) and raises a question: when is well-defined by the nonlinear functional equation (1.38)? In addition, the formulation in (1.38) offers the advantage that valuations are recursive by construction. This allows us to apply solution methods that extend Bellman’s original theory in natural ways. We explore these ideas in the remainder of the text, beginning with the abstract recursive setup in Chapter 2.
1.2.3.3Ambiguity¶
The MDP framework has been extended to include a decision maker’s concerns about misspecification of the probability distribution. For example, consider the cash management problem from Section 1.2.1.5. Applying the definitions of the profit function and the transition function from that section, the risk-neutral problem can be written as
where obeys for all . We subscript expectation with to emphasize the fact that the mathematical expectation over is taken with respect to distribution .
Suppose now that the manager doesn’t know but does know that belongs to a set of possible distributions . This is how the decision maker expresses ambiguity about the probability law that governs . If we were to say to the decision maker to put a subjective probability distribution over , the decision maker would decline to do so.
The decision maker proceeds in the spirit of Abraham Wald Wald (1950) by assuming only that he knows a set of possible models. To do this, he replaces (1.39) with
By using this criterion, the manager seeks a decision rule that works well enough no matter which probability distribution governs .
A recursive structure is absent from criterion (1.40). One way out of this difficulty is to make our decision maker express model ambiguity in a way that is more susceptible to a recursive formulation. For example, we could ascribe our decision maker a value function that solves the following Bellman equation:
As we will see in Section 7.3.3, this kind of specification puts dynamic programming theory back in business.
1.3Optimal Savings¶
This section presents an optimal savings problem (also called the optimal consumption problem and the income fluctuation problem). This problem is a building block for many economic models. It features a basic intertemporal trade-off from consuming now or later. This trade-off can be solved by dynamic programming.
Unlike the finite state problems above, the optimal savings model has a continuous state space, as well as a continuous action space. We define policies, policy operators, and lifetime values and state the key optimality results. We then look at extensions to Epstein–Zin preferences.
1.3.1Policies and Decisions¶
In an optimal savings problem (sometimes called an “income fluctuation problem”), a household seeks to maximize
The constraints in (1.42) are required to hold for all , and an initial condition is taken as given. The utility function maps current consumption into a utility value (loosely speaking, a measure of satisfaction), is a discount factor indicating impatience, and is a gross rate of return on assets. The variable represents wealth at time , while is labor income. To keep the model simple, we assume is IID with common distribution , the set of distributions (i.e., Borel probability measures) on .
(We study more general settings later.)
The variable is the state of the dynamic program, while is the action. Figure 1.12 shows the timing for the optimal savings problem. After observing , the household chooses and hence . Then labor income is realized and the state updates to . The process then repeats.

Figure 1.12:Timing for the optimal savings problem
In maximization problem (1.42) there is another constraint: can depend only on information available at time . Formally, current consumption must be a (deterministic) Borel measurable function of shocks, states, and actions observed up to and including time . Thus, the current action cannot depend on future values such as or . A mapping from the history of the state and the shocks into the current action is called a policy function.[2]
The infinite horizon, IID -process, time-invariant structure of the optimal savings problem lets us focus on policies that make current consumption be a deterministic function of the current state . (We will prove this later and discover how it depends on the IID-nature of the process.)
We impose the following simplifying conditions:
In a slight abuse of notation, we use to represent the density of labor income as well as the corresponding distribution (i.e., Borel probability measure on ). Thus, in the integrals below, and have the same meaning.
1.3.1.1Lifetime Value¶
In this setting, a stationary Markov policy is a Borel measurable map from to itself. Here we refer to stationary Markov policies more simply as policies. We call a policy feasible if for all , so that the consumption response obeys the inequalities in (1.42). Let denote the set of all feasible policies. We seek that maximizes expected lifetime value. For given and initial condition , expected lifetime value is
for all and starts at . Below, we refer to as the -value function.
It is helpful to represent as a policy operator for :
This policy operator is a continuous state analog of the finite MDP policy operator we saw in (1.19). It acts on functions , where
Recall that is a Banach space (see Section A.4.2) with supremum norm .
Policy operators are useful because is a fixed point of if and only if it equals the -value function. Thus, the fixed point of characterizes the lifetime value of . This is a consequence of the following lemma.
Incidentally, one can use the law of iterated expectations to prove that the -value function is a fixed point of . Write
Letting be the expectation conditional on , applying the law of iterated expectations implies
Expanding the last expression yields
Thus, is a fixed point of .
1.3.1.2Lifetime Values as Limits¶
In the previous section we learned that fixed points of policy operators represent lifetime value. What do finite iterates of policy operators represent? Fixing and inspecting the definition of (see (1.44)) indicates that represents the reward received from using policy for one period, when is initial wealth and the function is used to evaluate the reward from wealth in the second period.
We can lengthen the horizon by iterating with while keeping the terminal value function fixed. Choosing and using the expression for in (1.45), we get
The expression on the right is the value of using policy for periods and then receiving a reward for terminal wealth determined by the function . Thus, it is the finite horizon value of following under this terminal condition.
It seems plausible that the infinite-horizon lifetime value of a policy could equal the limit of finite horizon values, so that
Lemma 1.3.1 assures us that this is true: since is globally stable on with unique fixed point , the limit in (1.49) exists and equals , independent of the terminal condition .
Figure 1.13 shows two arbitrarily chosen feasible policies and their lifetime values when , , , and when and is standard normal. The lifetime values were computed via (1.49).

Figure 1.13:Randomly chosen policies and their lifetime values
1.3.2Optimality¶
The value function for the optimal savings model is
Under Assumption 1.3.1 the supremum is always well defined in , since and hence is bounded by some constant , implying that, for any and ,
A policy is called optimal if ; that is, if following the policy from every initial state leads to the largest possible lifetime value attainable from .
The set of feasible policies lies in an infinite-dimensional function space, so we cannot find an optimal policy by exhaustive search. We want a systematic and efficient search procedure. Following the techniques we used for the firm management problem in Section 1.1, our approach will be to (a) set up a Bellman equation to help us assign maximal lifetime values to states, and (b) solve for a greedy policy with respect to this maximizing function.
1.3.2.1Bellman’s Method¶
Fix . In the present setting, a policy will be called -greedy if
A -greedy policy uses to value next-period states and then chooses consumption optimally to trade off current utility against expected discounted future value associated with the implied level of savings. The following statements are both true:
Computing -greedy policies is typically much easier than computing optimal policies, since we are only solving a two-period problem.
Computing -greedy policies can be equivalent to computing optimal policies, given the right choice of .
What is the right choice of ? A natural candidate is the value function, since the value function tells us the maximal reward from alternative states. We explain this in more detail in Section 1.3.2.2. In that same section, we will also use the fact that the value function satisfies an important functional equation, which we now describe.
We say that satisfies the Bellman equation for the optimal savings problem if
Stating that solves the Bellman equation is equivalent to stating that is a fixed point of the Bellman operator that maps a value function into a value function defined by
The next lemma discusses properties of greedy policies and the Bellman operator.
Since is a Banach space, the contraction property in Exercise 1.3.2 implies that is globally stable on . (See Section A.2.2.2 for details).
1.3.2.2DP Results for Optimal Savings¶
Dynamic programming theory tells us that, under Assumption 1.3.1,
at least one optimal policy exists,
the value function is the unique solution to the Bellman equation in , and
a policy is optimal if and only if it is -greedy.
A direct proof of (i)–(iii) can be found in Stokey & Lucas (1989), Stachurski (2022) and numerous other sources. The proofs heavily exploit the fact that the Bellman operator is a contraction mapping (as discussed in Exercise 1.3.2). We skip proofs for now, noting that they will be special cases of proofs we shall provide in Section 3.2.2.
Let’s review what we’ve found so far. We started with one optimization problem—choosing an optimal consumption path to maximize expected discounted lifetime utility—and ended up with another one—finding a greedy policy from the value function. Are we actually better off? The answer is: yes! Finding a greedy policy involves solving a scalar optimization problem performed for each state , whereas as our previous optimization problem was infinite dimensional. High dimensionality is the mountain we must climb in all hard optimization problems and here we have used the recursive structure inherent in the problem to map a route up to the top.
Of course this claim that we are better off is contingent on us being able to learn what the value function is, so that we can compute -greedy policies—or at least some reasonable approximation. We discuss this topic next.
Figure 1.14 shows an approximation of the optimal policy and the value function , both computed by OPI, for the same version of the optimal savings problem used in Figure 1.13. In this case we set .

Figure 1.14:Approximating the optimal policy and value function via OPI
1.3.2.3Special Case: No Labor Income¶
Let’s quickly look at a version of the savings model where it’s possible to get an analytical solution for the optimal policy and the value function. We will use this solution to help us investigate the role of parameters and, through this process, consider the need for extensions to the basic optimal savings model.
To obtain an analytical solution, we set and assume that the utility function has the CRRA form
The conditions of the preceding discussion are not satisfied, since is not bounded on and may take the value . We assume instead that . This turns out to be sufficient to ensure finite lifetime values when consumption choices are positive:
For this CRRA problem, the optimal consumption policy is linear in . That is,
Let’s verify this claim and also seek the value of the constant . In doing so, we first observe that if (1.55) holds, then
and hence the value function satisfies
Our conjecture is that the linear policy satisfies the Bellman equation with the value function as given above. Under this conjecture, the Bellman equation becomes
Taking the derivative with respect to yields the first-order condition
It then follows that . Substituting the optimal policy into this equality gives
Now solving the above equality for yields
In this connection, given any initial wealth , the value function becomes
It is not difficult to verify that solves the Bellman equation (1.56) for any .
The parameter governs the curvature of the utility function and hence preferences about consumption smoothing. To see this, observe that consumption at time is , so the consumption growth factor is . When is large, the utility function has high curvature and the agent dislikes variation in consumption across time. Conversely, when is small, the agent is more tolerant of consumption variation, leading to steeper paths. Figure 1.15 illustrates these effects for and .

Figure 1.15:Optimal consumption paths under CRRA utility for different values of .
1.3.3Epstein–Zin Preferences¶
There are a number of issues and limitations associated with the basic optimal savings model we have discussed so far. Moreover, these limitations tend to bind more often as we move towards quantitative analysis and interesting research applications. In this section we discuss issues related to risk and intertemporal substitution. This discussion will motivate us to introduce Epstein–Zin preferences, which are a particularly popular specification of intertemporal preferences in economics and finance.
1.3.3.1Risk vs EIS¶
One issue is that, under the model considered so far, the curvature of the utility function simultaneously governs both risk aversion (e.g., a more strongly concave utility function indicates stronger aversion to risk) and willingness to substitute consumption across time (as we saw in Figure 1.15, where increasing led to flatter consumption paths). Willingness to substitute consumption is usually measured by the elasticity of intertemporal substitution (EIS), which, for the CRRA utility function is . Larger pushes down the EIS, indicating preference for smooth consumption over time.
The fact that utility curvature controls both risk preferences and the EIS binds attitudes toward uncertainty together with attitudes toward intertemporal substitution. Researchers have found that to explain various macro-finance patterns, it helps to unbind them and allow separate parameters to describe these two attitudes. For example, matching observed equity premia using standard asset pricing models requires high risk aversion, but high under CRRA implies a small EIS, which creates other difficulties including what is called a risk-free rate puzzle (see, e.g., Chapter 13 of Ljungqvist & Sargent (2018)).
1.3.3.2EZ Preferences¶
Epstein–Zin preferences Epstein & Zin, 1989Weil, 1990 play a big role in many macro-finance models. Under these preferences, the Bellman equation (1.52) from the standard optimal savings model becomes
where is the EIS and is the coefficient of relative risk aversion. The inner expectation applies risk adjustment to future value via the Kreps–Porteus expectation, which we met earlier in Section 1.1.3.4. The outer CES aggregator governs intertemporal substitution. The policy operator (1.44) now becomes
for any feasible policy . Figure 1.16 shows two arbitrarily chosen policies and their lifetime values under Epstein–Zin preferences, using the same income process as in Figure 1.13. The -value functions are now computed by iterating on our new version of . Parameters are , , (risk aversion), and (EIS).

Figure 1.16:Policies and lifetime values under Epstein–Zin preferences
Figure 1.17 shows the optimal policy and value function under Epstein–Zin preferences, computed via OPI. Compared to the standard expected utility case in Figure 1.14, the optimal consumption policy is qualitatively similar—increasing and concave in wealth—but the value function differs in interpretation and scale. With , the agent exhibits preference for early resolution of uncertainty, which affects how future risk is valued.

Figure 1.17:Optimal policy and value function under Epstein–Zin preferences
Figure 1.18 explores how risk aversion affects optimal consumption. The figure shows optimal policies for , holding the EIS fixed at . Higher risk aversion leads to more precautionary saving: at each wealth level, the agent consumes less and saves more as increases. Values of around 10–20 are common in the long-run risk literature Bansal & Yaron, 2004, where high risk aversion is needed to match observed asset pricing moments.

Figure 1.18:Optimal consumption by risk aversion
1.3.3.3Optimization Theory¶
While the preceding analysis illustrates the potential usefulness of Epstein–Zin preferences, it puts us on shaky ground technically. For example, optimality properties of the ordinary optimal savings model in Section 1.3.2.2 depend on contractivity of the Bellman operator. (For a sense of why, read the proof of Theorem 1.1.1.)
The Bellman operator associated with the Epstein–Zin Bellman equation is not a contraction under the supremum distance for the most quantitatively significant parameterizations, and the same is true for the policy operators. This means that, in order to handle both the standard and the Epstein–Zin variations of the savings problem, we require a more general theory of dynamic programming that can handle both contractive and non-contractive settings. We begin constructing appropriate tools in Chapter 2.
1.4Sequential Analysis¶
This section presents a Bayesian formulation of a statistical decision problem described by Bertsekas (1976). Unlike the previous examples, there is no discounting, so the Bellman operator is not a contraction. Nonetheless, the same conceptual framework applies: the optimal loss function solves a Bellman equation and optimal policies have a threshold structure. In subsequent chapters, we will build a theory of dynamic programming that can handle this no-discounting case. For now, our objective is to motivate the theory by exploring the application through guess-work and simulation.[3]
1.4.1Introduction¶
We now consider a Bayesian formulation of the sequential testing problem originally studied by Milton Friedman, Allen Wallis, and Abraham Wald Wald, 1947Arrow et al., 1949. The following is an account of how the problem was conceived and came to the attention of Wald. The account is by Milton Friedman, one of the giants of 20th Century economics, and relates to his work during World War II as an analyst at the U.S. Government’s Statistical Research Group at Columbia University.
In order to understand the story, it is necessary to have an idea of a simple statistical problem, and of the standard procedure for dealing with it. The actual problem out of which sequential analysis grew will serve. The Navy has two alternative designs (say A and B) for a projectile. It wants to determine which is superior. To do so it undertakes a series of paired firings. On each round, it assigns the value 1 or 0 to A accordingly as its performance is superior or inferior to that of B and conversely 0 or 1 to B. The Navy asks the statistician how to conduct the test and how to analyze the results.
The standard statistical answer was to specify a number of firings and a pair of percentages (e.g., 53% and 47%) and tell the client that if A receives a 1 in more than 53% of the firings, it can be regarded as superior; if it receives a 1 in fewer than 47%, B can be regarded as superior; if the percentage is between 47% and 53%, neither can be so regarded.
When Allen Wallis was discussing such a problem with (Navy) Captain Garret L. Schuyler, the captain objected that such a test, to quote from Allen’s account, may prove wasteful. If a wise and seasoned ordnance officer like Schuyler were on the premises, he would see after the first few thousand or even few hundred [rounds] that the experiment need not be completed either because the new method is obviously inferior or because it is obviously superior beyond what was hoped for.
Friedman and Wallis worked on the problem for a while but didn’t completely solve it. Realizing that, they told Wald about the problem. That set Wald on a path that led him to create sequential analysis Wald, 1947. While the story above relates to wartime activity, sequential analysis has many significant applications in economics, finance, operations research, and other fields. Examples include determining the number of clinical trials before bringing a drug to market, real-time fraud detection, algorithmic trading, supply chain monitoring, and experimental interface design by social media companies.
On a technical level, this problem differs from the other problems we have investigated so far in that it involves no discounting. As a result, the Bellman operator is not necessarily a contraction. Nonetheless, we will find ways to prove that the core concepts from dynamic programming theory still apply.
The setting is as follows: A decision-maker observes a sequence of IID draws from an unknown distribution . The distribution is either or , where both and are known probability densities. After observing each draw, the decision-maker must choose one of three actions:
Accept the hypothesis that and stop.
Accept the hypothesis that and stop.
Draw another observation at cost .
The decision-maker incurs a loss whenever she makes an incorrect decision. The losses are as follows:
loss when incorrectly accepting (in fact )
loss when incorrectly accepting (in fact )
Both and are strictly positive. The objective is to minimize the expected loss, which includes both the cost of sampling and the potential loss from incorrect terminal decisions.
The decision-maker begins with a prior belief that . The state variable is the posterior belief , which represents the probability that given observations . After observing , the posterior is updated via Bayes’ rule:
Notice that is Markovian over the sampling process.
Given current belief , the next draw from the sequence has the predicted distribution
The controller uses this distribution to take expectations over next-sample draws from the process.
1.4.2Optimality¶
For this sequential sampling problem, the Bellman equation for minimizing loss has the form
The Bellman equation can be understood as follows: The value represents the minimum expected loss given current belief state . This value is itself the minimum over three terms, each of which corresponds to a choice. The first term is associated with accepting and has expected loss , since is the (subjective) probability that . The second term is for accepting . This has expected loss , since is the probability that . The last term is the expected loss associated with continuing to the next sample and then behaving optimally.
We now state an optimality result that parallels our earlier theorems. Let be the state space for the belief state and let denote the set of bounded, Borel measurable functions from to . The action space is , where action 0 represents accepting , action 1 represents accepting , and action 2 represents continuing to sample. The set of all feasible policies, denoted by , is all Borel measurable .

Figure 1.19:Distributions and sample paths for and
We prove this theorem via a more general result in Theorem 3.2.9. For now, to illustrate the key ideas, we consider a specific example where and , as shown in Figure 1.19. The figure also shows IID sample paths generated by the densities and . The remaining parameters are set to , , and .

Figure 1.20:Optimal policy and loss function
Figure 1.20 shows the optimal policy and the corresponding loss function . The functions were computed by a version of value function iteration, starting from initial condition . The state space was discretized into a grid of 200 points, and the integral over future observations was approximated using a grid of 50 points over the support of the distributions. The left panel displays the optimal action as a function of the posterior belief . As predicted by Theorem 1.4.1, the optimal policy has a threshold structure: there exist cutoffs with such that
accept if ,
accept if , or
continue sampling if .
Figure 1.21 shows dynamics of the belief state under the optimal policy. The belief state shifts according to the update rule , with the samples being drawn from either or . When the true distribution is , the belief tends to drift downward toward zero; when it is , the belief drifts upward toward one. Under the optimal policy, sampling terminates once the belief exits the continuation region , at which point the corresponding hypothesis is accepted.
Figure 1.21:Belief paths under the optimal policy
1.5Summary¶
The examples in this chapter illustrate the breadth of problems that dynamic programming can address, but they also expose the limits of classical methods. The firm problem and finite MDPs with constant discounting yield contracting Bellman operators, making optimality theory and computation straightforward. However, several of the extensions and models we encountered require a more general foundation: Epstein–Zin preferences and the sequential analysis problem produce Bellman operators that are not contractions; risk-sensitive and robust formulations involve nonlinear aggregators; and distributional dynamic programming operates on a non-standard value space ordered by stochastic dominance. The abstract theory developed in the next chapter provides a unified framework that accommodates all of these settings.
1.6Chapter Notes¶
Richard Bellman’s ((1957)) monograph established dynamic programming as a unified framework for sequential optimization, introducing optimality concepts and recursive functional equations that form the foundations of this text. David Blackwell made major contributions to the mathematical theory, proving contraction properties for discounted problems with finite state spaces Blackwell, 1962 and extending these results to Borel spaces using order-preserving operators Blackwell, 1965. Eric Denardo ((1967)) further generalized contraction results to a broad class of sequential decision problems, introducing conditions that anticipate many ideas in this text.
The LP formulation for MDPs discussed in Section 1.2.1.4 has a long history. LP methods are particularly useful for constrained MDPs, where the controller faces additional restrictions on expected rewards or resource usage. Such problems arise in network routing, healthcare resource allocation, and other applications. See Altman (1999) for a textbook treatment. The LP formulation is also central to average-reward problems, where occupation measures play a key role (see, e.g., Chapter 8 of Puterman (2005)). For large state-action spaces, approximate LP methods using basis function representations can help scale the approach; Farias & Van Roy (2003) provides a foundational treatment.
The firm problem we studied in Section 1.1 is closely related to classic references such as Jovanovic (1982) and Hopenhayn & Prescott (1992), and has been extended by many authors (see, e.g., Alessandria et al. (2021) or Sterk et al. (2021)). Regarding the extensions to the firm problem in Section 1.1.3, excellent discussions of Markov decision processes with risk-sensitive objectives can be found in Bäuerle & Jaśkiewicz (2024) and Bäuerle & Jaśkiewicz (2025). We borrowed from their exposition in several parts of the chapter and return to the key ideas later in the text. The variational formula connecting risk-sensitivity to robustness is developed in Anantharam & Borkar (2017); see also Chapter 8 of Sargent & Stachurski (2025) for further discussion.
The discussion in Section 1.1.3.5 mentions dynamic (time) inconsistency. For analysis of time inconsistency in macroeconomic models and its connections to dynamic programming, see Sargent (2024), Sargent & Yang (2025), and Sargent & Yang (2025). For recent theoretical work, see Stanca (2025), Strack & Taubinsky (2026), and Bayraktar et al. (2023) on the stability of equilibria in time-inconsistent stopping.
The finite MDP framework in Section 1.2 is treated comprehensively in Puterman (2005); see also Chapter 5 of Sargent & Stachurski (2025) for an introductory treatment. The three core algorithms we presented — VFI, HPI, and OPI — are discussed in these sources. Howard policy iteration was introduced in Howard (1960). The cash management application in Section 1.2.1.5 builds on the inventory-theoretic models of money demand developed by Baumol (1952) and Tobin (1956). Our continuous time MDP model in Section 1.2.2 follows the framework described in Guo & Hernández-Lerma (2009); the uniformization technique we used to reduce continuous time problems to discrete time ones is standard (see, e.g., Puterman (2005), Chapter 11).
The optimal savings problem in Section 1.3 is also called the income fluctuation problem. It was studied in an early and influential form by Brock & Mirman (1972), who analyzed optimal growth under uncertainty with discounted CRRA utility. It has become a core building block for heterogeneous agent models following Bewley (1986), Huggett (1993), and Aiyagari (1994). Recent analysis can be found in Carroll & Shanker (2026), Li & Stachurski (2014), Lehrer & Light (2018), Light (2018), Ma et al. (2020), and Ma & Toda (2021). For a continuous-time treatment, see Achdou et al. (2022). See Stokey & Lucas (1989) and Stachurski (2022) for textbook treatments of the underlying dynamic programming theory.
The Epstein–Zin preferences discussed in Section 1.3.3 were introduced by Epstein & Zin (1989) and Weil (1990), building on earlier work of Kreps & Porteus (1978). The separation of risk aversion from the elasticity of intertemporal substitution enabled by Epstein–Zin utility has been central to the long-run risk literature initiated by Bansal & Yaron (2004), where small persistent consumption shocks get heavily priced, generating realistic equity premia using “reasonable” parameters. The equity premium puzzle was posed by Mehra & Prescott (1985); the associated risk-free rate puzzle was posed by Weil (1989). Both puzzles are discussed extensively in Chapter 13 of Ljungqvist & Sargent (2018). Chapter 7 of Sargent & Stachurski (2025) provides an introduction to recursive preferences.
The discussion of ambiguity in Section 1.2.3.3 connects to a large literature on robust decision-making under model uncertainty. The minimax formulation we presented follows the approach of Wald (1950); see also Ellsberg (1961) for a foundational discussion of ambiguity aversion and Hansen & Sargent (2011) for connections to robust control. Recent work on dynamic programming under ambiguity includes Maccheroni et al. (2006), Klibanoff et al. (2009), Marinacci & Montrucchio (2019), Neufeld et al. (2023), Cerreia-Vioglio et al. (2026), Benyamine et al. (2026), and Wang & Si (2026). An excellent survey on ambiguity and its implications for economics and finance can be found in Ilut & Schneider (2023).
The sequential analysis problem in Section 1.4 originated with Wald (1947) and Arrow et al. (1949). The Bayesian formulation we presented follows Bertsekas (1976). For treatments from frequentist and Bayesian perspectives, respectively, see Sargent & Stachurski (2026) and Sargent & Stachurski (2026).
The introduction to this chapter mentioned applications of dynamic programming to atemporal problems, such as genome sequencing and the structure of production chains. For one discussion of the former see Gu et al. (2023); for the latter see, for example, Kikuchi et al. (2021). We mentioned also that many recent applications of dynamic programming are connected to machine learning and artificial intelligence. Introductions to the literature can be found in Bertsekas (2021) and Kochenderfer et al. (2022).
The literature on “recursive contracts” in macroeconomics makes progress here by using a set of procedures that have been called “dynamic programming squared”. Ljungqvist & Sargent (2018) devote a suite of chapters to that topic.
In engineering it is sometimes called a closed loop control to emphasize that the control must be a measurable function of an observed history and not depend on as yet unrealized random variables.
In his formulation, Abraham Wald Wald (1947) proceeded as a frequentist statistician, using objects from Neyman-Pearson’s hypothesis testing theory. For descriptions of the problem from the distinct frequentist and Bayesian perspectives, see Sargent & Stachurski (2026) and Sargent & Stachurski (2026).
- Bellman, R. (1957). Dynamic programming. In Science. American Association for the Advancement of Science.
- Sargent, T. J., & Stachurski, J. (2025). Dynamic Programming: Finite States. Cambridge University Press.
- Modigliani, F., & Miller, M. H. (1958). The cost of capital, corporation finance and the theory of investment. The American Economic Review, 48(3), 261–297.
- Smith, C. W., & Stulz, R. M. (1985). The Determinants of Firms’ Hedging Policies. Journal of Financial and Quantitative Analysis, 20(4), 391–405.
- Graham, J. R., Harvey, C. R., & Puri, M. (2013). Managerial attitudes and corporate actions. Journal of Financial Economics, 109(1), 103–121. 10.1016/j.jfineco.2013.01.010
- Kerr, S. P., Kerr, W. R., & Dalton, M. (2019). Risk attitudes and personality traits of entrepreneurs and venture team members. Proceedings of the National Academy of Sciences, 116(36), 17712–17716. 10.1073/pnas.1908375116
- Almeida, H., Campello, M., de Castro, L. I., & Galvao Jr, A. F. (2024). A Quantile Model of Firm Investment [Techreport]. National Bureau of Economic Research.
- Bellemare, M. G., Dabney, W., & Rowland, M. (2023). Distributional reinforcement learning. MIT Press.
- Bäuerle, N., & Jaśkiewicz, A. (2024). Markov decision processes with risk-sensitive criteria: an overview. Mathematical Methods of Operations Research, 99(1), 141–178.
- Puterman, M. L. (2005). Markov decision processes: discrete stochastic dynamic programming. Wiley Interscience.
- Baumol, W. J. (1952). The Transactions Demand for Cash: An Inventory Theoretic Approach. The Quarterly Journal of Economics, 66(4), 545–556.
- Tobin, J. (1956). The Interest-Elasticity of Transactions Demand For Cash. The Review of Economics and Statistics, 38(3), 241–247.
- Engel, K.-J., & Nagel, R. (2006). A short course on operator semigroups. Springer Science & Business Media.
- Guo, X., & Hernández-Lerma, O. (2009). Continuous-time Markov decision processes. Springer.
- Wald, A. (1950). Statistical Decision Functions (p. ix + 179). John Wiley & Sons.