Integrated Workflows¶
There are three primary interfaces to running python within stata:
We will then look at how to transfer data between python and stata
in both directions through the stata function interface.
Running python Interactively with a First Example¶
You can run python interactively within stata in a manner that is the
equivalent of running the python REPL program through a terminal.
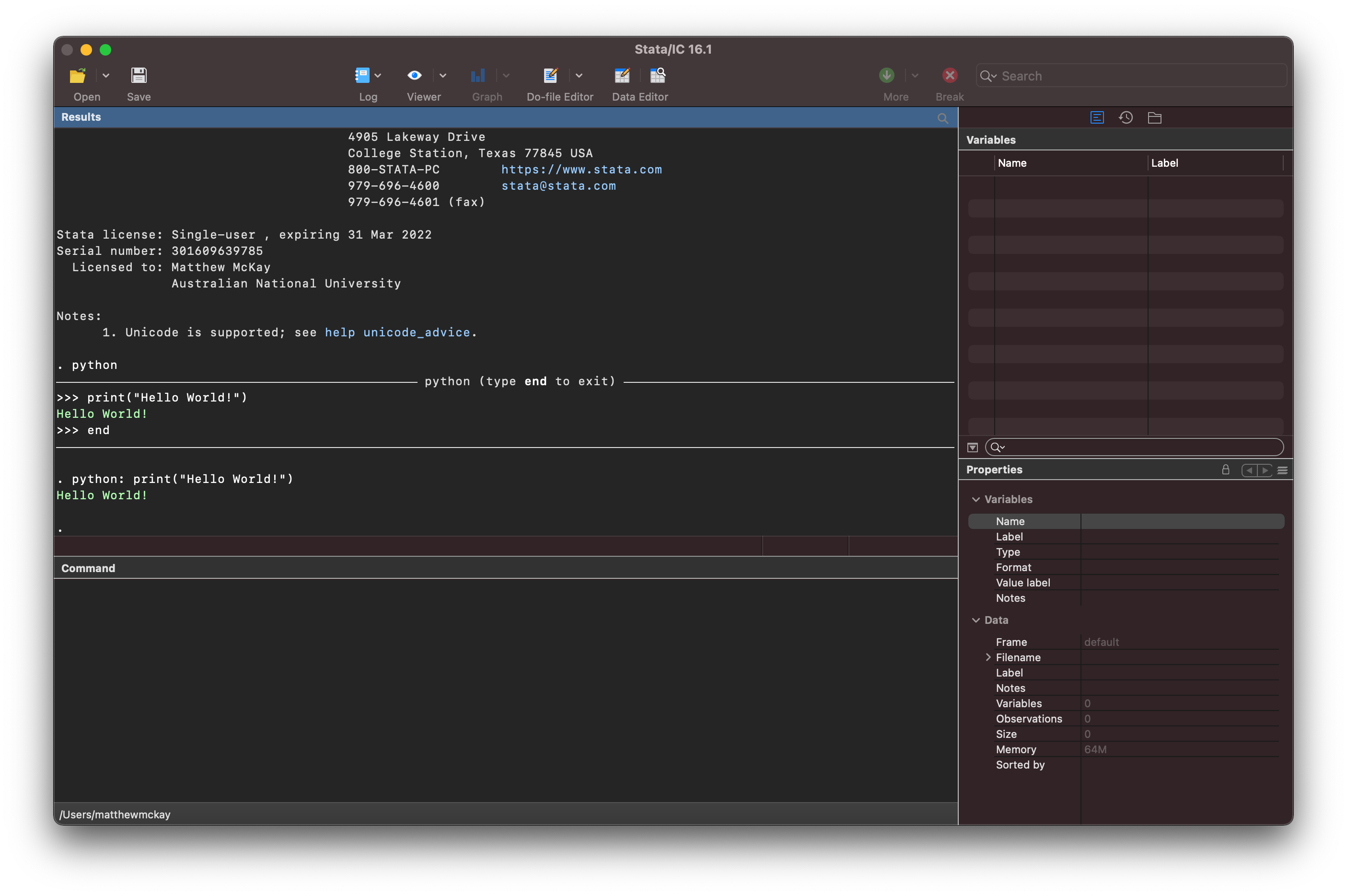
This is activated by typing python in the command window.
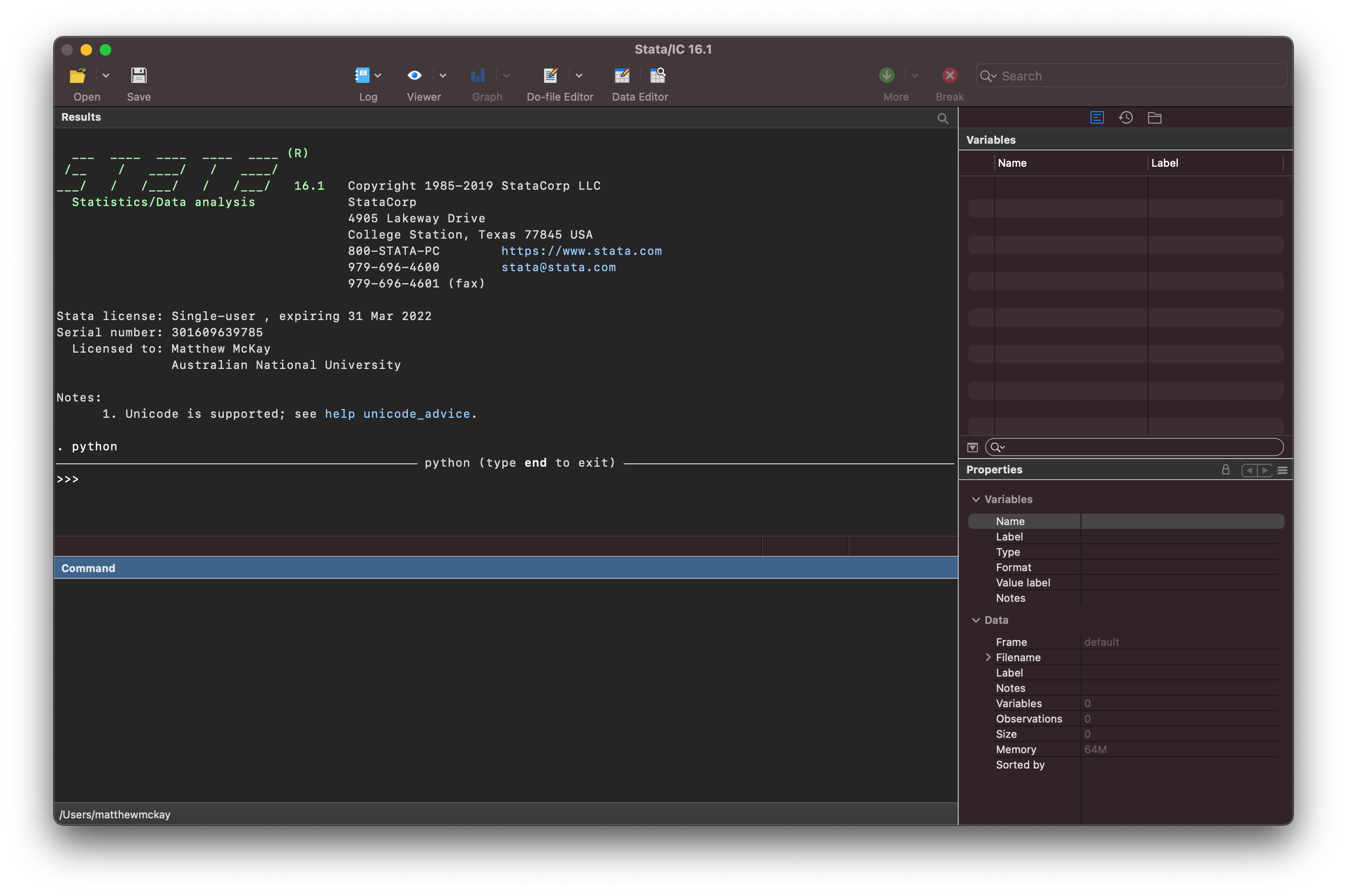
You are now interfacing directly with the python interpreter as indicated in
the Result window.
You can now write python code such as:
print("Hello World!")
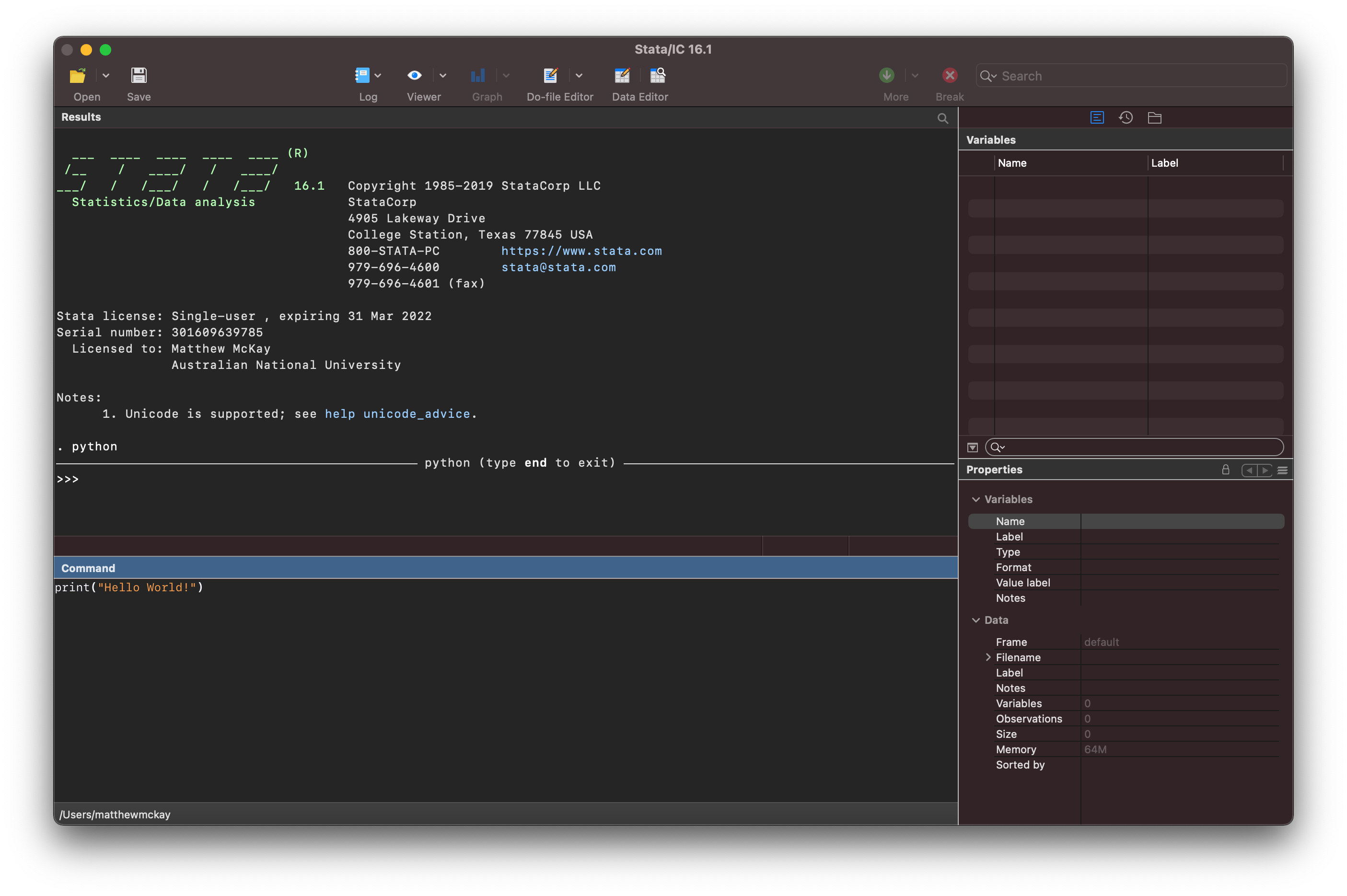
once you hit enter stata sends the code snippet to the python interpreter
for processing and shows the result
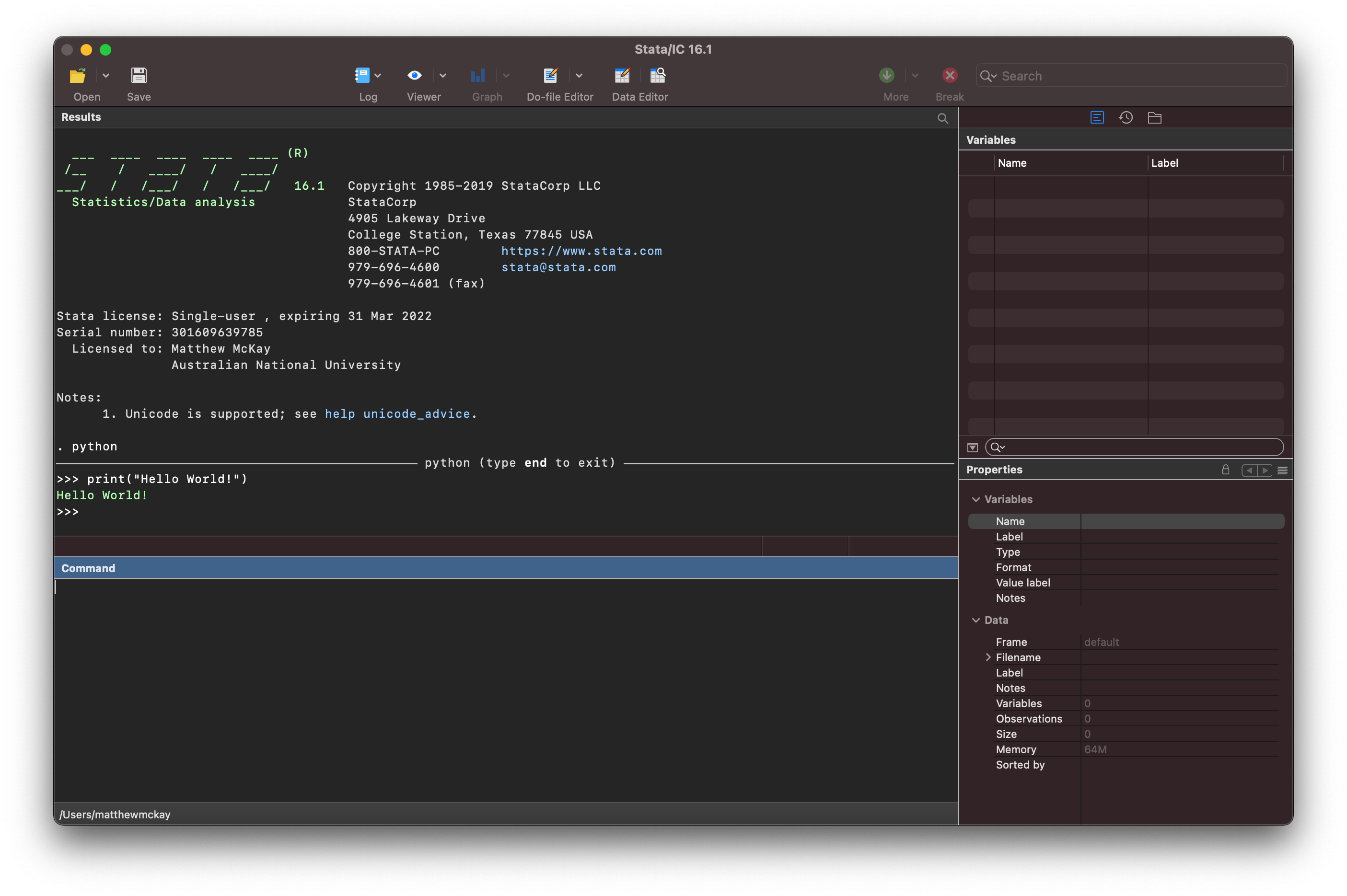
To stop interfacing with the python interpreter you need to type end in
the command window
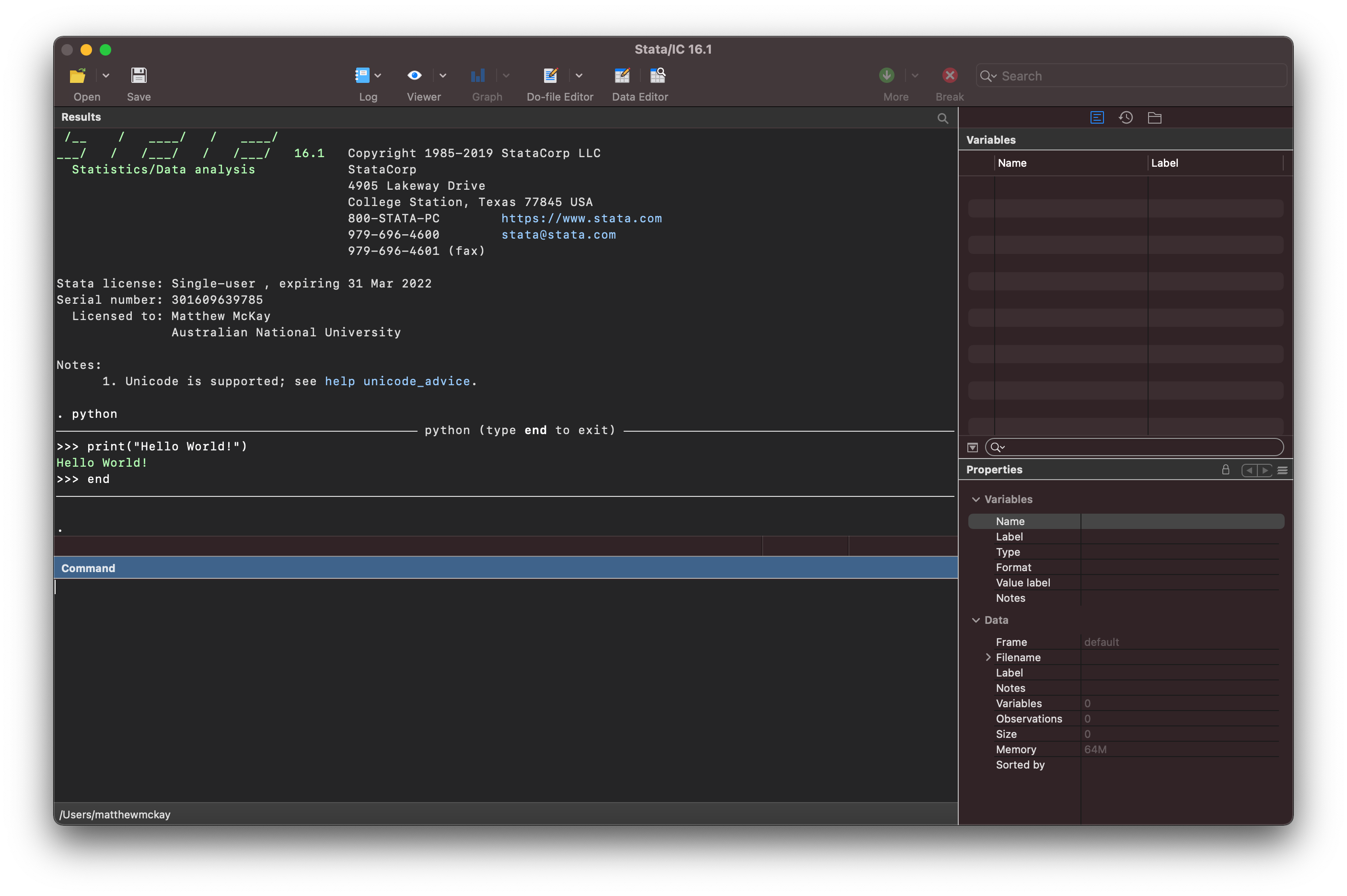
this will return you to the standard stata interface.
Tip
If you have a one line python command you can use
python: print("Hello World!")
which will pass the code to python, display the results
directly below in the Results window, and return you to
the stata command environment.
Running python in a do file¶
Another option for running python code is through the do file.
Let’s open the do file editor and add:
di "Stata Here"
python: print("Python Here")
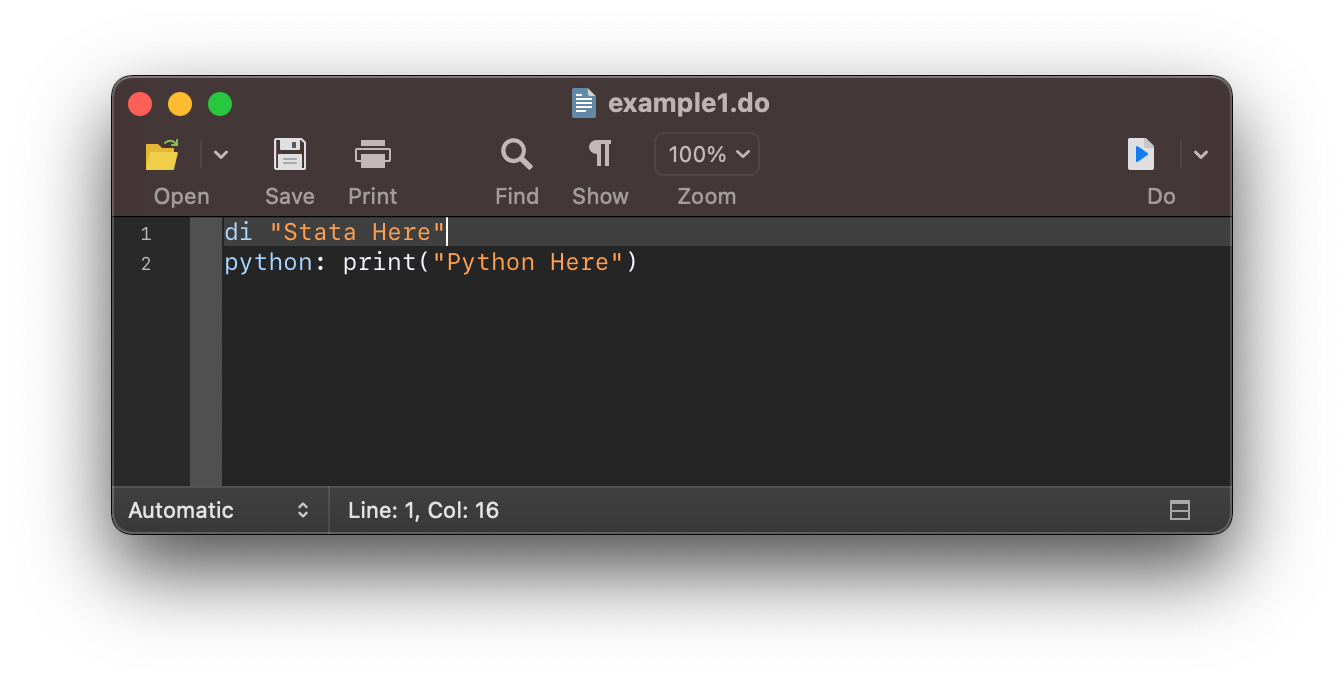
and when you click on the Do button you get the result:
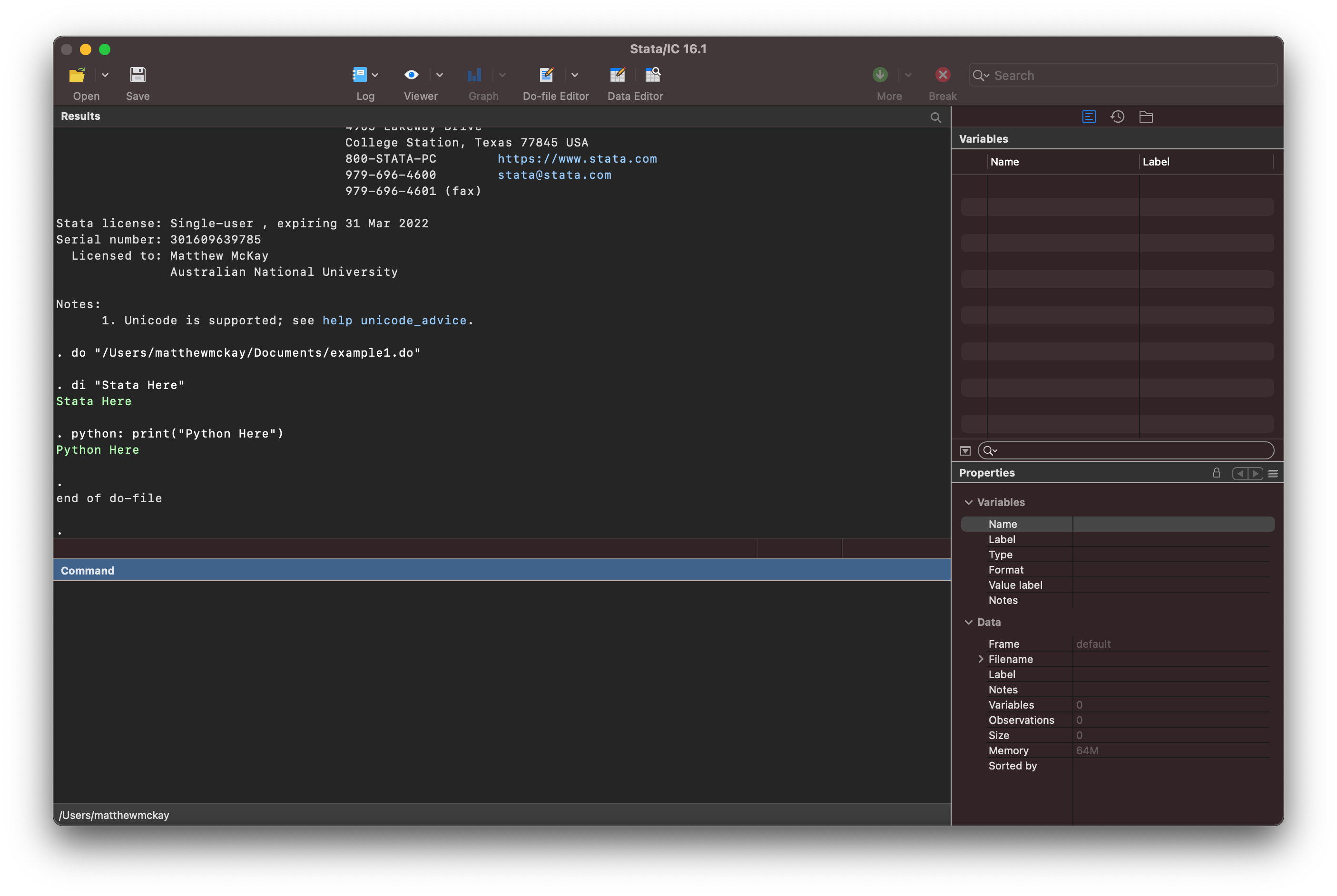
where the results from python are displayed similarly to stata output.
However, most of the time you will want to add in a block of code such as:
for i in range(0,2):
print("Python Here")
This can be done by delimiting the python code within the do file using either
python
<python code>
end
or
python:
<python code>
end
The difference between these two delimiters is in how stata handles any
errors in python.
The python delimiter will continue to execute the rest
of the python code if an error is encountered, while the python: delimiter will immediately
return control to stata once the error is encountered.
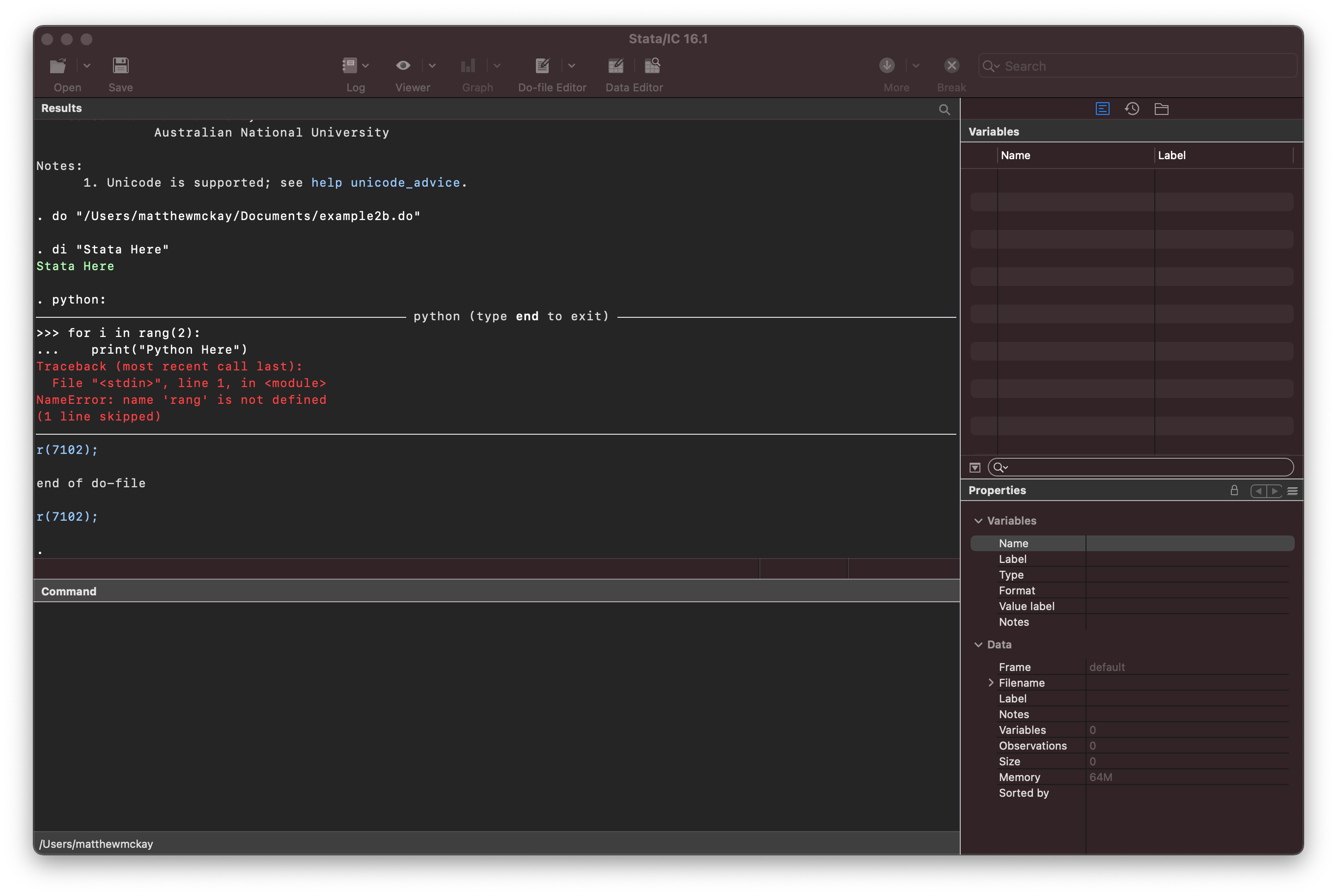
di "Stata Here"
python
for i in rang(2):
print("Python Here")
print("Python Done")
end
di "Back in Stata Land!"
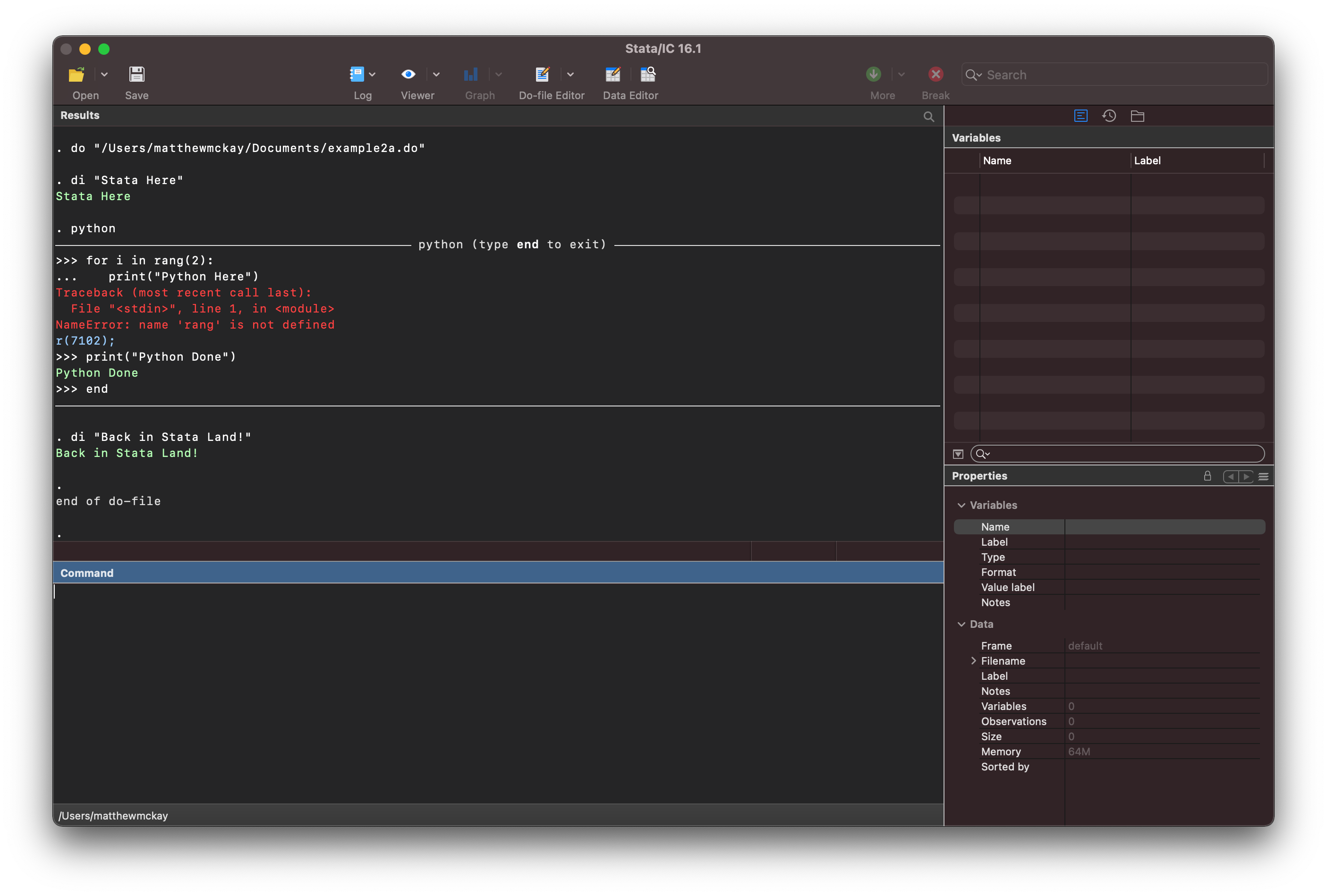
As you can see stata has continued to execute code past the point at which there is
an error.
However if you use python: the execution will halt at the point of the error.
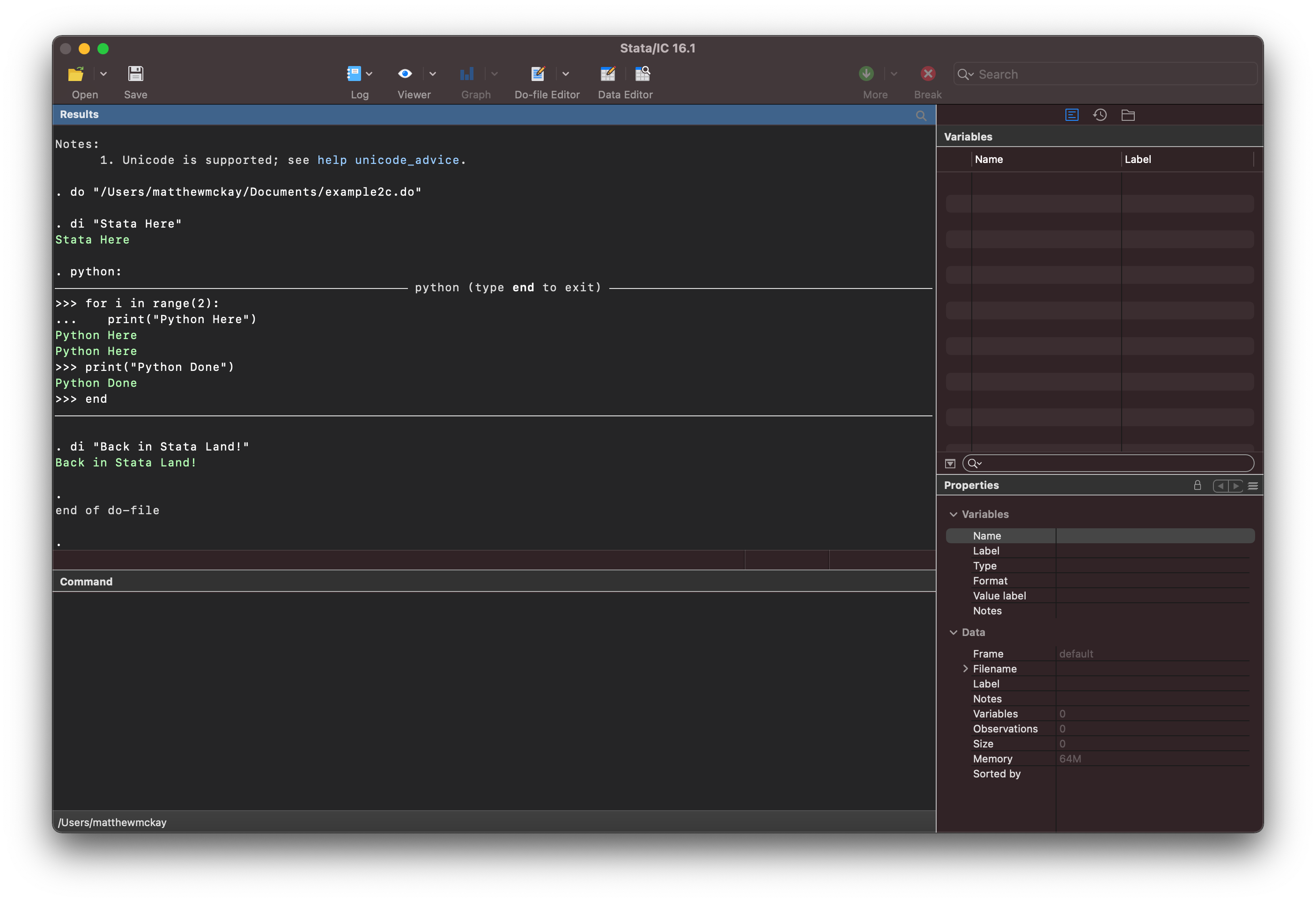
di "Stata Here"
python:
for i in rang(2):
print("Python Here")
print("Python Done")
end
di "Back in Stata Land!"
Tip
I tend to use python: as I prefer to get to the error quickly to fix the problem
without any distracting output below it. Also in a long running program you will want
to fix the issue prior to the rest of the program executing.
We can use the error message to fix the issue now and run the fixed do file
di "Stata Here"
python:
for i in range(2):
print("Python Here")
print("Python Done")
end
di "Back in Stata Land!"
The Do File Editor and White Space¶
Reminder
Whitespace is used by python to declare scopes and is an integral part
of the language definition
The do file editor doesn’t provide you with full text editor support when writing
python code in the do file editor.
For example if you type:
python:
for i in range(10):
|<curser placed here>
the editor will not automatically indent your code.
However once you have set the curser to the correct indentation level it will retain that indentation level for subsequent lines.
python:
for i in range(10):
|
|<curser placed here>
So you need to be careful with whitespace
Also what you type in the delimiters is directly passed to python
so you can’t indent these code-blocks such as:
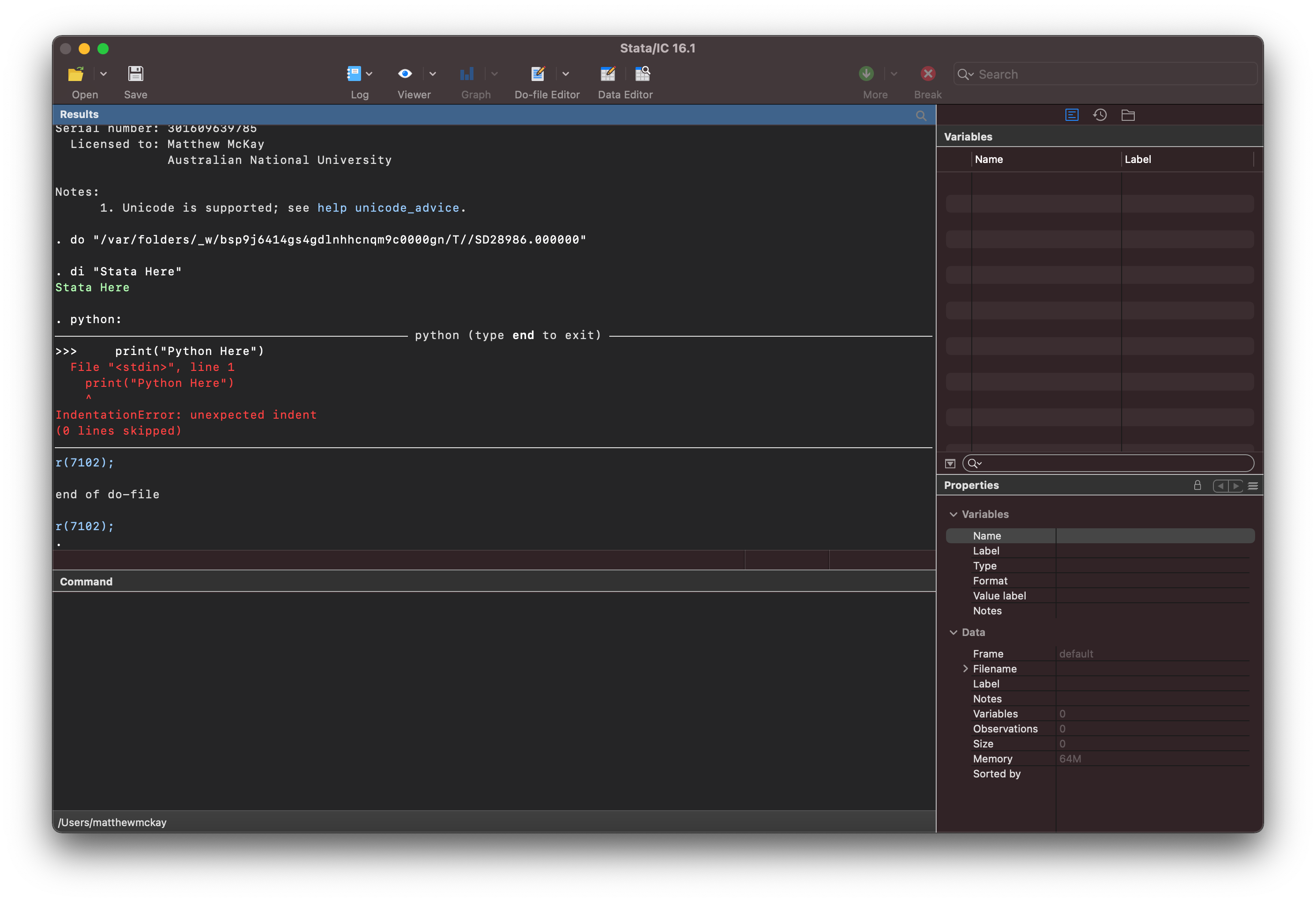
di "Stata Here"
python:
print("Python Here")
python will return the following error:
Running python scripts in stata¶
A third option is to run a python script that contains some python code
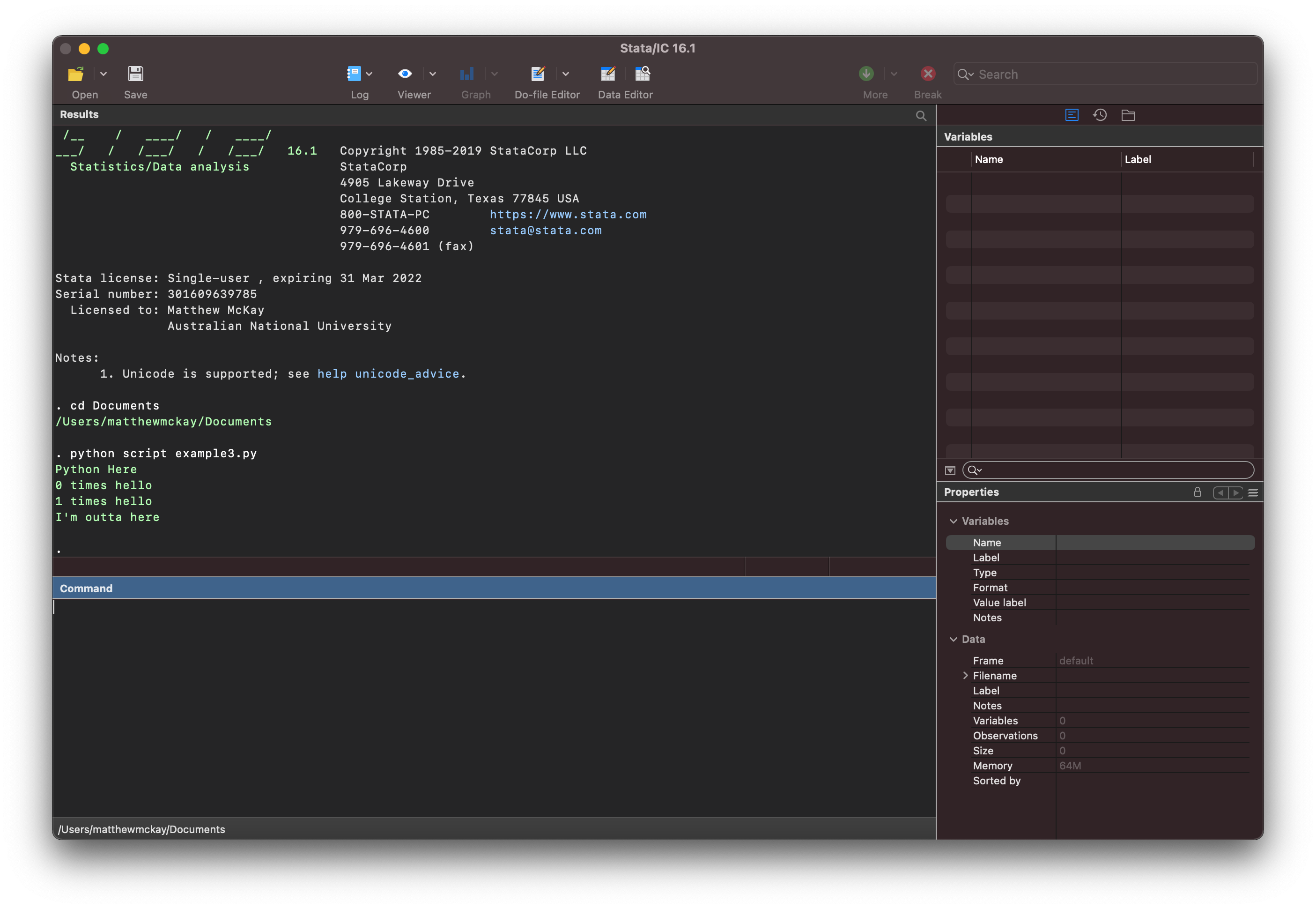
If you save the following code in a file example3.py:
print("Python Here")
for i in range(2):
print(f"{i} times hello")
print("I'm outta here")
you can then run this script in stata using:
python script example.py
with the output:
Tip
This can be a very useful way to run python code as it leaves you
to write python code in any text editor you like such as
vscode.
Interacting between Stata and Python¶
Tip
In many cases it can be simpler to keep python and stata
workflows independent of each other and use files to transfer
data between them.
This is covered in File based Workflows
So far the python and stata runtime environments have been
independent of each other to learn about how to run python code
within stata (i.e. they haven’t shared any data)
For many applications we want some level of interaction between stata
and python by copying back and forth objects between the different runtime
environments.
Stata makes various components of its internals available to python via
the stata function interface (sfi)
to enable such interaction with:
Dataset which connects
pythonwith the current in memorystatadatasetMacros which connects
pythonwithstatamacros
In addition it also provides access to many other stata components.
Copying Data from Stata to Python¶
Stata Blog Post
This section is heavily inspired by this excellent stata blog post
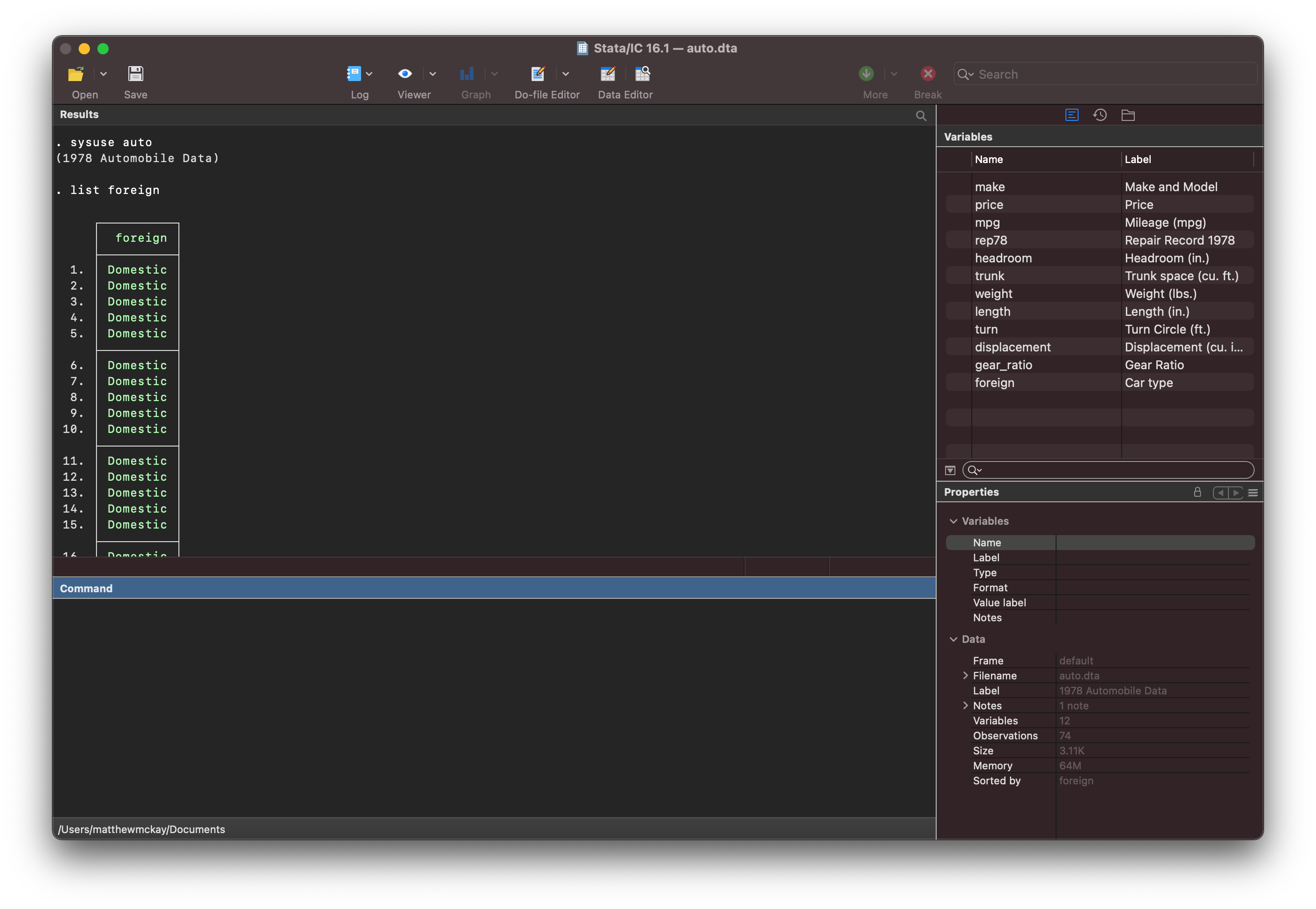
sysuse auto
list foreign
Listing the foreign data in stata shows
We can then use sfi.Data to transfer the raw data to python using the .get method
of the Data object from the stata function interface package.
python
from sfi import Data
dataraw = Data.get('foreign')
dataraw
end
and it looks like
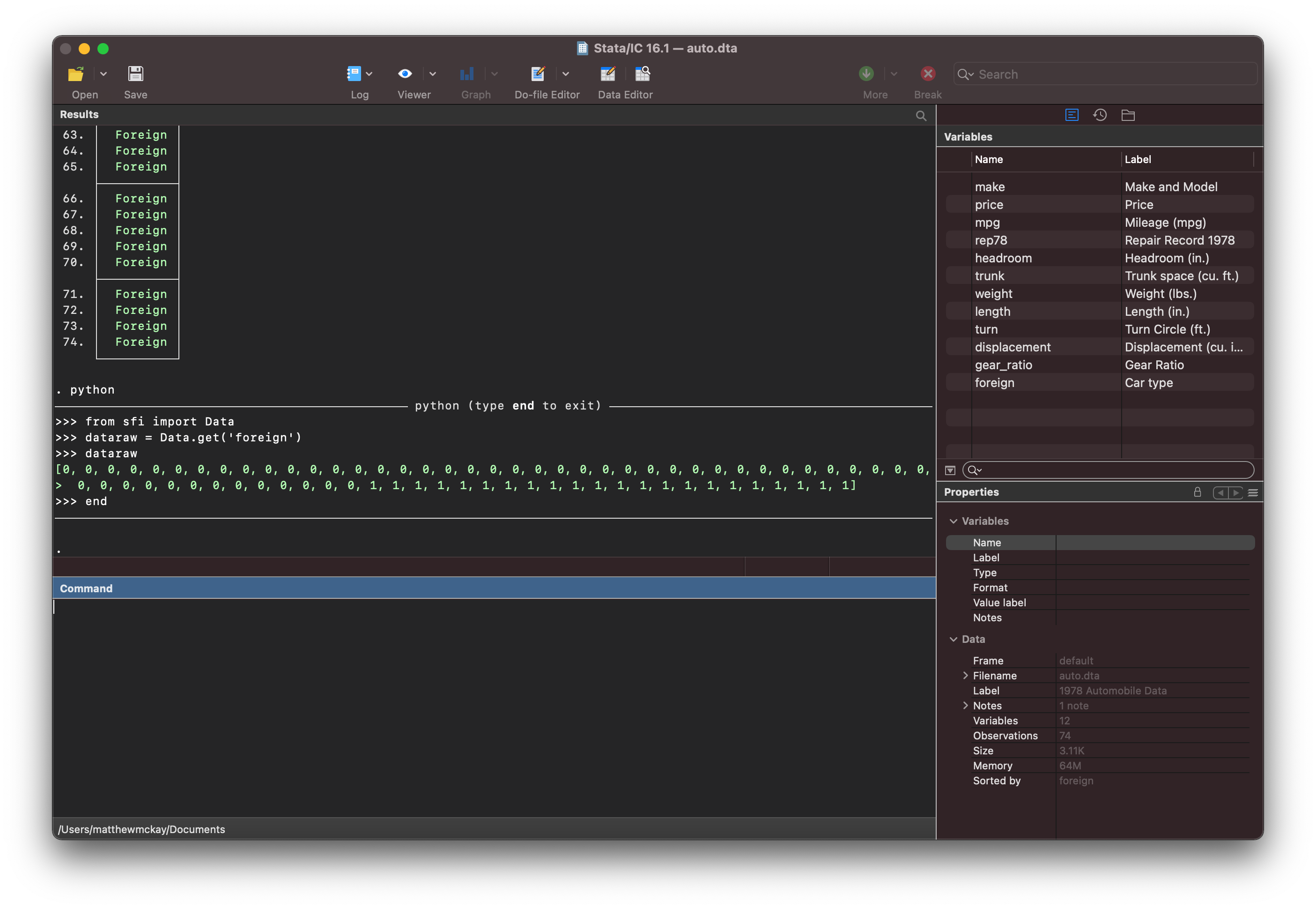
Notice that the data looks different.
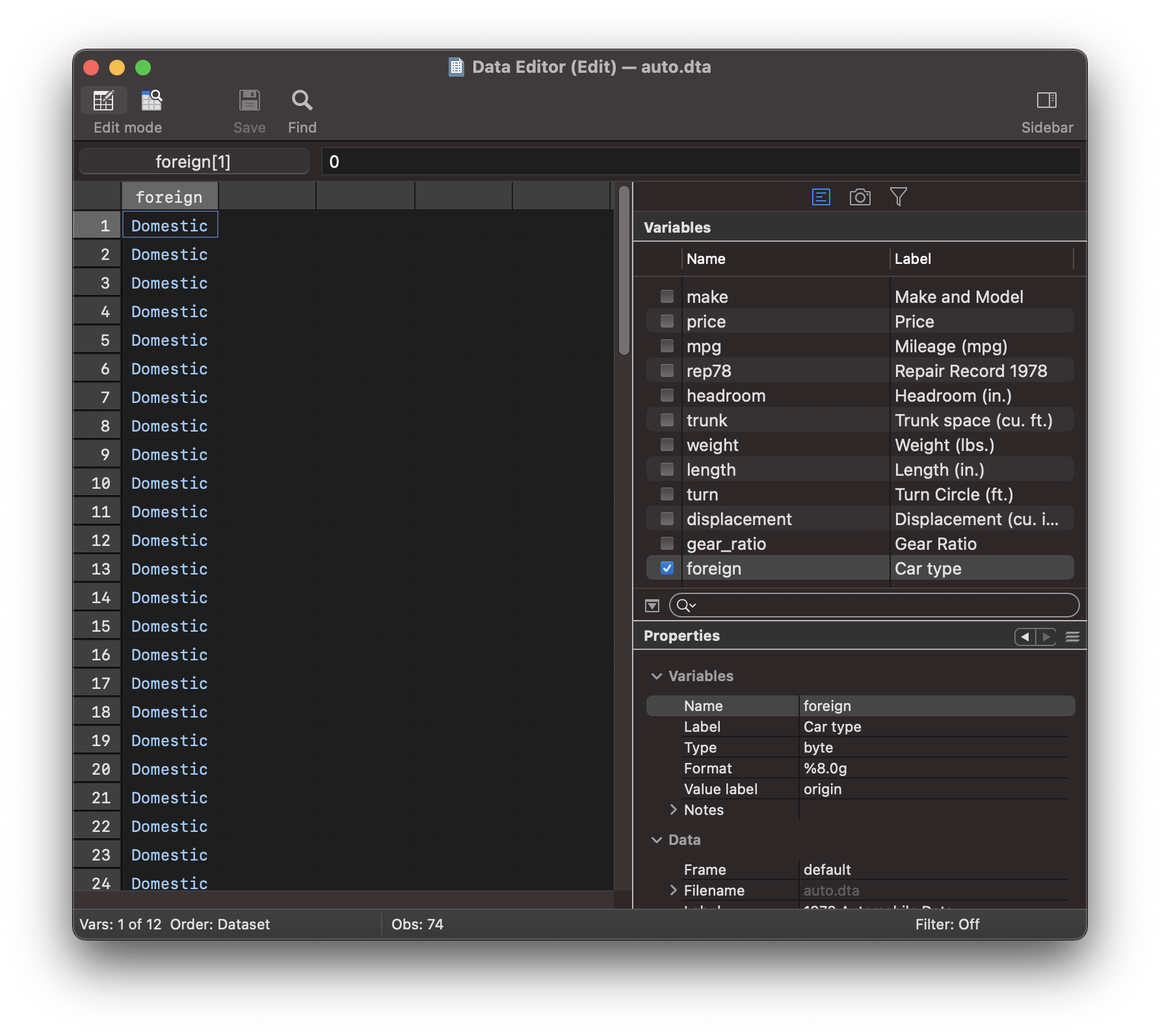
Note
stata has a concept of labels
If you use the data explorer you will see that the foreign variable consists of
0,1 that are associated with labels domestic and foreign (respectively).
We may want to get more information about the get method so the best place
to look is the documentation on sfi.Data.
Then you can click on the get method
Tip
You can’t use the ipython features such as Data.get? in this context because
python is interfacing directly with the python interpreter and not the
ipython interpreter (such as when you’re using jupyter)
That page looks like:
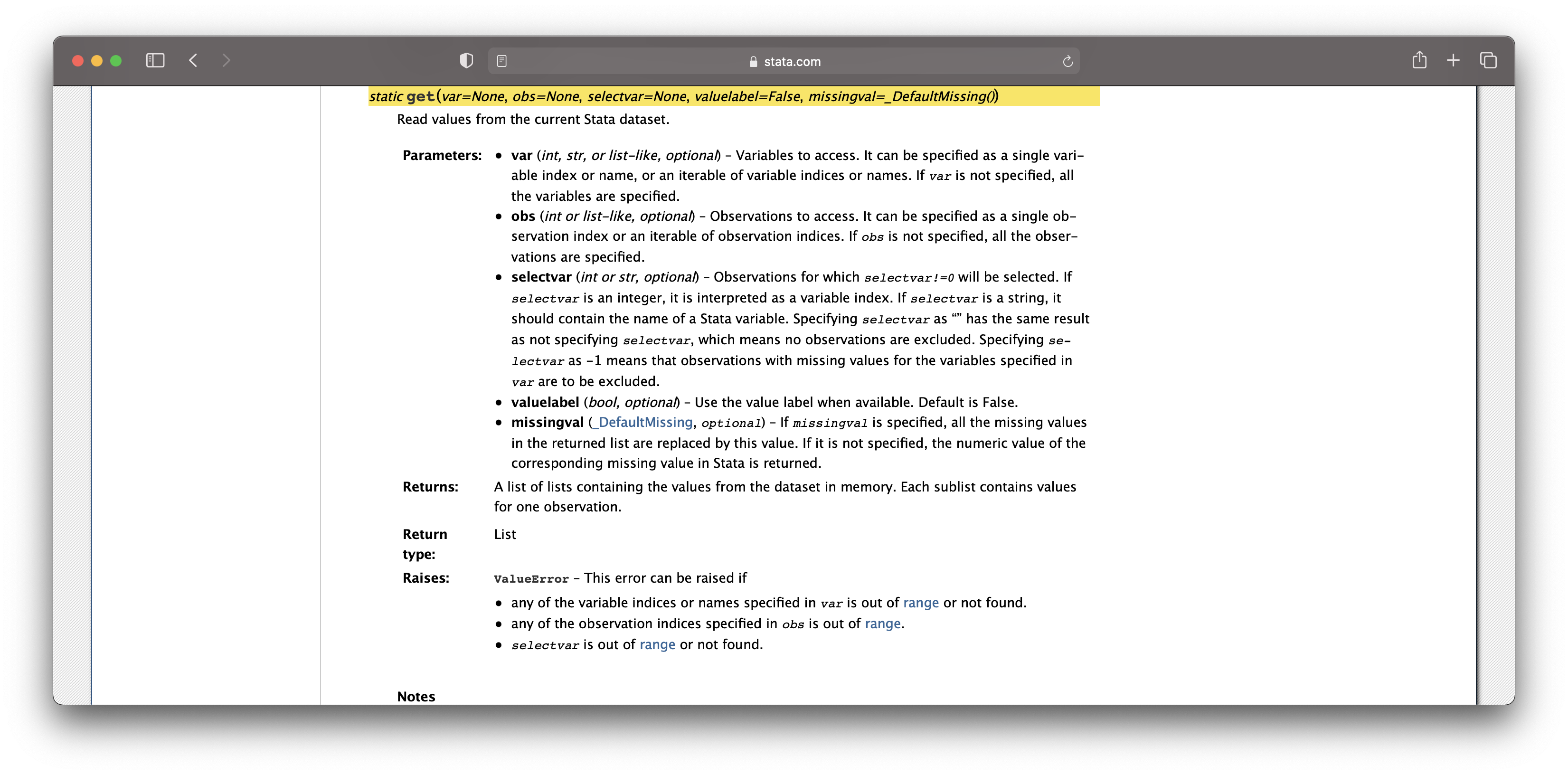
You can see that an option is to fetch the value label using valuelabel=True
python
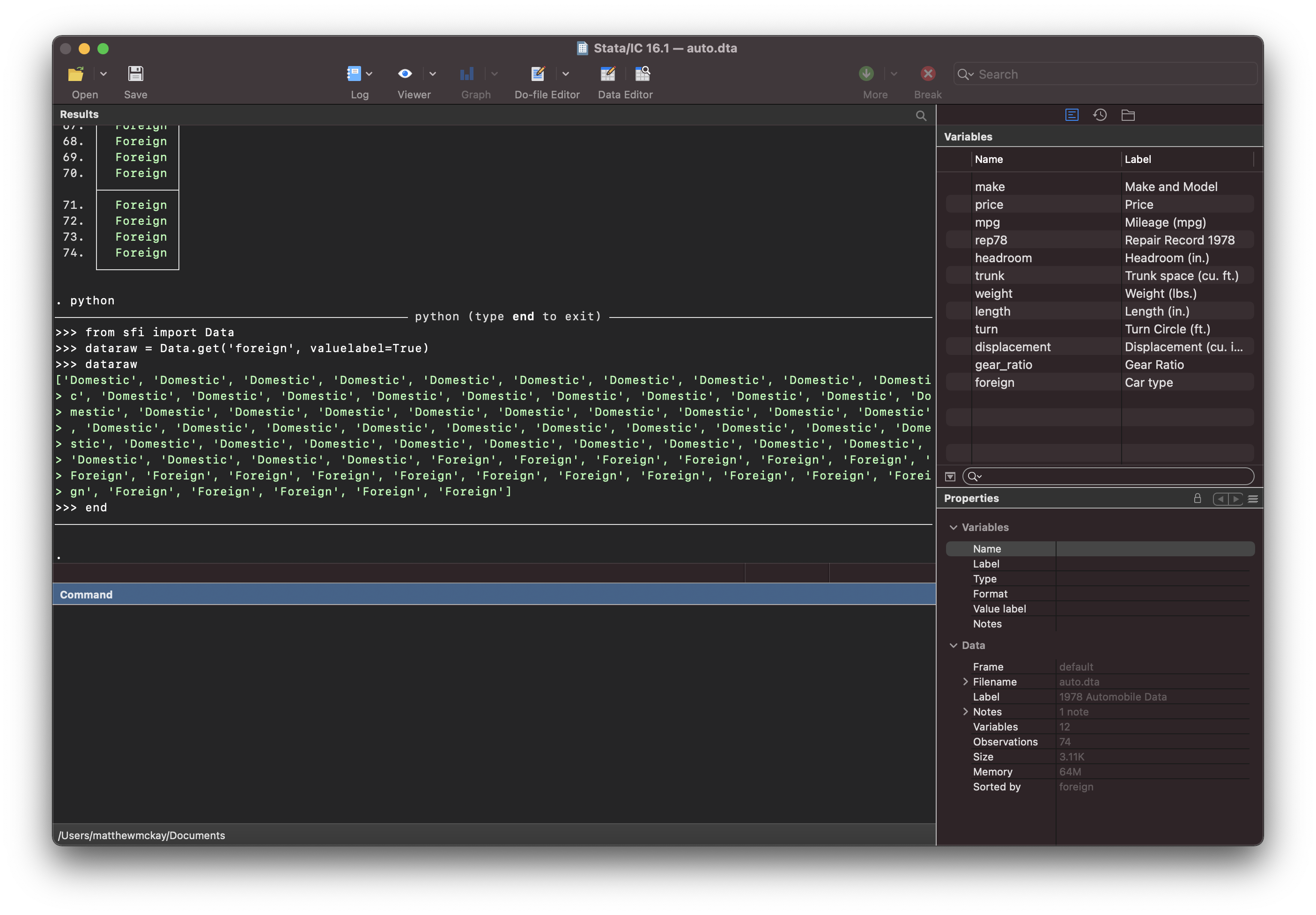
from sfi import Data
dataraw = Data.get('foreign', valuelabel=True)
dataraw
end
and the raw data is now returned as strings taking the value of the labels that
have been applied to the data
Obtaining more variables at once¶
You can obtain more variables using the get method. Based on the documentation you can use
the following methods to specify what variables to fetch:
var (int, str, or list-like, optional) – Variables to access.
It can be specified as a single variable index or name, or an
iterable of variable indices or names. If var is not specified,
all the variables are specified.
In addition you can also specify which observations (obs) you would like:
obs (int or list-like, optional) – Observations to access.
It can be specified as a single observation index or an iterable
of observation indices. If obs is not specified, all the
observations are specified.
So let’s use this information and run
python
from sfi import Data
dataraw = Data.get('foreign mpg rep78', range(45,56))
dataraw
end
this code saves a list of list type object into the python object dataraw

The data is written as a list of rows/obs in the order that the variables are requested,
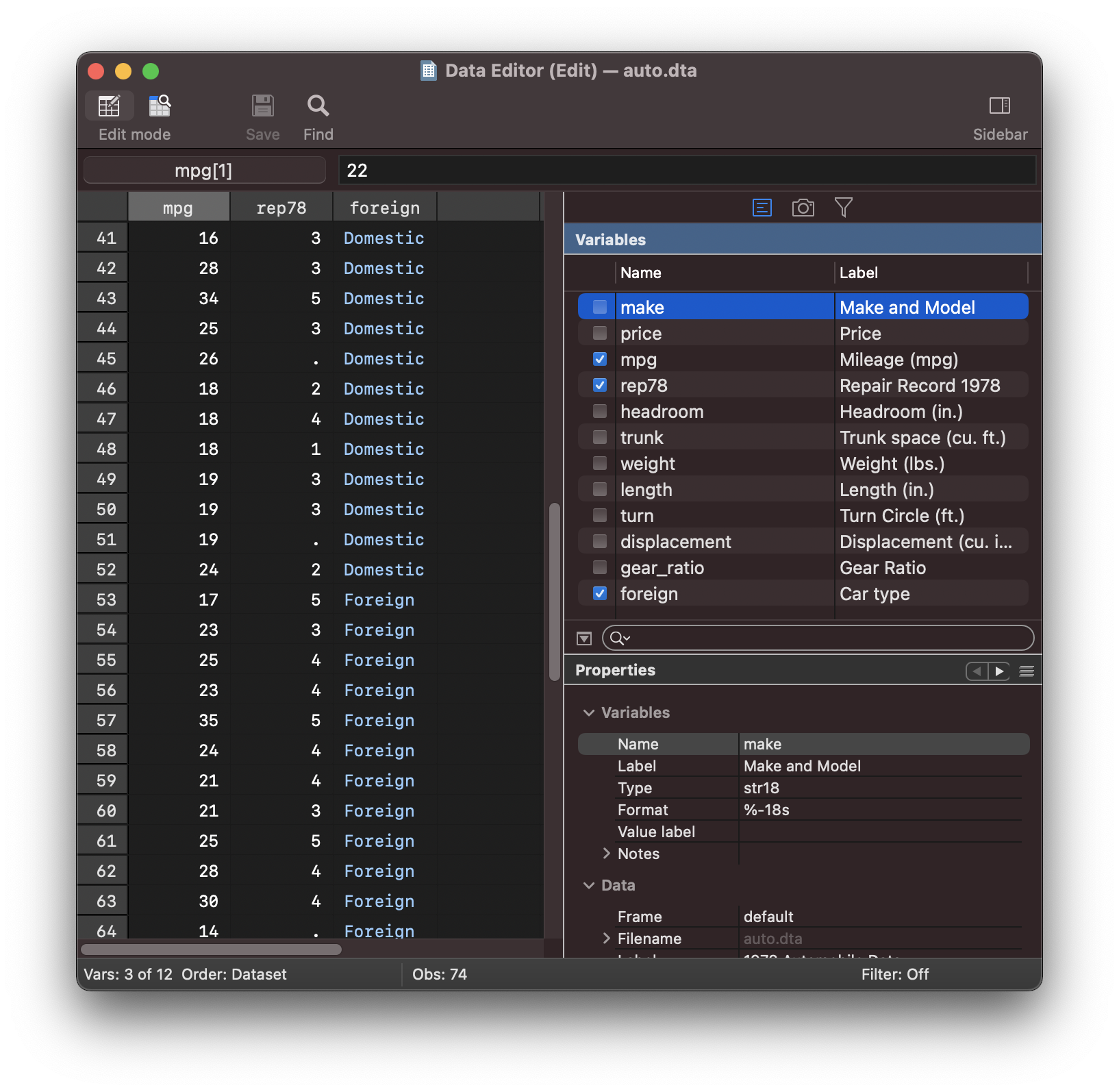
which in this case is: foreign mpg rep78 such as the first element:
[[0, 18, 2], ...
The range(45,56) request will fetch observations 46 to 56 as shown in the data browser
As per the documentation you can also specify a list-like object instead of a string separated
by a space such as ['foreign', 'mpg', 'rep78']:
python
from sfi import Data
dataraw = Data.get(['foreign', 'mpg', 'rep78'], range(45,56))
dataraw
end
which will return the same data

Exercise 2
What happens now if you specify valuelabel=True for the above python
code?
pd.DataFrame and pd.Series:¶
The discussion so far has focused on fetching raw data out of stata and copying
it to the python environment. But in many applications we are likely to want higher
productivity objects such as pandas DataFrame and Series.
Let’s try
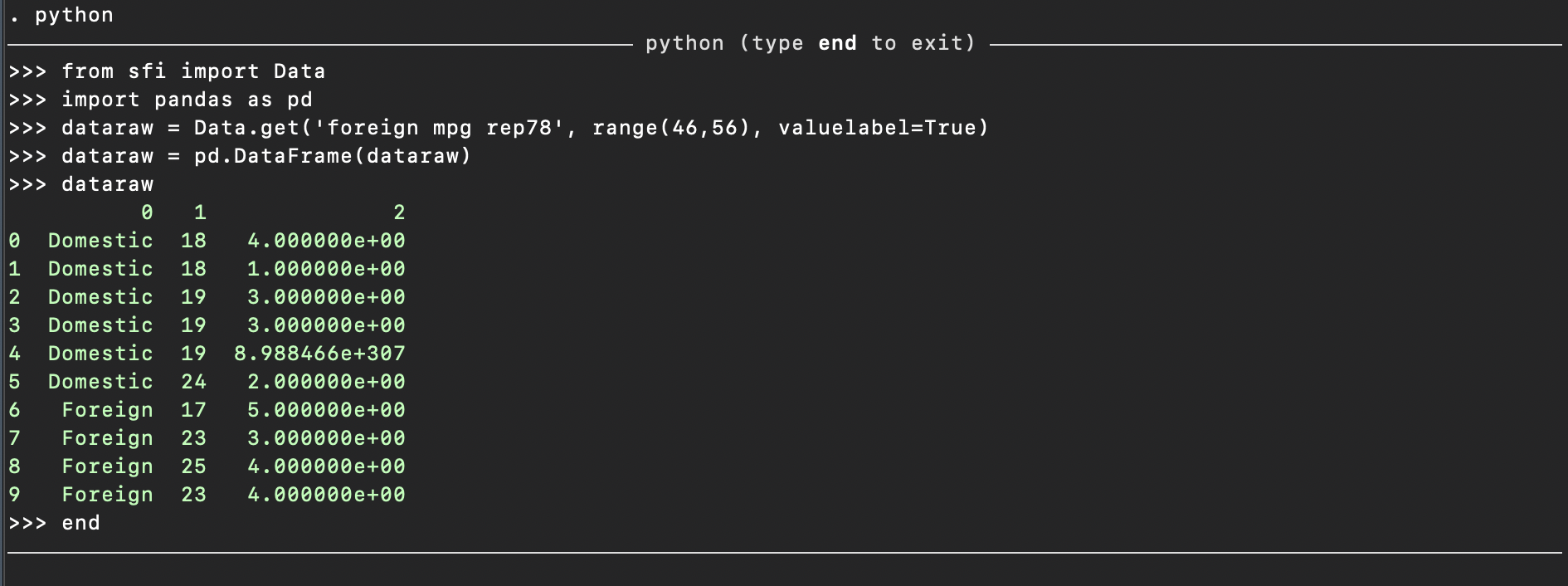
python
from sfi import Data
import pandas as pd
dataraw = Data.get('foreign mpg rep78', range(45,56))
df = pd.DataFrame(dataraw)
df
end
You will notice that the raw data has now been placed in a pd.DataFrame
but columns and index variables haven’t come across:
You may want to parameterize your requests so you can use them in both
the sfi.Data.get method in addition to a pd.DataFrame method when
converting the raw data into a pd.DataFrame
You can save the variable selection as a python variable:
vars = ['foreign', 'mpg', 'rep78']
then you can use these variables for both stata and python
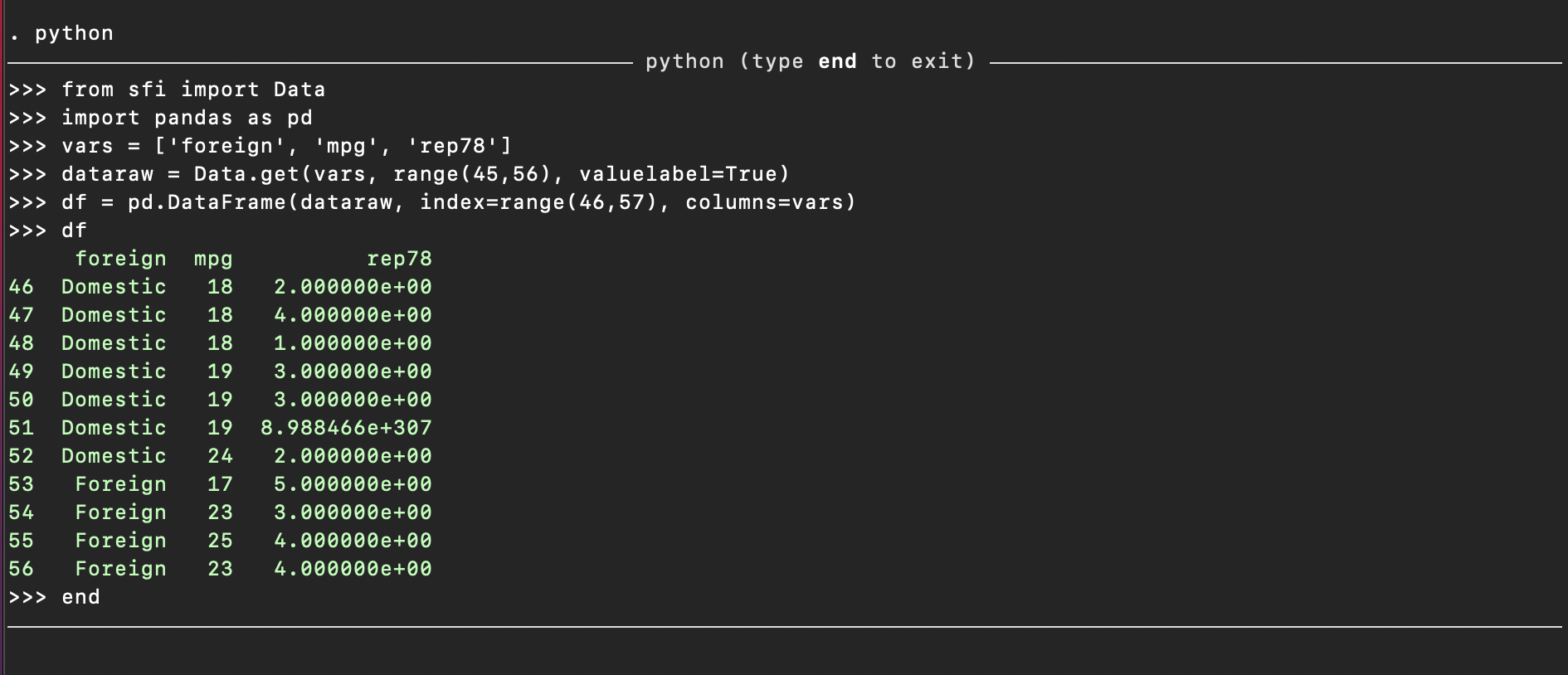
python
from sfi import Data
import pandas as pd
vars = ['foreign', 'mpg', 'rep78']
dataraw = Data.get(vars, range(45,56), valuelabel=True)
df = pd.DataFrame(dataraw, index=range(46,57), columns=vars)
df
end
which provides a much more consistent pd.DataFrame and lines up closely with
the stata context.
You can compare with stata using in the command window
list foreign mpg rep78 in 46/56
Exercise 3
How can you explain the value for the variable rep78 for observation 51?
Note
There is also a method available sfi.Data.getAsDict() that includes the
variable names in a returned dictionary so you can use:
python
from sfi import Data
import pandas as pd
vars = ['foreign', 'mpg', 'rep78']
dataraw = Data.getAsDict(vars, range(45,56), valuelabel=True)
df = pd.DataFrame(dataraw)
df
end
Missing Values:¶
Missing values in stata are internally represented by the largest value for
each type.
Within stata you typically work with missing values using . such as:
list rep78 if rep78 != .
and much of this detail is taken care of for you.
AS missing values are represented by the maximum value:
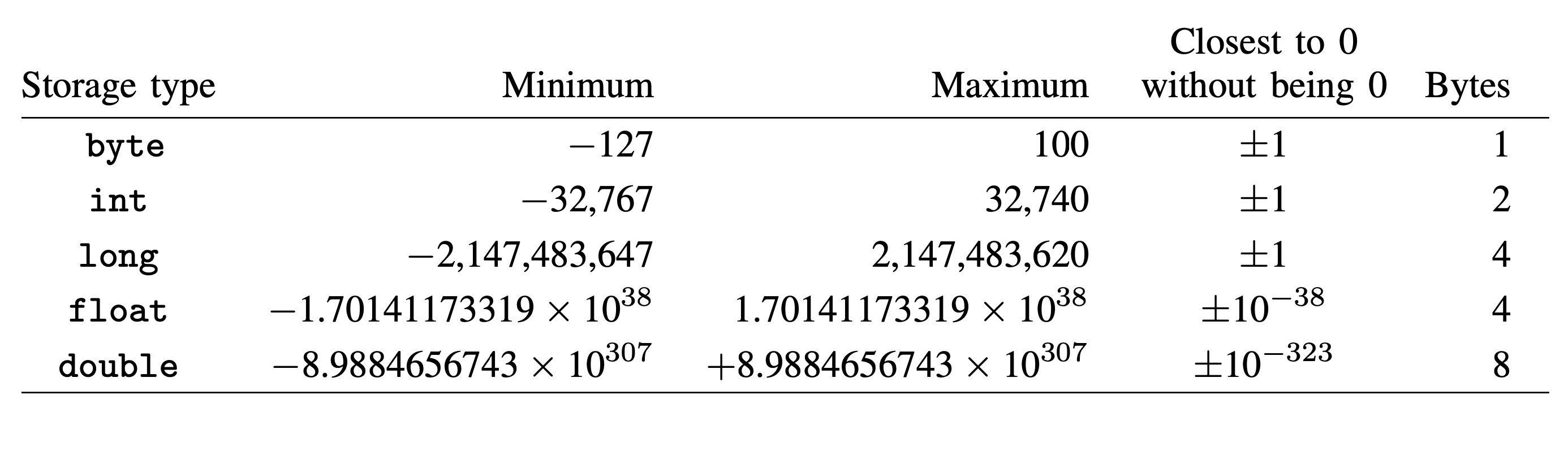
python will interpret this data as an actual value.
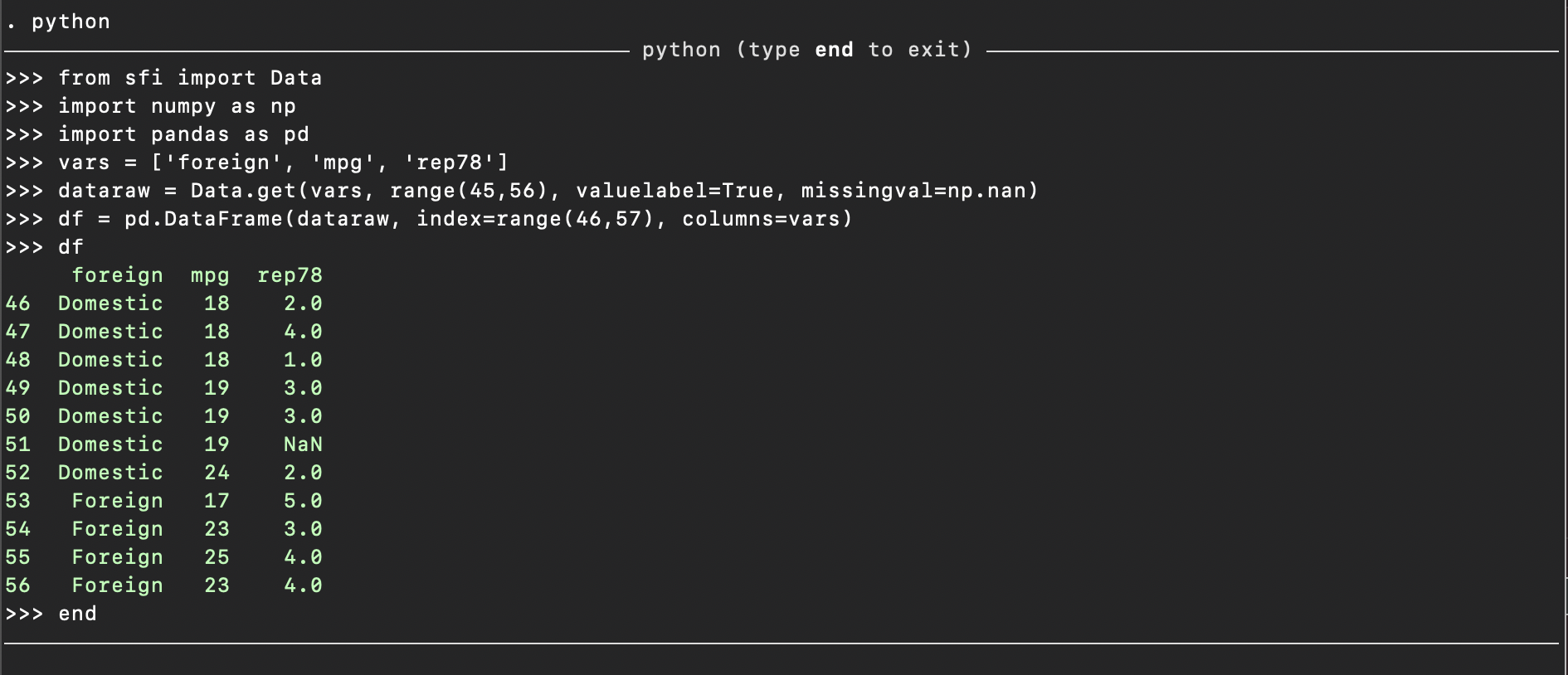
You will want to specify missingval=np.nan
python
from sfi import Data
import numpy as np
import pandas as pd
vars = ['foreign', 'mpg', 'rep78']
dataraw = Data.get(vars, range(45,56), valuelabel=True, missingval=np.nan)
df = pd.DataFrame(dataraw, index=range(46,57), columns=vars)
df
end
which returns the following
Copying Data from Python to Stata¶
Stata Blog Post
This section is heavily inspired by this excellent stata blog post
It is often the case you will want to do some data work in python and have a need to
transfer it to stata to do some statistical anaylsis.
The sfi.Data interface also contains methods for saving data from python into
the default stata dataframe (or a frame which is new in Stata16)
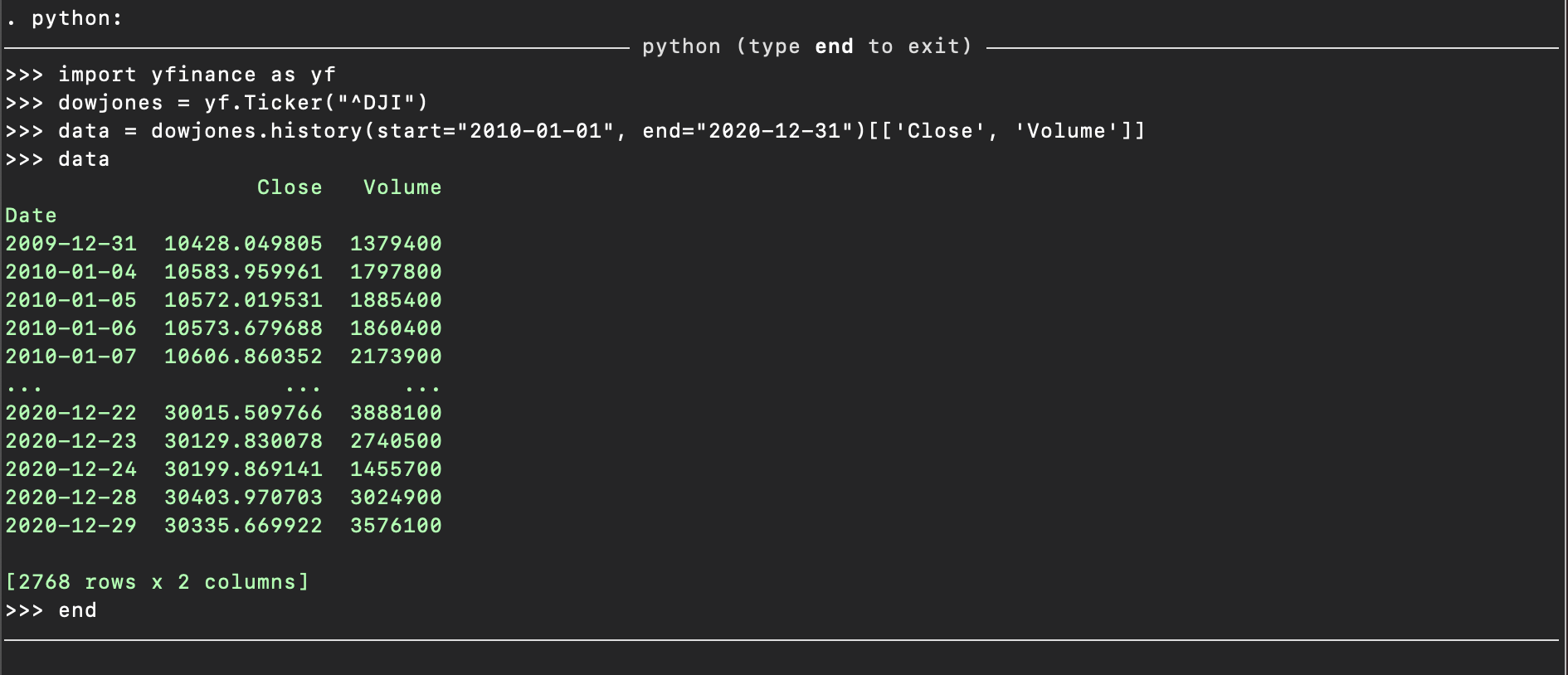
Let us fetch some data from Yahoo Finance using the yfinance package in python
python:
import yfinance as yf
dowjones = yf.Ticker("^DJI")
data = dowjones.history(start="2010-01-01", end="2020-12-31")[['Close', 'Volume']]
data
end
the yfinance package has returned the dowjones history tables containing data
between 2010-01-01 and 2020-12-31
Now we need to migrate that data from python into stata
python:
from sfi import Data
Data.setObsTotal(len(data))
end
the stata data editor now contains space for len(data) observations to
be transferred.
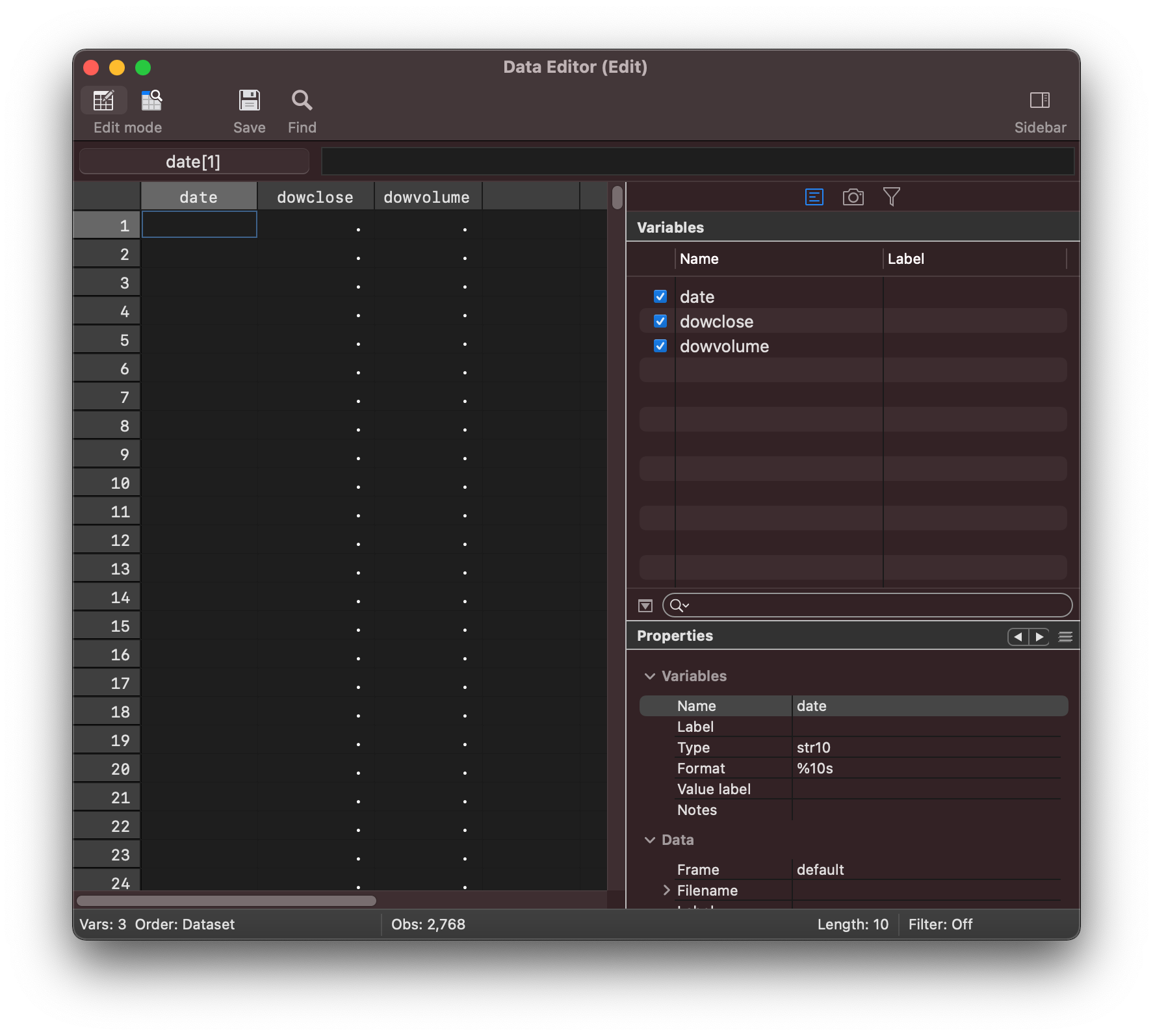
You can then setup 3 variables in stata to save date, close,
and volume information across.
python:
Data.addVarStr("date", 10) # Str10
Data.addVarDouble("close") # Double
Data.addVarInt("volume") # Int
end
the stata data editor now contains 3 variables
Warning
You should start this work with an empty stata dataset. The sfi.Data
package can return some cryptic errors. When trying to create a date
Str variable using the code above you will get the following error if the
variable already exists in the dataset.
>>> Data.addVarStr("date", 10)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Applications/Stata/ado/base/py/sfi.py", line 487, in addVarStr
return _stp._st_addvarstr(name, length)
SystemError: failed to add a variable of type str to the current Stata dataset
r(7102);
Clearing can be done in stata using
clear
The next step is to migrate the actual data.
You might try saving the data directly from the pandas dataframe into the stata dataset using the
sfi.Data.store() method.
Note
This method interface is expecting
static store(var, obs, val, selectvar=None)
where,
var,obs, andvalarepython arguments, andselectvar=Noneis apython keyword argumentwith a default value ofNone
This means that var, obs, and val are required inputs
This deviates from sfi.Data.get()
python
Data.store("date", None, data.index)
end
however you will run into trouble with the following error:

Stata is similar to numpy in that it is very specific about how it saves data in memory in
accordance with specified types.
In the code above we tried to send through a list of datetime objects from
pandas and the stata function interface doesn’t know how to represent
this data in the stata dataset.
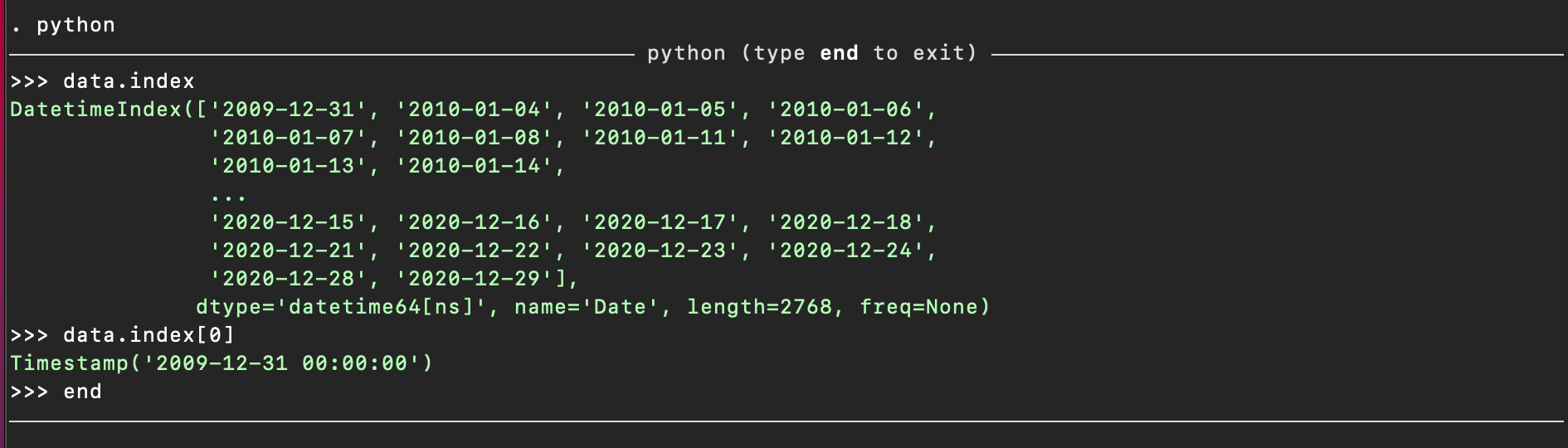
python
data.index
data.index[0]
end
As you can see the index from the pandas dataframe data consists of Timestamp objects:
Therefore some translation is required in this case to convert dates into a format that stata
can copy into its dataset and then use stata tools to convert to stata dates.
We know stata has a date function that we can use:
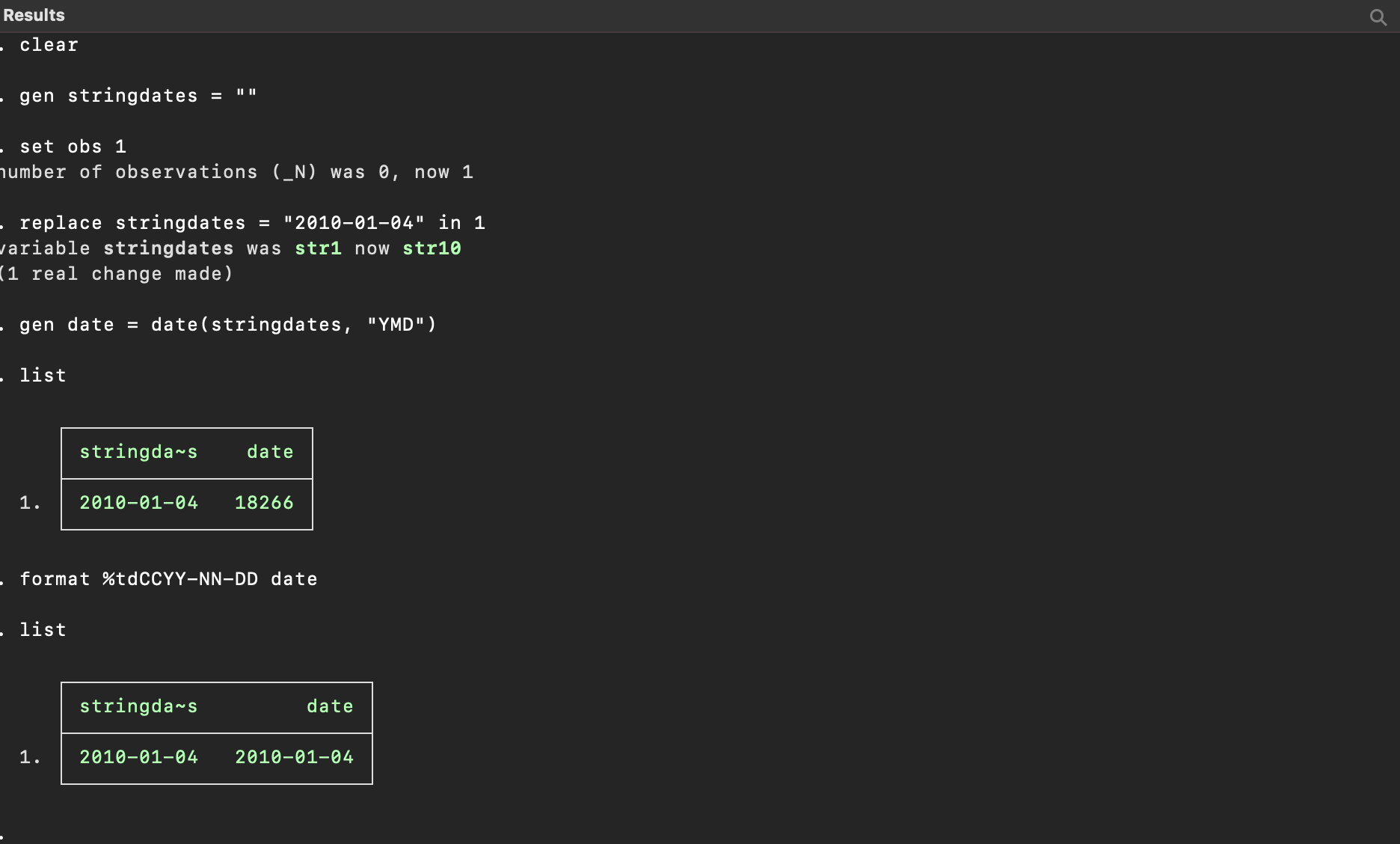
clear
gen stringdates = ""
set obs 1
replace stringdates = "2010-01-04" in 1
gen date = date(stringdates, "YMD")
list
format %tdCCYY-NN-DD date
list
So now we can look to convert the pandas.Timestamp objects to be represented as simpler string
based data that contain the information needed for stata to convert those dates.
Pandas has a useful method .astype() for useful data conversions.
python
data.index = data.index.astype(str)
data.index[0]
end
.png)
this has used the in-built type converter to represent the index as strings
that is formatted as YYYY-MM-DD
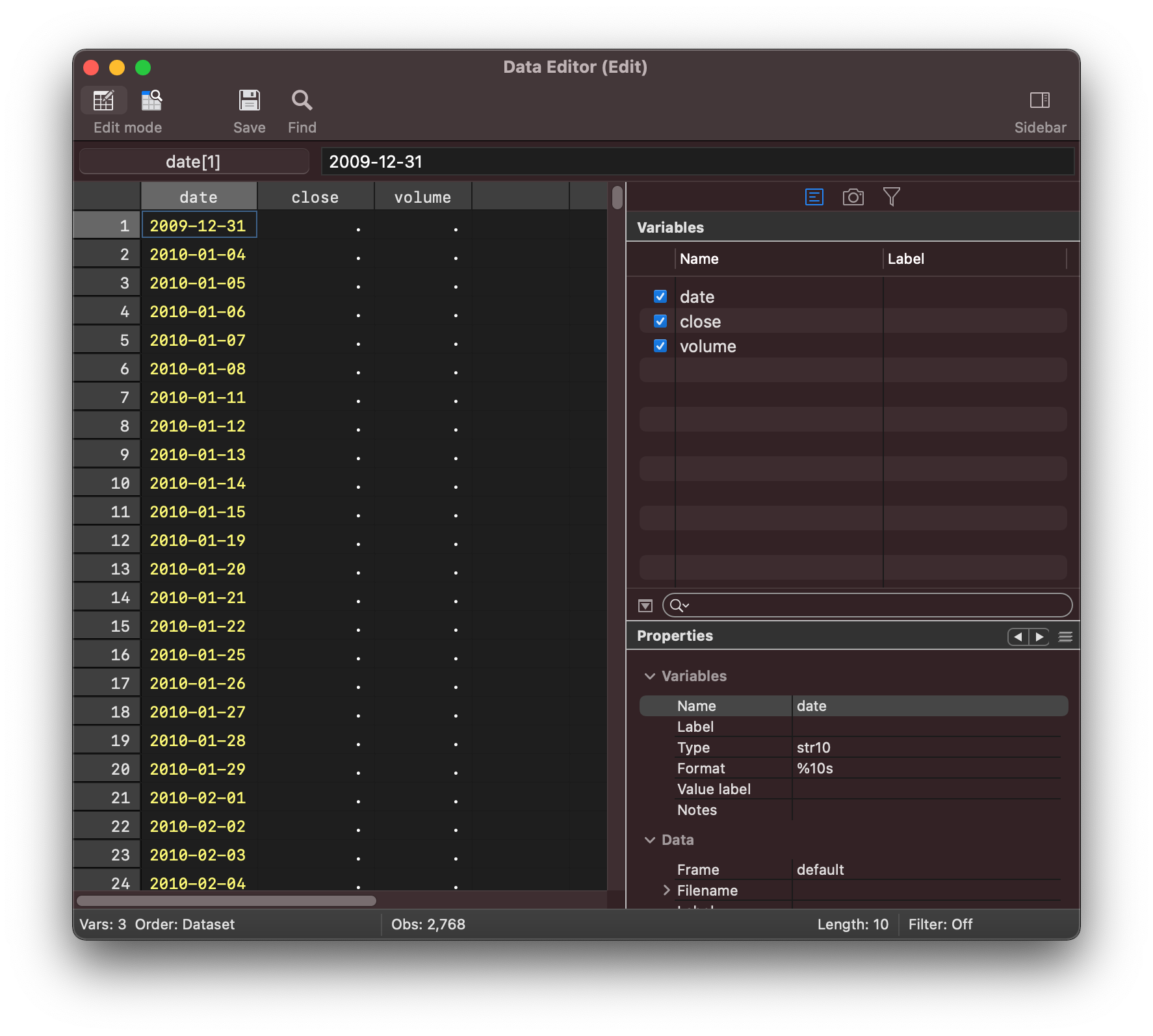
Now lets try and save this information into the stata dataset:
python
Data.store("date", None, data.index)
end
You can now open the data viewer and see that the dates (as strings) has been copied
over to stata:
Let’s bring in the numerical data, which is a much simpler process
python
Data.store("close", None, data.Close)
Data.store("volume", None, data.Volume)
end
We now have the data we need in the stata dataset as seen in the data editor
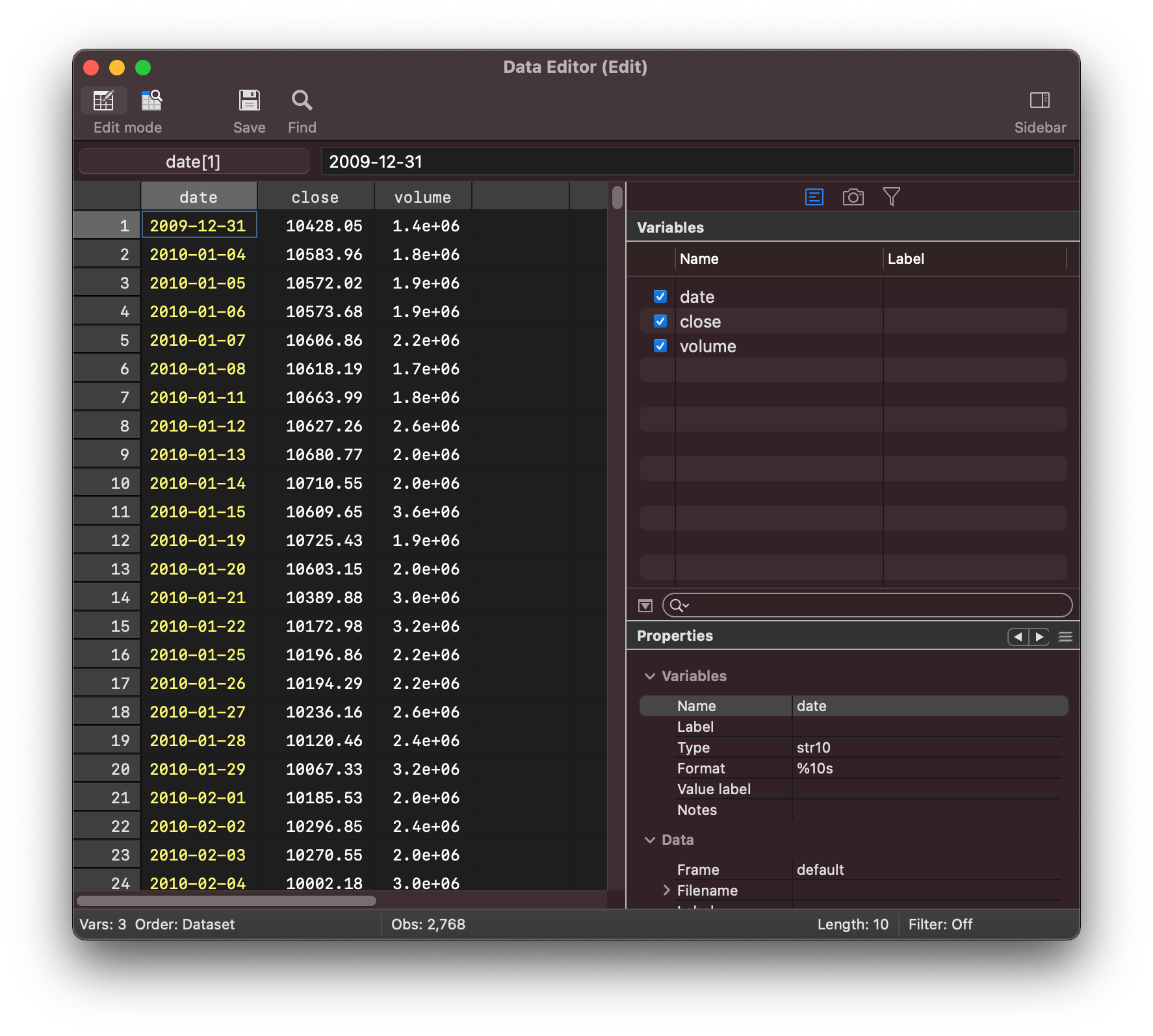
Now that the data is copied across we can switch back to stata to run
any analysis or construct a plot
We will first want to convert those dates in stata as a post transfer step
gen sdate = date(date, "YMD")
format %tdCCYY-NN-DD sdate
and we can check the conversion in the stata data editor
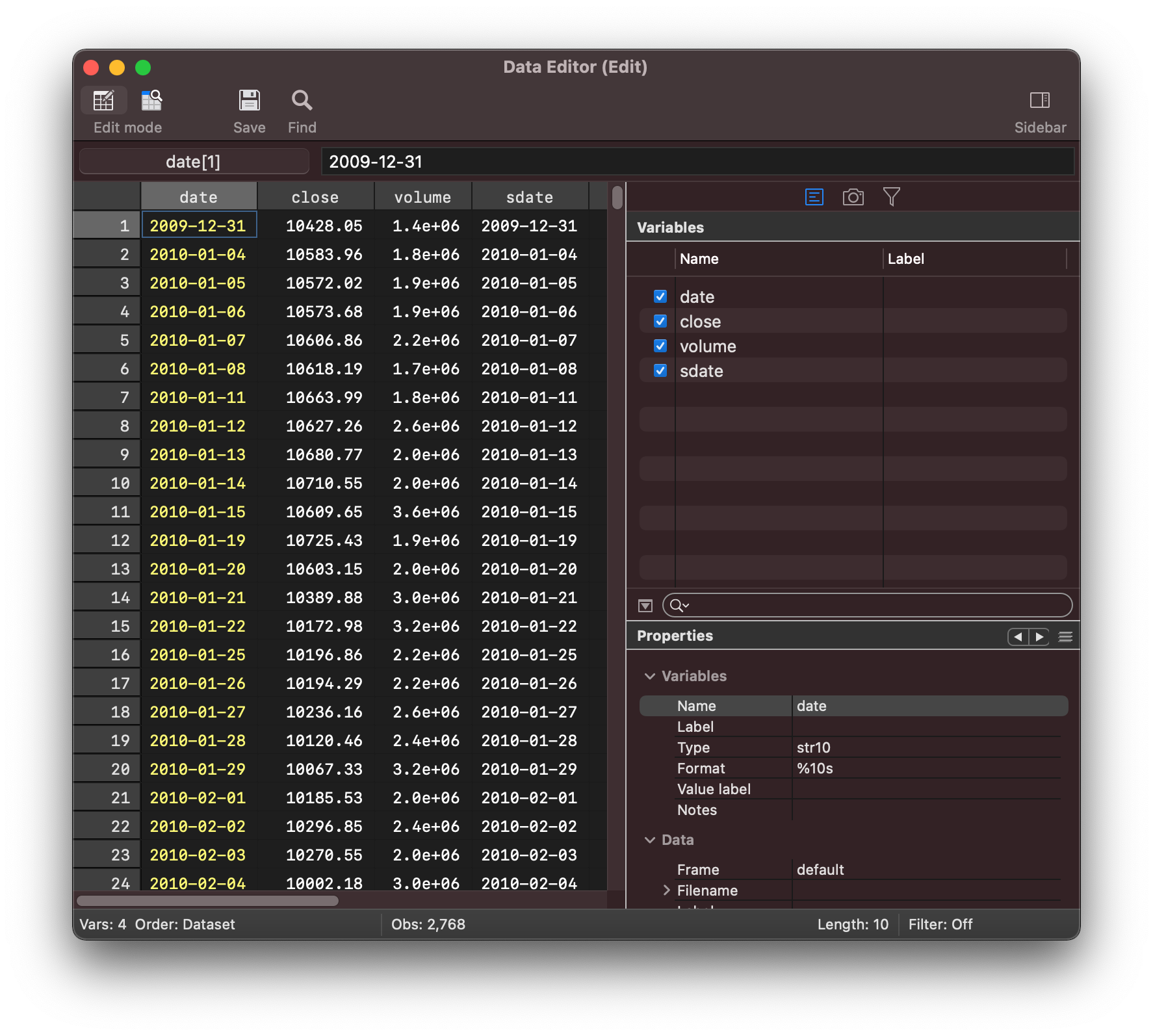
and then we can construct the plot as demonstrated in the original blog post
replace volume = volume / 1000000
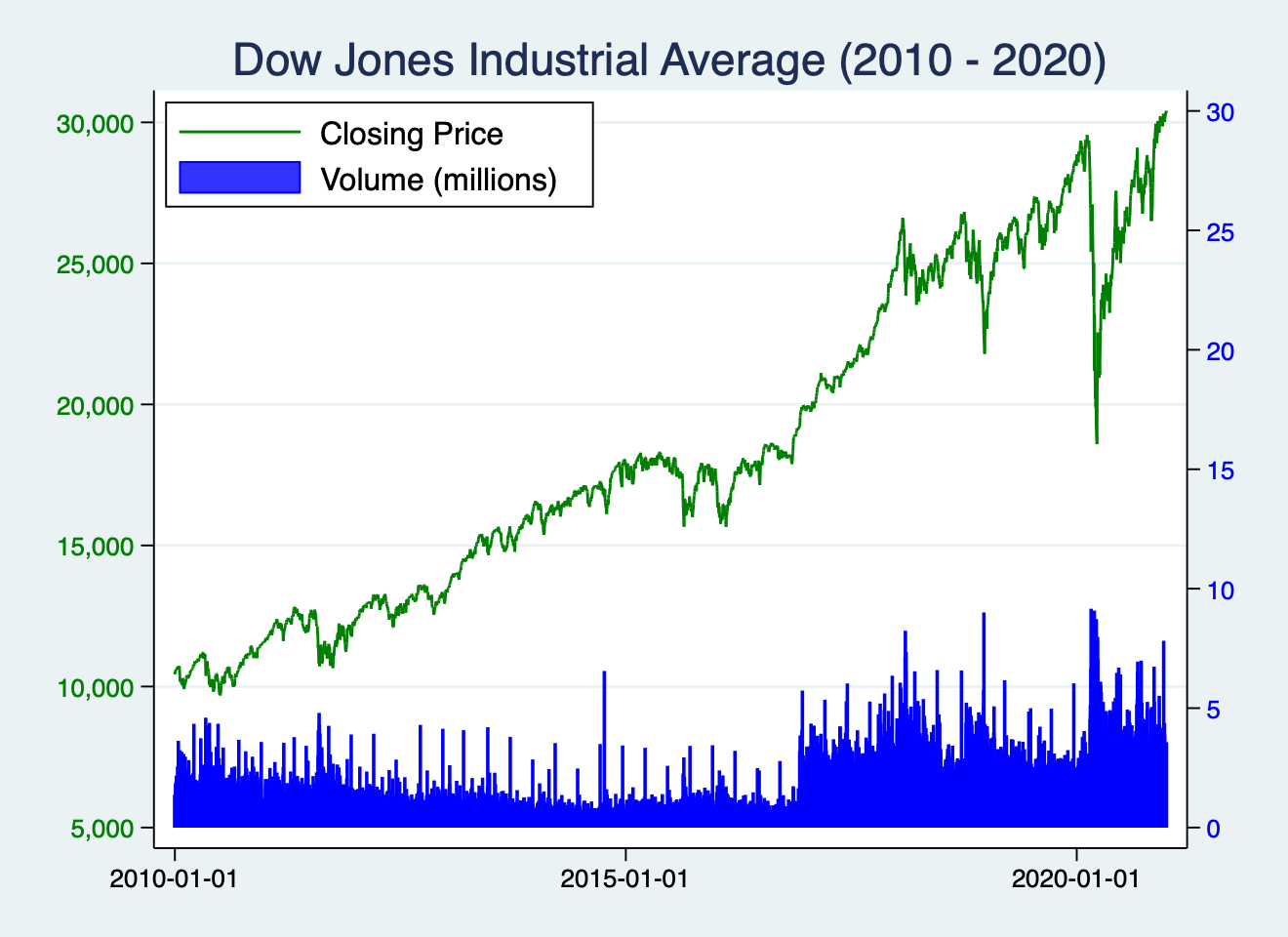
twoway (line close sdate, lcolor(green) lwidth(medium)) ///
(bar volume sdate, fcolor(blue) lcolor(blue) yaxis(2)), ///
title("Dow Jones Industrial Average (2010 - 2019)") ///
xtitle("") ytitle("") ytitle("", axis(2)) ///
xlabel(, labsize(small) angle(horizontal)) ///
ylabel(5000(5000)30000, ///
labsize(small) labcolor(green) ///
angle(horizontal) format(%9.0fc)) ///
ylabel(0(5)30, ///
labsize(small) labcolor(blue) ///
angle(horizontal) axis(2)) ///
legend(order(1 "Closing Price" 2 "Volume (millions)") ///
cols(1) position(10) ring(0))
which produces the following stata chart
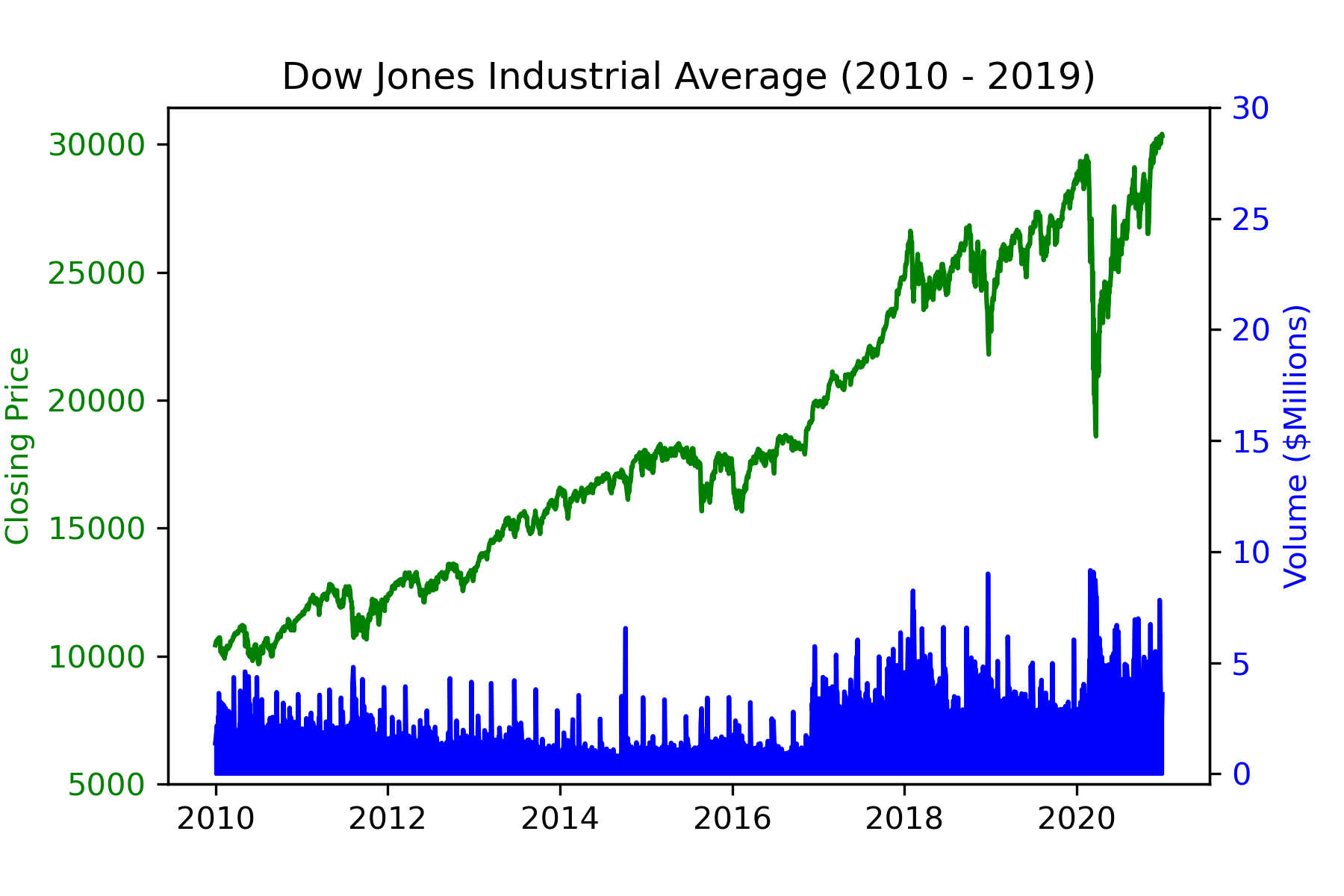
You may be interested in comparing this to a chart built with matplotlib and pandas
in the python environment.
You can download this notebook,
or open this notebook in the cloud
which produces the following matplotlib figure:
Persistence between python code-blocks in stata¶
Once the python interpreter is initialised it is used throughout the stata
session.
This means that once variables are created in python they will be
available in future python code-blocks.
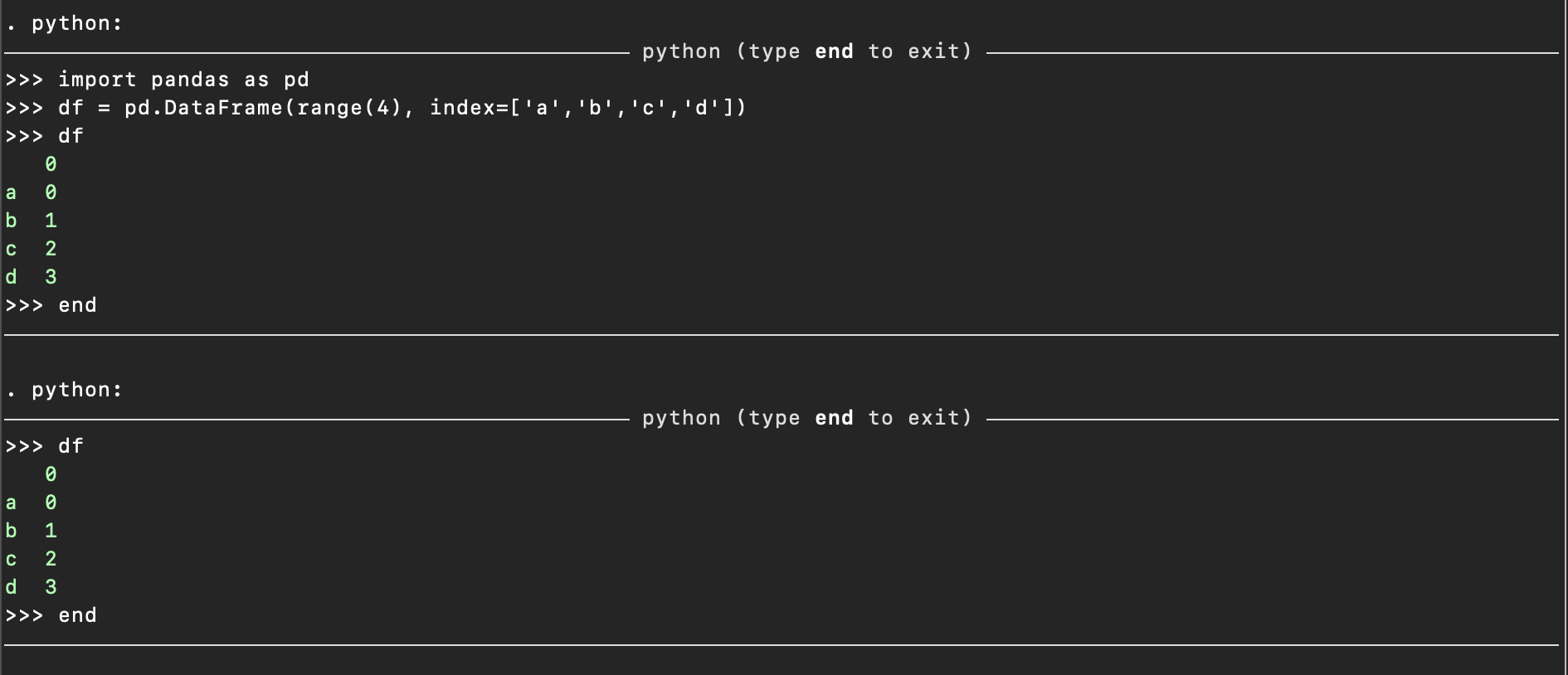
python:
import pandas as pd
df = pd.DataFrame(range(4), index=['a','b','c','d'])
df
end
then you can run some other things in stata and then return to python and fetch
the df object
python:
df
end
such as in this short demonstration
The stata function interface sfi¶
The python api documentation contains
the details about the sfi package from stata.
Class |
Description |
|---|---|
Access |
|
Access to the current |
|
Access to |
|
Access to |
|
Access to |
|
An interface with global |
|
Access to |
|
Access to |
|
Access to |
|
Access to |
|
a set of |
|
Provide access to |
|
Access to |