16. 自动微分探险#
GPU
本讲座使用了配备 GPU 的机器进行构建——但没有 GPU 也可以运行。
Google Colab 提供了免费的 GPU 访问, 您可以按照以下步骤使用:
点击右上角的”play”图标
选择 Colab
将运行时环境设置为包含 GPU
16.1. 概述#
本讲座以 我们的简要预览 为基础,使用 Google JAX 对自动微分进行更深入的介绍。
自动微分是现代机器学习和人工智能的关键要素之一。
正因如此,它吸引了大量的投资,目前已有几个强大的实现可供使用。
其中最优秀的之一是 JAX 中包含的自动微分例程。
虽然其他软件包也提供此功能,但 JAX 版本特别强大,因为它与 JAX 的其他核心组件(例如 JIT 编译和并行化)集成得非常好。
自动微分不仅可以用于人工智能,还可以用于数学建模中面临的许多问题,例如多维非线性优化和求根问题。
除了 Anaconda 中已有的内容外,本讲座还需要以下库:
!pip install jax
我们需要以下导入:
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
from sympy import symbols
16.2. 什么是自动微分?#
自动微分(Autodiff)是一种在计算机上计算导数的技术。
16.2.1. 自动微分不是有限差分#
\(f(x) = \exp(2x)\) 的导数为
不知道如何求导的计算机可能会用有限差分比率来近似:
其中 \(h\) 是一个小正数。
def f(x):
"Original function."
return np.exp(2 * x)
def f_prime(x):
"True derivative."
return 2 * np.exp(2 * x)
def Df(x, h=0.1):
"Approximate derivative (finite difference)."
return (f(x + h) - f(x))/h
x_grid = np.linspace(-2, 1, 200)
fig, ax = plt.subplots()
ax.plot(x_grid, f_prime(x_grid), label="$f'$")
ax.plot(x_grid, Df(x_grid), label="$Df$")
ax.legend()
plt.show()
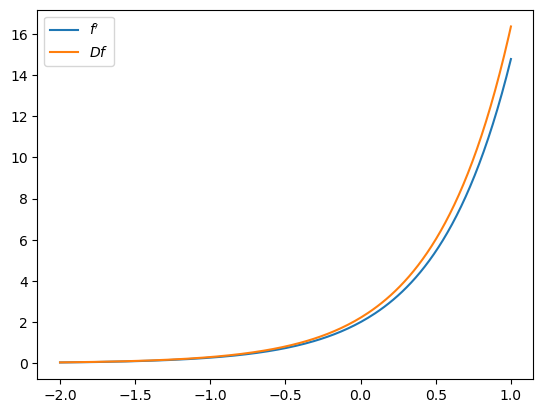
这种数值导数通常不准确且不稳定。
原因之一是:
分子和分母中的小数值会导致舍入误差。
在高维情况下或对高阶导数而言,情况会呈指数级恶化。
16.2.2. 自动微分不是符号微积分#
符号微积分尝试使用微分规则来生成表示导数的单一封闭形式表达式。
m, a, b, x = symbols('m a b x')
f_x = (a*x + b)**m
f_x.diff((x, 6)) # 6-th order derivative
符号微积分不适合高性能计算。
一个缺点是符号微积分无法对控制流进行微分。
此外,使用符号微积分可能涉及冗余计算。
例如,考虑:
如果我们在 \(x\) 处求值,那么 \(f(x)\) 和 \(g(x)\) 各会被计算两次。
另外,计算 \(f'(x)\) 和 \(f(x)\) 可能涉及类似的项(例如,\(f(x) = \exp(2x) \implies f'(x) = 2f(x)\)),但符号代数并不利用这一点。
16.2.3. 自动微分#
自动微分生成的函数在调用代码传入数值时对导数进行求值,而不是生成表示整个导数的单一符号表达式。
导数通过链式法则将计算分解为各个组成部分来构建。
链式法则被反复应用,直到各项化简为程序知道如何精确微分的原始函数(加法、减法、指数、正弦和余弦等)。
16.3. 一些实验#
让我们从 \(\mathbb R\) 上的一些实值函数开始。
16.3.1. 一个可微函数#
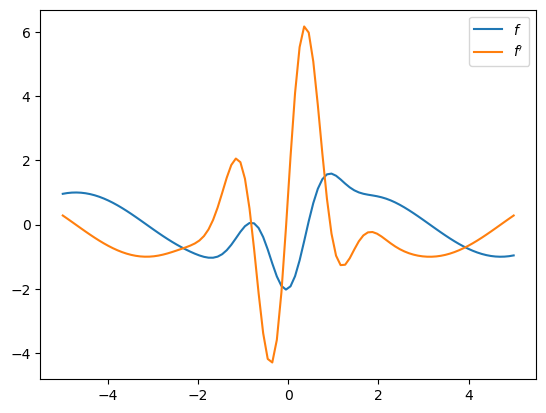
让我们用一个相对简单的函数来测试 JAX 的自动微分。
def f(x):
return jnp.sin(x) - 2 * jnp.cos(3 * x) * jnp.exp(- x**2)
我们使用 grad 来计算实值函数的梯度:
f_prime = jax.grad(f)
让我们绘制结果:
x_grid = jnp.linspace(-5, 5, 100)
fig, ax = plt.subplots()
ax.plot(x_grid, [f(x) for x in x_grid], label="$f$")
ax.plot(x_grid, [f_prime(x) for x in x_grid], label="$f'$")
ax.legend()
plt.show()
16.3.2. 绝对值函数#
如果函数不可微会发生什么?
def f(x):
return jnp.abs(x)
f_prime = jax.grad(f)
fig, ax = plt.subplots()
ax.plot(x_grid, [f(x) for x in x_grid], label="$f$")
ax.plot(x_grid, [f_prime(x) for x in x_grid], label="$f'$")
ax.legend()
plt.show()
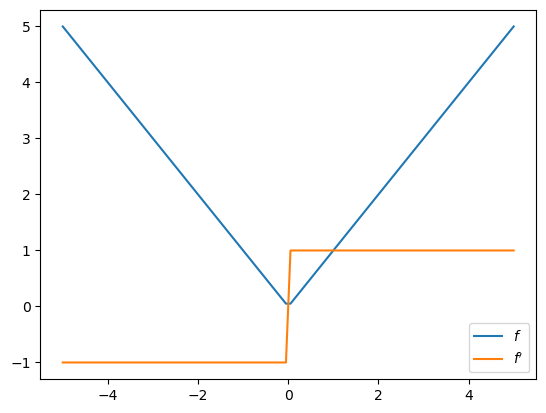
在不可微点 \(0\) 处,jax.grad 返回右导数:
f_prime(0.0)
Array(1., dtype=float32, weak_type=True)
16.3.3. 对控制流进行微分#
让我们尝试对一些循环和条件进行微分。
def f(x):
def f1(x):
for i in range(2):
x *= 0.2 * x
return x
def f2(x):
x = sum((x**i + i) for i in range(3))
return x
y = f1(x) if x < 0 else f2(x)
return y
f_prime = jax.grad(f)
x_grid = jnp.linspace(-5, 5, 100)
fig, ax = plt.subplots()
ax.plot(x_grid, [f(x) for x in x_grid], label="$f$")
ax.plot(x_grid, [f_prime(x) for x in x_grid], label="$f'$")
ax.legend()
plt.show()
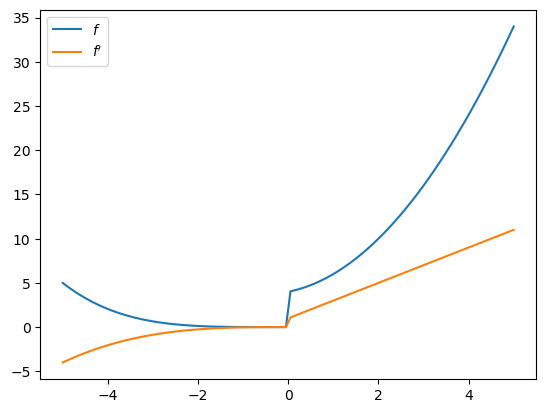
16.3.4. 对线性插值进行微分#
我们可以对线性插值进行微分,即使函数不光滑:
n = 20
xp = jnp.linspace(-5, 5, n)
yp = jnp.cos(2 * xp)
fig, ax = plt.subplots()
ax.plot(x_grid, jnp.interp(x_grid, xp, yp))
plt.show()
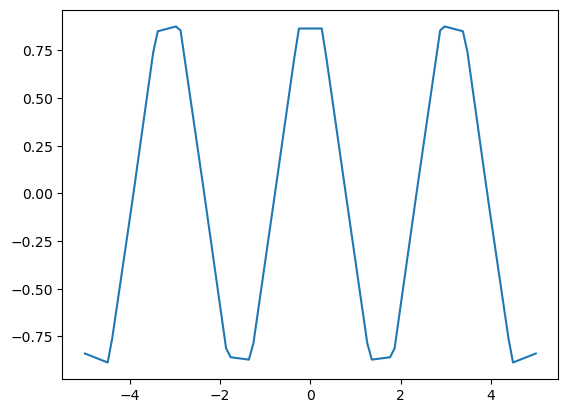
f_prime = jax.grad(jnp.interp)
f_prime_vec = jax.vmap(f_prime, in_axes=(0, None, None))
fig, ax = plt.subplots()
ax.plot(x_grid, f_prime_vec(x_grid, xp, yp))
plt.show()
16.4. 梯度下降#
让我们尝试实现梯度下降。
作为一个简单的应用,我们将使用梯度下降来求解简单线性回归中的普通最小二乘法参数估计值。
16.4.1. 梯度下降函数#
以下是梯度下降的实现。
def grad_descent(f, # Function to be minimized
args, # Extra arguments to the function
x0, # Initial condition
λ=0.1, # Initial learning rate
tol=1e-5,
max_iter=1_000):
"""
Minimize the function f via gradient descent, starting from guess x0.
The learning rate is computed according to the Barzilai-Borwein method.
"""
f_grad = jax.grad(f)
x = jnp.array(x0)
df = f_grad(x, args)
ϵ = tol + 1
i = 0
while ϵ > tol and i < max_iter:
new_x = x - λ * df
new_df = f_grad(new_x, args)
Δx = new_x - x
Δdf = new_df - df
λ = jnp.abs(Δx @ Δdf) / (Δdf @ Δdf)
ϵ = jnp.max(jnp.abs(Δx))
x, df = new_x, new_df
i += 1
return x
16.4.2. 模拟数据#
我们将通过最小化回归问题中的最小二乘和来测试我们的梯度下降函数。
让我们生成一些模拟数据:
n = 100
key = jax.random.key(1234)
x = jax.random.uniform(key, (n,))
α, β, σ = 0.5, 1.0, 0.1 # Set the true intercept and slope.
key, subkey = jax.random.split(key)
ϵ = jax.random.normal(subkey, (n,))
y = α * x + β + σ * ϵ
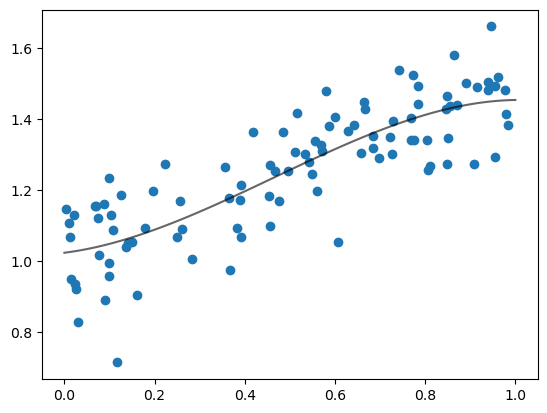
fig, ax = plt.subplots()
ax.scatter(x, y)
plt.show()
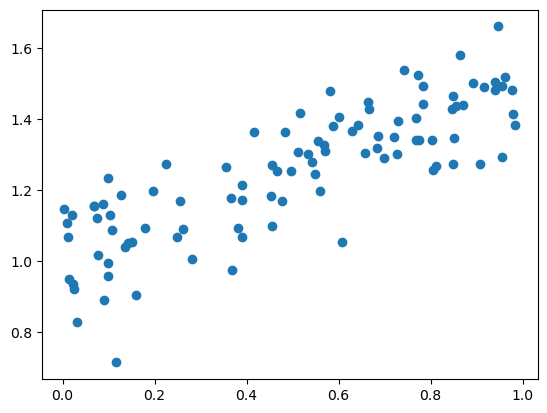
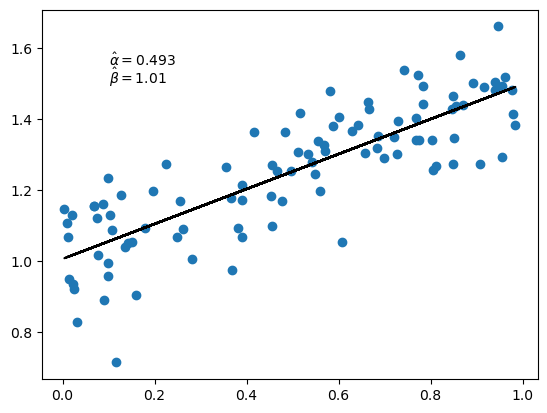
让我们首先使用封闭形式解来计算估计的斜率和截距。
mx = x.mean()
my = y.mean()
α_hat = jnp.sum((x - mx) * (y - my)) / jnp.sum((x - mx)**2)
β_hat = my - α_hat * mx
α_hat, β_hat
(Array(0.49340877, dtype=float32), Array(1.0055456, dtype=float32))
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x, α_hat * x + β_hat, 'k-')
ax.text(0.1, 1.55, rf'$\hat \alpha = {α_hat:.3}$')
ax.text(0.1, 1.50, rf'$\hat \beta = {β_hat:.3}$')
plt.show()
16.4.3. 通过梯度下降最小化平方损失#
让我们看看是否可以用我们的梯度下降函数得到相同的值。
首先我们建立最小二乘损失函数。
@jax.jit
def loss(params, data):
a, b = params
x, y = data
return jnp.sum((y - a * x - b)**2)
现在我们对其进行最小化:
p0 = jnp.zeros(2) # Initial guess for α, β
data = x, y
α_hat, β_hat = grad_descent(loss, data, p0)
让我们绘制结果。
fig, ax = plt.subplots()
x_grid = jnp.linspace(0, 1, 100)
ax.scatter(x, y)
ax.plot(x_grid, α_hat * x_grid + β_hat, 'k-', alpha=0.6)
ax.text(0.1, 1.55, rf'$\hat \alpha = {α_hat:.3}$')
ax.text(0.1, 1.50, rf'$\hat \beta = {β_hat:.3}$')
plt.show()
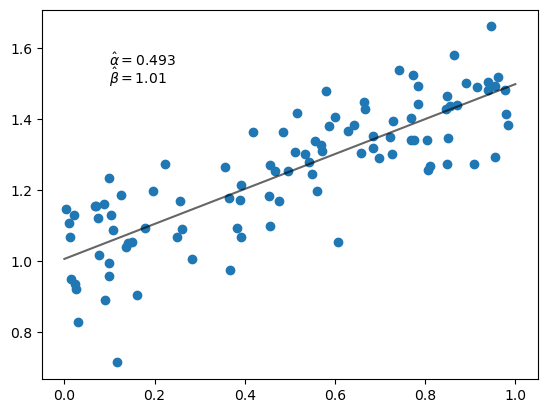
注意,我们得到了与封闭形式解相同的估计值。
16.4.4. 添加二次项#
现在让我们尝试拟合一个二次多项式。
以下是我们新的损失函数。
@jax.jit
def loss(params, data):
a, b, c = params
x, y = data
return jnp.sum((y - a * x**2 - b * x - c)**2)
现在我们在三维空间中进行最小化。
让我们试试看。
p0 = jnp.zeros(3)
α_hat, β_hat, γ_hat = grad_descent(loss, data, p0)
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x_grid, α_hat * x_grid**2 + β_hat * x_grid + γ_hat, 'k-', alpha=0.6)
ax.text(0.1, 1.55, rf'$\hat \alpha = {α_hat:.3}$')
ax.text(0.1, 1.50, rf'$\hat \beta = {β_hat:.3}$')
plt.show()
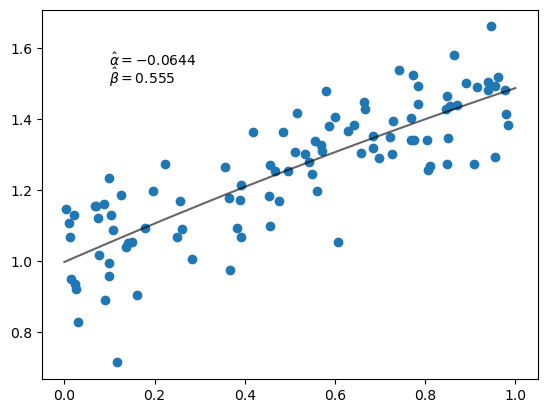
16.5. 练习#
Exercise 16.1
函数 jnp.polyval 用于求多项式的值。
例如,如果 len(p) 为 3,那么 jnp.polyval(p, x) 返回:
使用该函数进行多项式回归。
(经验)损失函数为:
设 \(k=4\),将 params 的初始猜测值设为 jnp.zeros(k)。
使用梯度下降找到使损失函数最小化的数组 params,并绘制结果(参照上面的示例)。
Solution
以下是一种解法。
def loss(params, data):
x, y = data
return jnp.sum((y - jnp.polyval(params, x))**2)
k = 4
p0 = jnp.zeros(k)
p_hat = grad_descent(loss, data, p0)
print('Estimated parameter vector:')
print(p_hat)
print('\n\n')
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x_grid, jnp.polyval(p_hat, x_grid), 'k-', alpha=0.6)
plt.show()
Estimated parameter vector:
[-0.6806411 0.9491472 0.16280958 1.0229238 ]