File based Workflows¶
In many cases it can be convenient to keep stata and python
workflows largely independent of each other and use files to
transfer data back and forth such as:
Dataset Construction (Python)
Statistical Modelling (Stata)
or vice-versa.
Note
If data needs to be computed regularly due to updates in source files.
The python script interface in stata is useful here as it can
be used to update data using a python script, saving the update data
to a new dta file and then running any regressions in stata.
The support for using a file based workflow is provided by pandas
as it has an interface for reading and writing dta files.
Pandas: Reading dta files¶
The documentation on pd.read_stata() is a good resource.
Let’s fetch the auto dataset provided by stata and save it as
a dta file.
sysuse auto
save "auto.dta"
You can view this dataset in the data reader
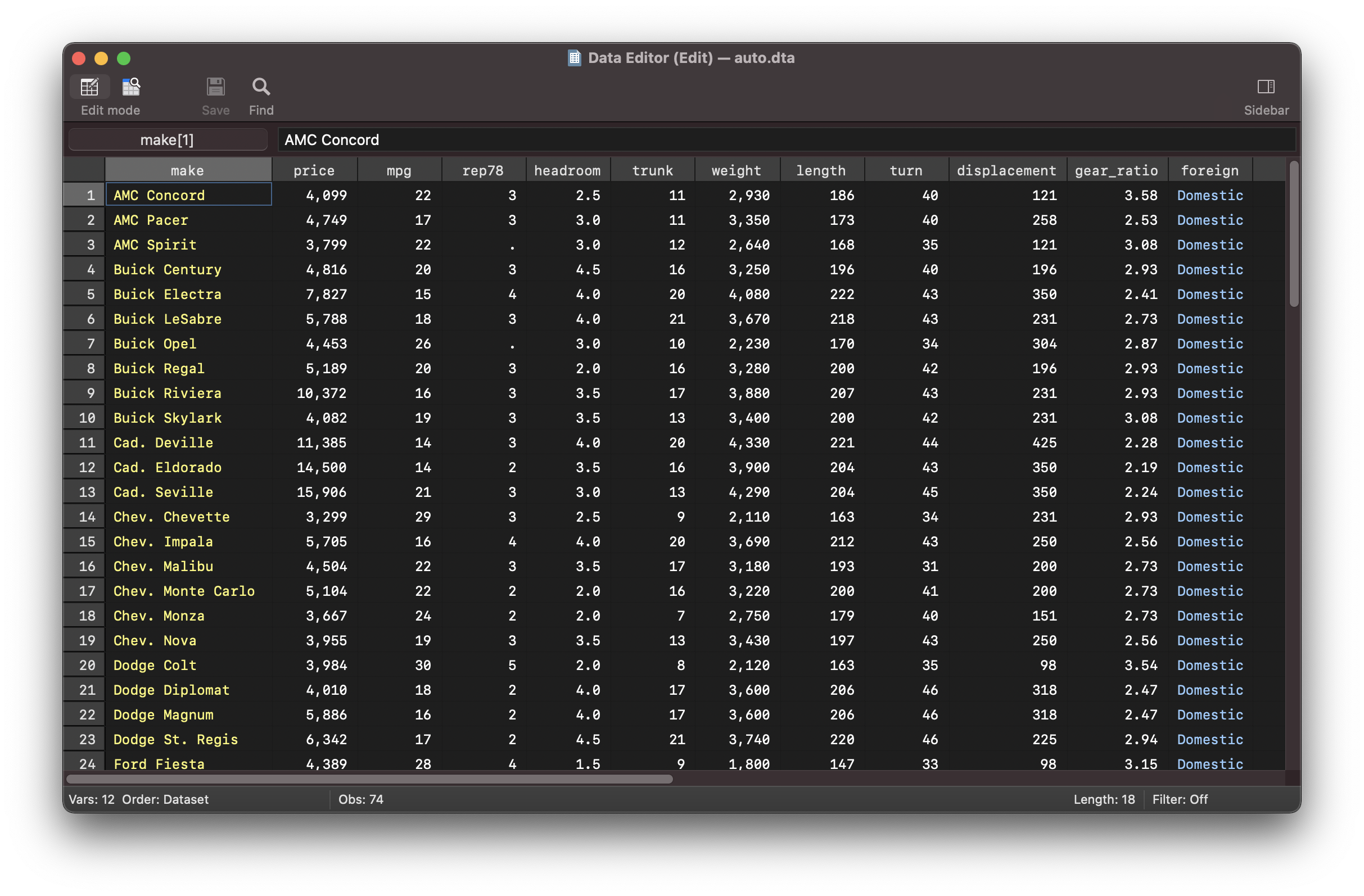
In stata this dataset consists of the following types:
Variables |
Data Type |
Label |
|---|---|---|
make |
str18 |
Make and Model |
price |
int |
Price |
mpg |
int |
Mileage (mpg) |
rep78 |
int |
Repair Record 1978 |
headroom |
float |
Headroom (in) |
trunk |
int |
Trunk space (cu. ft.) |
weight |
int |
Weight (lbs) |
length |
int |
Length (in.) |
turn |
int |
Turn Circle (ft.) |
displacement |
int |
Displacement (cu. in.) |
gear_ratio |
float |
Gear Ratio |
foreign |
byte |
Car Type |
Where foreign is labelled data represented by 0/1 with labels:
0=Domestic1=Foreign
Let us now read this dta file into python using pd.read_stata()
Open a jupyter notebook and then import the data such as:
import pandas as pd
auto = pd.read_stata("auto.dta")
auto
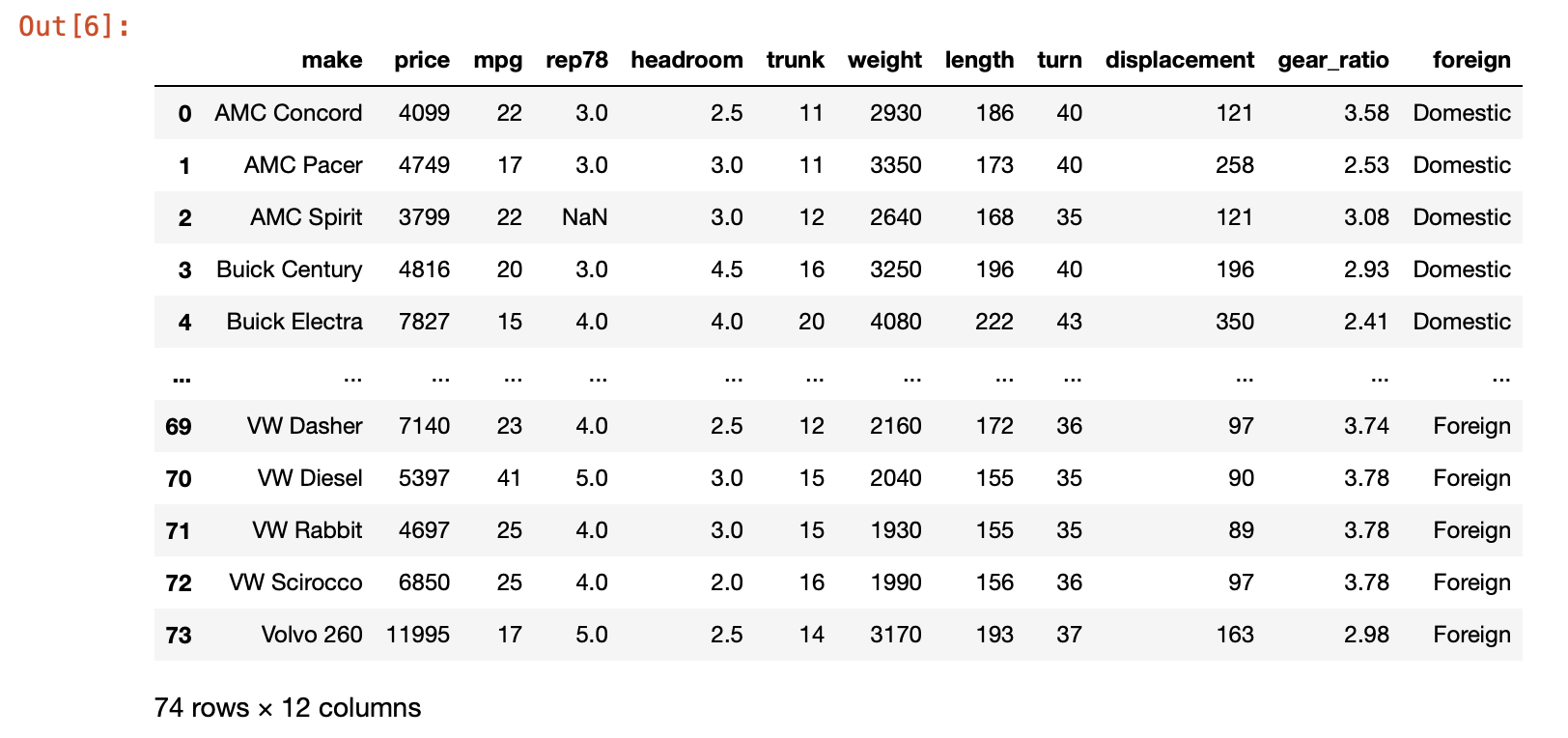
The data types reported by auto.dtypes show that pandas has done a good job of fetching
the data faithfully from the stata dta file.
auto.dtypes
produces the following list:
make object
price int16
mpg int16
rep78 float64
headroom float32
trunk int16
weight int16
length int16
turn int16
displacement int16
gear_ratio float32
foreign category
dtype: object
Pandas: Writing dta files¶
Tip
You can also write other data file formats if you have trouble
with the dta writer, such as csv, xlsx. However you often loose
information in this process and you may need to think about dtypes during this
translation process between formats in a similar way as when migrating the raw data
via the stata function interface.
You can write to dta file format using pd.DataFrame.to_stata() method associated with pd.DataFrame.
import yfinance as yf
dowjones = yf.Ticker("^DJI")
data = dowjones.history(start="2010-01-01", end="2020-12-31")[['Close', 'Volume']]
data.to_stata("yfinance-dji.dta")
Note
It is also possible to write these dta files from within a stata python program
such as:
python:
import yfinance as yf
dowjones = yf.Ticker("^DJI")
data = dowjones.history(start="2010-01-01", end="2020-12-31")[['Close', 'Volume']]
data.to_stata("yfinance-dji.dta")
end
use yfinance-dji.dta, clear
or alternatively running a python script
This will save a dta file that can be opened with stata and viewed
in the data editor
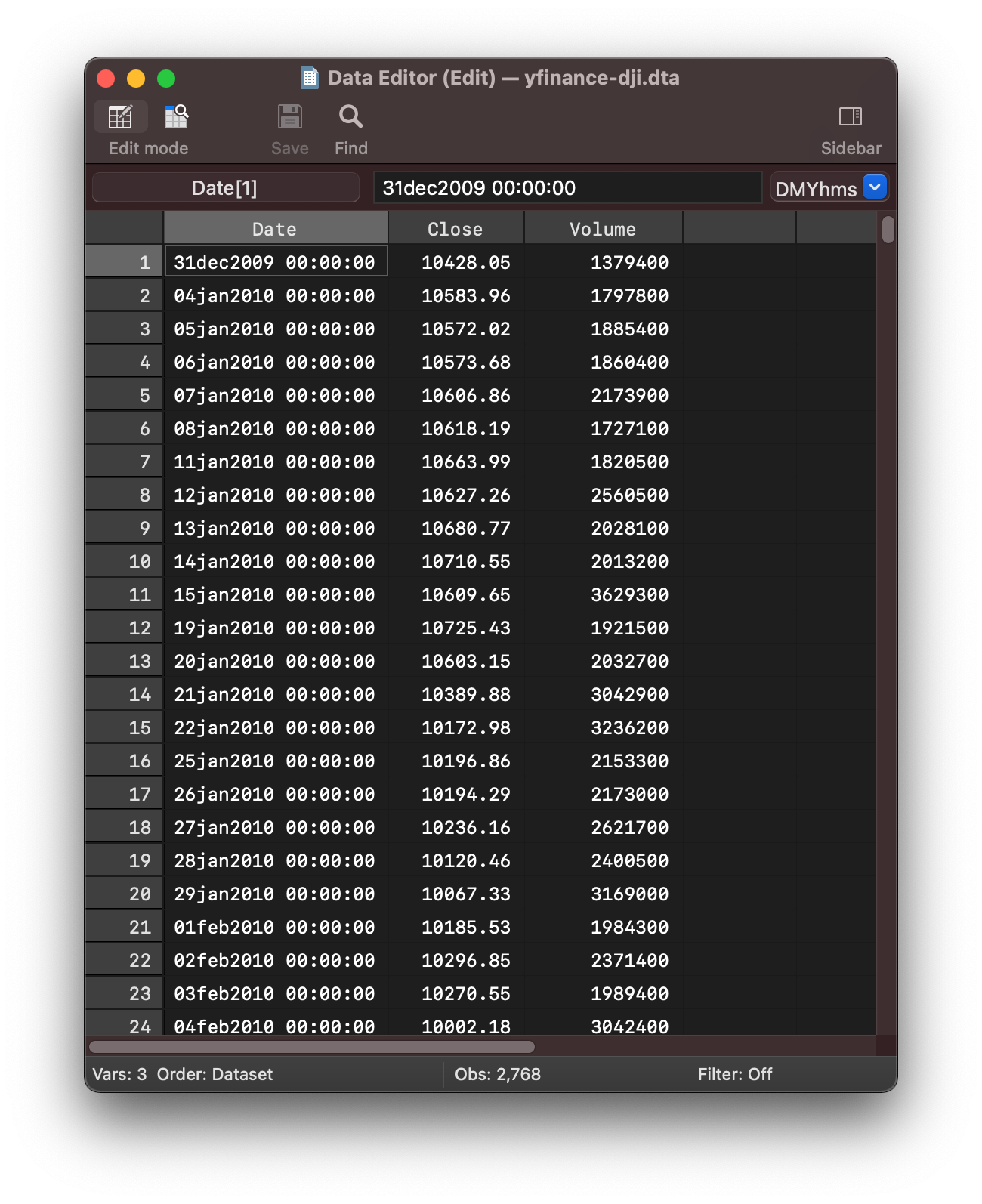
In python if you run
data.index[0]
you will see the index is constructed of Timestamp objects
Timestamp('2009-12-31 00:00:00')
These objects have been transferred for you into stata date variables as tc.
You can now format this data straight away which is convenient as it reduces the
amount of translation you need to think about.
format %tcCCYY-NN-DD Date
The data viewer now consists of nicely formatted dates
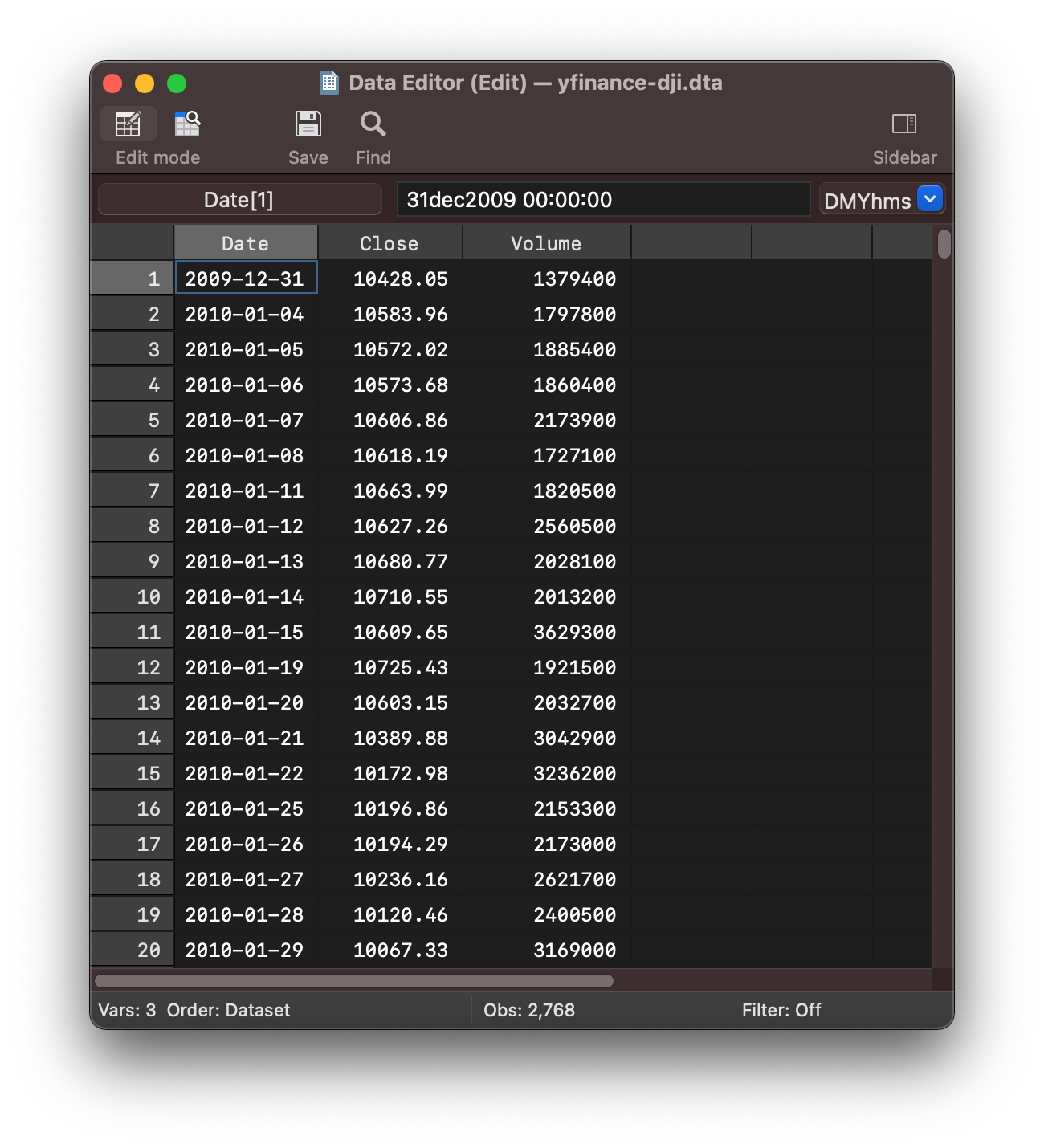
You may notice the default datetime object has been translated nicely but pandas
has used stata tc format (by default) as per the documentation.
We can specify td dates using the convert_dates= keyword argument and specifying the column
and which datetime conversion to use such as:
python:
data = data.reset_index()
data.to_stata("yfinance-dji2.dta", convert_dates={'Date' : 'td'})
end
Errors you can come across writing dta files¶
The pandas object is more general than the stata dta format so there are cases where
the data can’t be written to dta format.
Let’s use the following pd.DataFrame to look at this issue:
import pandas as pd
data = {
'a' : [pd.Series([1,2,3]), pd.Series([4,5,6])],
'b' : [[1,2,3],[4,5,6]],
'c' : [1,2],
}
data = pd.DataFrame(data)
you will get a DataFrame that looks like the following (and associated dtypes)
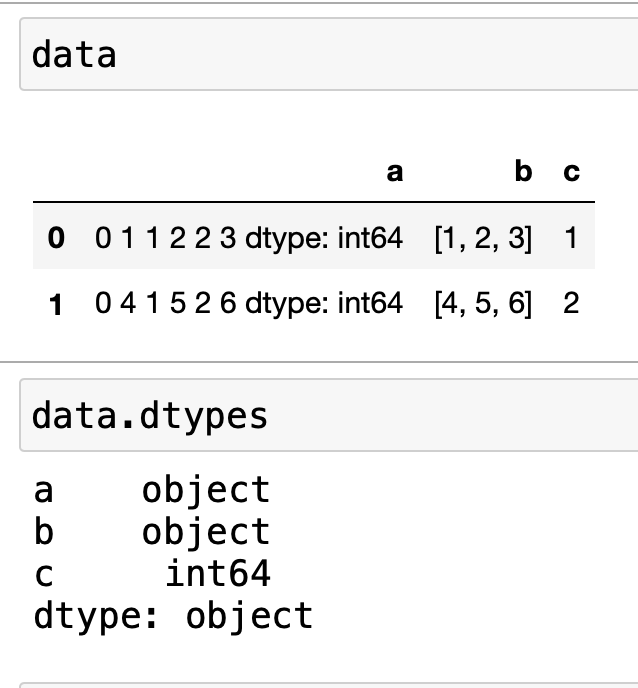
As you can see the first column consists of pd.Series objects. The pandas DataFrame is
capable of storing any python object as elements in a general column dtype=object
To get the first element of column a you can use
data['a'][0]
which displays the object which is a pd.Series
0 1
1 2
2 3
dtype: int64
Note
In practice, when working with data, this is not very common but I wanted to
demonstrate that the pd.DataFrame object is capable of storing complex data types.
If you now try and write this dataframe to disk using the to_stata() method you
will get a ValueError as there is no way to store the pd.Series objects in column
a int a dta file.
data.to_stata("test.dta")
you will get the following Traceback
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-28-43f621af9c2f> in <module>
----> 1 data.to_stata("test.dta")
~/anaconda3/lib/python3.8/site-packages/pandas/util/_decorators.py in wrapper(*args, **kwargs)
212 else:
213 kwargs[new_arg_name] = new_arg_value
--> 214 return func(*args, **kwargs)
215
216 return cast(F, wrapper)
~/anaconda3/lib/python3.8/site-packages/pandas/core/frame.py in to_stata(self, path, convert_dates, write_index, byteorder, time_stamp, data_label, variable_labels, version, convert_strl)
1967 kwargs["version"] = version
1968
-> 1969 writer = statawriter(
1970 path,
1971 self,
~/anaconda3/lib/python3.8/site-packages/pandas/io/stata.py in __init__(self, fname, data, convert_dates, write_index, byteorder, time_stamp, data_label, variable_labels)
2078 self._own_file = True
2079 # attach nobs, nvars, data, varlist, typlist
-> 2080 self._prepare_pandas(data)
2081
2082 if byteorder is None:
~/anaconda3/lib/python3.8/site-packages/pandas/io/stata.py in _prepare_pandas(self, data)
2307
2308 # Verify object arrays are strings and encode to bytes
-> 2309 self._encode_strings()
2310
2311 self._set_formats_and_types(dtypes)
~/anaconda3/lib/python3.8/site-packages/pandas/io/stata.py in _encode_strings(self)
2337 if not ((inferred_dtype in ("string", "unicode")) or len(column) == 0):
2338 col = column.name
-> 2339 raise ValueError(
2340 f"""\
2341 Column `{col}` cannot be exported.\n\nOnly string-like object arrays
ValueError: Column `a` cannot be exported.
Only string-like object arrays
containing all strings or a mix of strings and None can be exported.
Object arrays containing only null values are prohibited. Other object
types cannot be exported and must first be converted to one of the
supported types.
If you try exporting column b you would similarly get a ValueError as stata
can’t represent lists of numbers.
This is sensible for the domain in which stata operates. For regressions we need
to store variables that contains some data such as int, float, str values
that stata can directly operate on.
Dates¶
If you try passing datetime objects from pandas that includes time zone information you will
get a NotImplementedError as stata.
Generally this type of error indicates that this is not supported.
This could mean that stata might be able to work with time zone data but it hasn’t
been implemented in the pandas code – or the target data type can’t support the
additional information.
In this case you will need to cast the datetime into a simpler datetime object.