Introduction to Python for Economics¶
Aims & Outcomes:
Why Python?
Open Source vs. Proprietary
Provide an overview of Programming vs. Scripting
Discuss Scientific Computing
Why Python?¶
Easy to learn, and well designed language
Massive scientific ecosystem
Open Source
Used extensively in datascience and machine learning communities.
It is a good fit for many Scientific Computing tasks as
python has strong tools for working with data, vectorization,
jit compilation, parallelization, visualization, etc.
It is a versatile language that is used extensively across many domains.
Proprietary vs Open Source¶
Proprietary¶
Excel
MATLAB
STATA
These are typically good tools for specific tasks but
also have some drawbacks.
Pro:
Simpler to use with Integrated graphical interfaces
Company that provides user support
Stable
Con:
Cost Money
(Change of Tools Problem) Typically constrained to a
narrowtask set when compared to general high-level programming languages so can be difficult to achieve some task typesAccess to higher performance can be expensive
Open Source¶
Python
Julia
R
Are considered the leading programming languages to
support scientific computing.
Pro:
Free
Versatile & Flexible
Ultimately customisable and auditable being
open sourceQuick moving communities writing packages and extensions
Con:
Initially less
user friendlywith limitedpoint and clickstyle of interaction (higherinitial fixed costs)Sometimes more
verbosesyntaxQuick moving communities writing packages and extensions :-).
Choice of Programming Languages¶
There is a large variety of programming languages available to
choose from and this is largely down to a trade-off between
productivity for writing code, execution speed, and/or
design for a domain specific purpose.
Low Level Languages¶
Provide fine grained control at the hardware level
Languages such as:
Assembly
LLVM (Assembler)
Example: 1 + 1 in assembly
pushq %rbp
movq %rsp, %rbp
movl $1, -12(%rbp)
movl $1, -8(%rbp)
movl -12(%rbp), %edx
movl -8(%rbp), %eax
addl %edx, %eax
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
popq %rbp
Intermediate Level Languages¶
Intermediate level languages used to be considered high level
languages. Many languages in this range are often fit for purpose type languages.
Languages such as:
C/C++
Fortran
Java
Design for Purpose:
Linus Torvalds thinks C is the best language choice – for writing
the linux kernel. This is because the C programming language
is a nice balance between access to low-level and productivity. It is
productive enough to write large and complex systems reasonably
quickly but has enough access to low-level features to build
interfaces for hardware and systems.
It is a good fit for writing operating system kernels such as linux.
Example: 1 + 1 in C
#include<stdio.h>
int main()
{
int sum = 0;
sum = 1 + 1;
printf("Sum = %d\n", sum);
return 0;
}
High Level Languages¶
Provide a high degree of productivity through abstraction and
automation etc. and typically include features such as:
Automatic memory management
Advanced Input/Output (IO)
Advanced data structures
(Often) interpreted vs. compiled
Languages such as:
Python
Julia
Ruby
Rust
Example: 1 + 1 in python
1 + 1
Scripting vs. Programming Languages
Most interaction with Stata is in a scripting context. The do file is a convenient way to
write a set of instructions that can be repeated for a given workflow. But it lacks features
of more general programming languages such as the use of objects to store data and methods.
This is often a design choice!
Stata would like a high productivity environment to run complex statistical models and
the syntax is less general then python. For example, many stata commands work over
rows of data because of the domain.
Mata (Stata’s Programming Language)
There is mata which can be
used to write stata programs and is very similar to C with a focus on matrix operations.
Scientific Computing¶
Scientific Computing ultimately needs to be:
Productive- easy to read, write, debug, exploreFastcomputationsFlexibleacross domains
In most scientific computing applications we also don’t want to have to worry much
about interfacing or managing the hardware on a day to day
basis – however we would like the ability to maximise usage of that hardware when
required so we don’t have to change languages.
Productivity vs. Execution Speed¶
Productivity and Execution typically come with a trade-off:
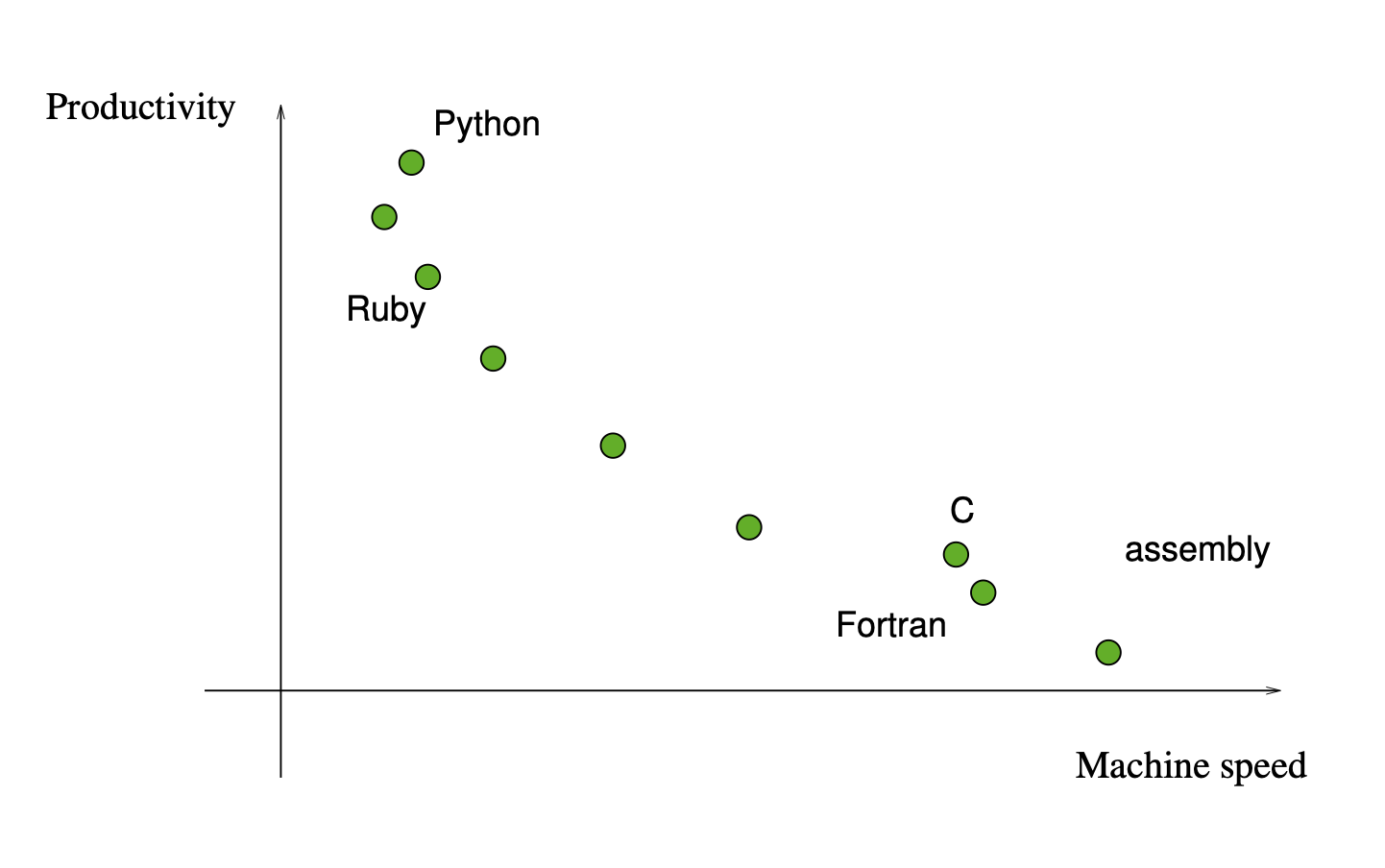
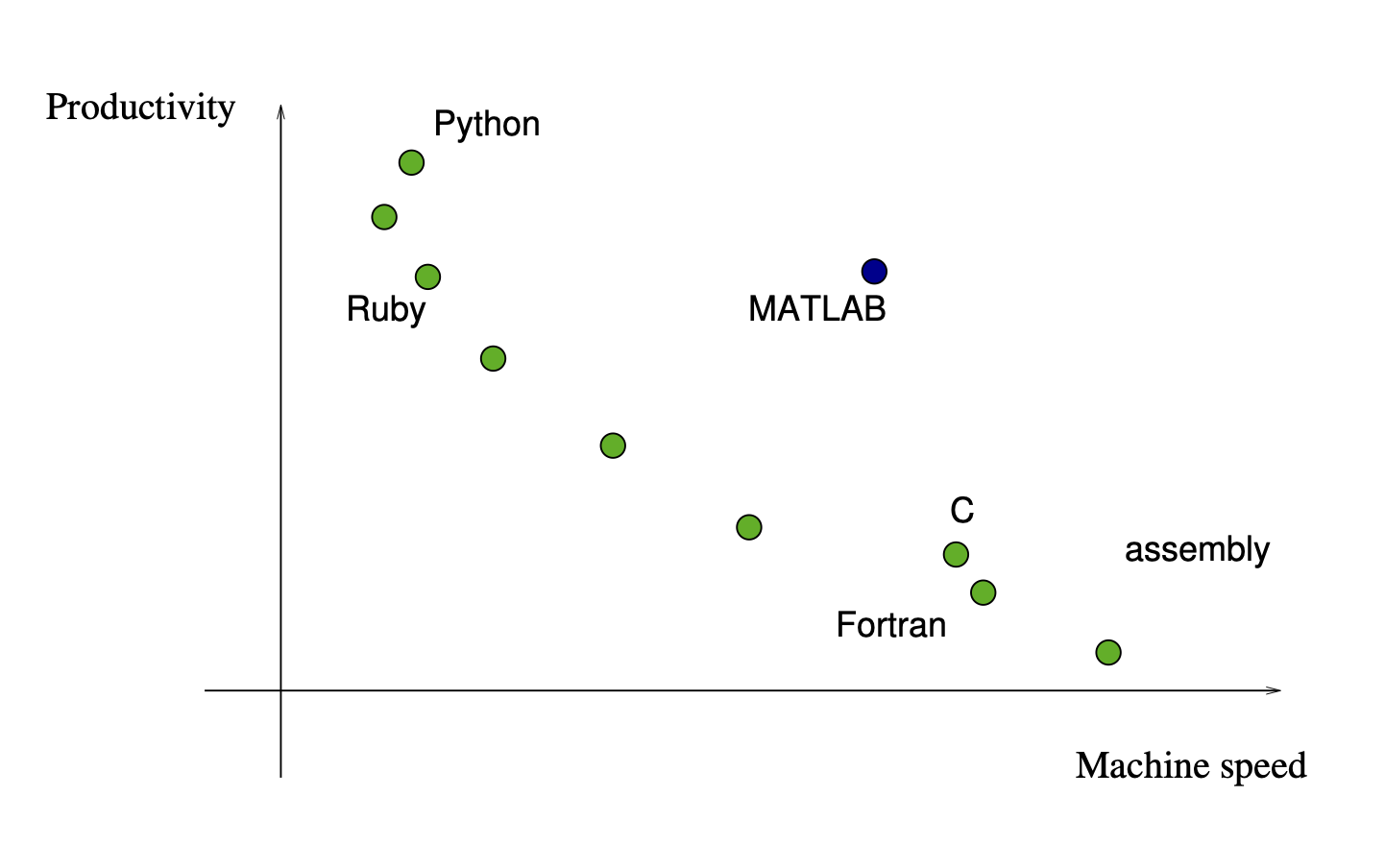
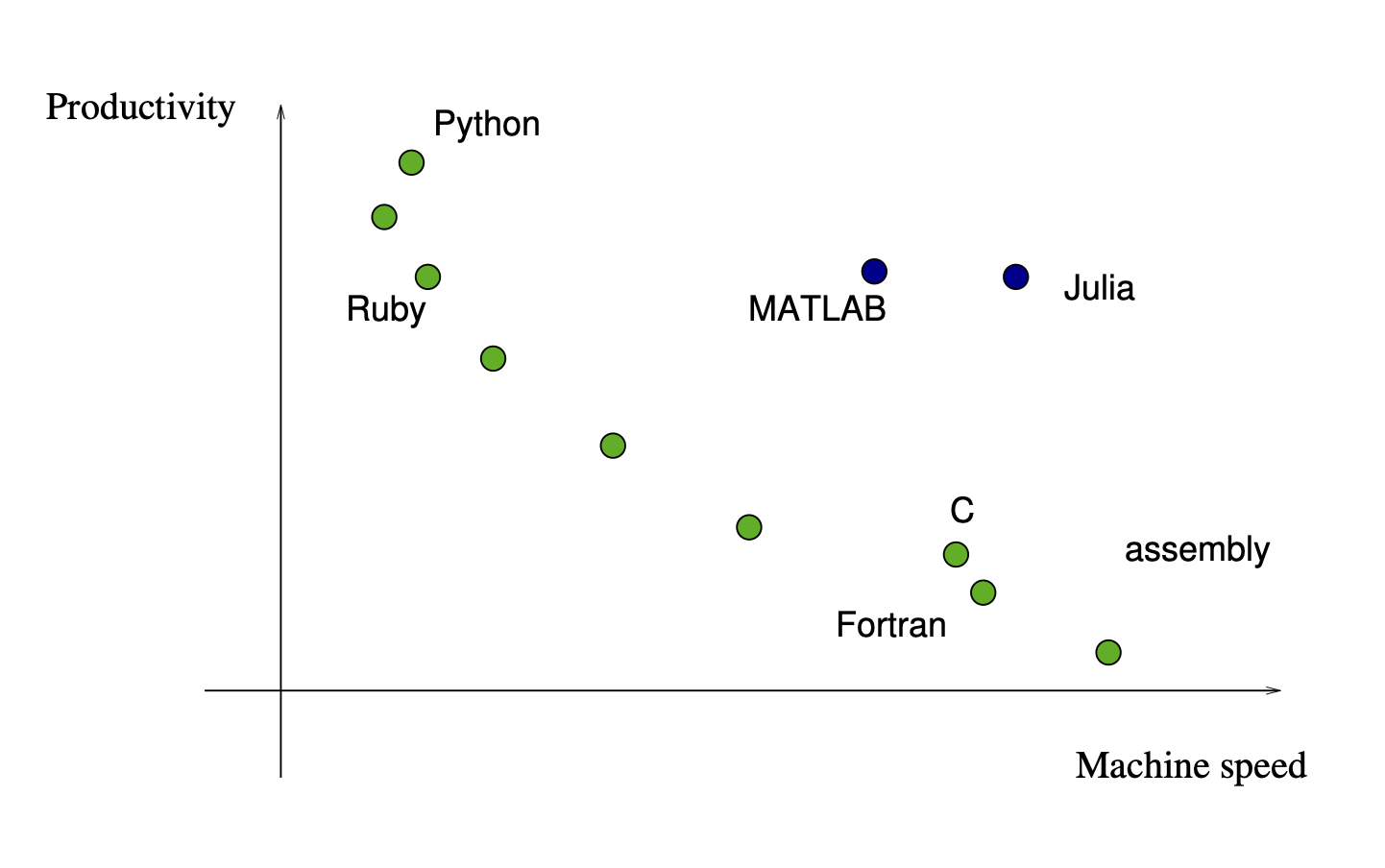
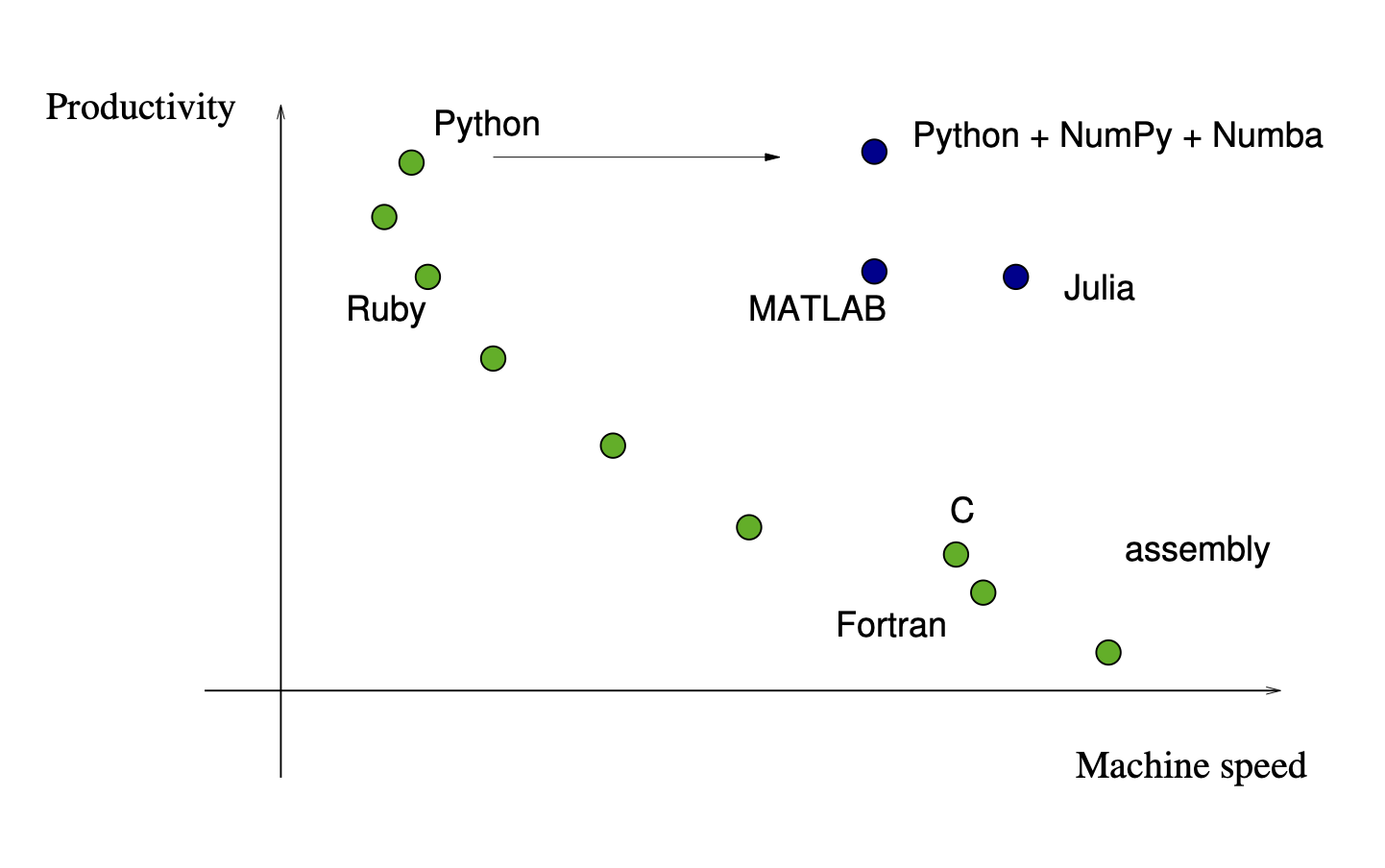
One of the strengths of python is its adaptability to many
different contexts while retaining a very high level of
productivity. This is largely due to language design
(i.e. everything is an object), and advances in access in
compute power.
The python ecosystem¶
The python ecosystem has strong tools in working with data, vectorization,
JIT compilation, parallelization, visualisation, etc.
The next session on the python ecosystem will introduce many useful packages such as:
Scipy, NumPy, matplotlib, Pandas (Scientific computing infrastructure)
Numba (JIT compilation, multi-threading)
NetworkX (Domain tools)
This will hopefully help to:
reduce search cost
demonstrate the versatility of the
ecosystem
History¶
Python was first released in 1991.
It has taken 30 years to build the ecosystem and become as popular as it has become.
Current Popularity¶
There is a nice wired article that talks about
the continued popularity of python.
The redmonk rankings put python in the #2 spot!
The key takeaway from the article:
O’Grady cites Python’s versatility as one reason for its ongoing popularity. Companies like Google, Dropbox, and Instagram all rely heavily on Python, as do countless smaller ventures. It also has a home in academia as the preferred data-crunching language of many scientists and mathematicians.
Platform Independence: Windows, macOS, Linux¶
Modern languages such as python and julia are interpreted languages.
If your platform has an interpreter the code is often cross-platform.
I often work and collaborate with others across all three platforms and your own productivity largely comes down to preference.
Note on Windows
The user interface on Windows (in my view) is the most difficult
but that is largely due to less accessibility to terminal
based workflows. This is changing quickly and can now be
largely solved using Windows subsystem for linux which runs
a virtualised linux kernel that enables access to many
high performance tools and productive terminal based
workflows.
Resources¶
Some additional reading for those interested: