19. 编写高质量代码#
“任何傻瓜都能写出计算机能理解的代码。优秀的程序员编写人类能理解的代码。” – Martin Fowler
19.1. 概述#
当计算机程序规模较小时,代码写得不好并不会造成太大的损失。
但随着数据量的增加、模型的日益复杂以及计算能力的提升,我们正在应对需要编写更长程序的更具挑战性的问题。
对于此类程序,投资于良好的编码实践将带来丰厚回报。
主要收益在于更高的生产效率和更快的代码执行速度。
在本讲座中,我们将回顾一些良好编码实践的要素。
我们还将涉及科学计算中的现代进展——例如即时编译——以及它们如何影响良好的程序设计。
19.2. 劣质代码示例#
让我们来看一些写得很糟糕的代码。
这段代码的任务是生成并绘制简化索洛模型的时间序列
这里
\(k_t\) 是时间 \(t\) 时的资本,
\(s, \alpha, \delta\) 是参数(储蓄率、生产率参数和折旧率)
对于每组参数化,代码
设置 \(k_0 = 1\)
使用 (19.1) 迭代生成序列 \(k_0, k_1, k_2 \ldots , k_T\)
绘制该序列
图形将被分成三个子图。
在每个子图中,两个参数保持固定,另一个参数变化
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
# 为时间序列分配内存
k = np.empty(50)
fig, axes = plt.subplots(3, 1, figsize=(8, 16))
# 不同 α 下的轨迹
δ = 0.1
s = 0.4
α = (0.25, 0.33, 0.45)
for j in range(3):
k[0] = 1
for t in range(49):
k[t+1] = s * k[t]**α[j] + (1 - δ) * k[t]
axes[0].plot(k, 'o-', label=rf"$\alpha = {α[j]},\; s = {s},\; \delta={δ}$")
axes[0].grid(lw=0.2)
axes[0].set_ylim(0, 18)
axes[0].set_xlabel('时间')
axes[0].set_ylabel('资本')
axes[0].legend(loc='upper left', frameon=True)
# 不同 s 下的轨迹
δ = 0.1
α = 0.33
s = (0.3, 0.4, 0.5)
for j in range(3):
k[0] = 1
for t in range(49):
k[t+1] = s[j] * k[t]**α + (1 - δ) * k[t]
axes[1].plot(k, 'o-', label=rf"$\alpha = {α},\; s = {s[j]},\; \delta={δ}$")
axes[1].grid(lw=0.2)
axes[1].set_xlabel('时间')
axes[1].set_ylabel('资本')
axes[1].set_ylim(0, 18)
axes[1].legend(loc='upper left', frameon=True)
# 不同 δ 下的轨迹
δ = (0.05, 0.1, 0.15)
α = 0.33
s = 0.4
for j in range(3):
k[0] = 1
for t in range(49):
k[t+1] = s * k[t]**α + (1 - δ[j]) * k[t]
axes[2].plot(k, 'o-', label=rf"$\alpha = {α},\; s = {s},\; \delta={δ[j]}$")
axes[2].set_ylim(0, 18)
axes[2].set_xlabel('时间')
axes[2].set_ylabel('资本')
axes[2].grid(lw=0.2)
axes[2].legend(loc='upper left', frameon=True)
plt.show()
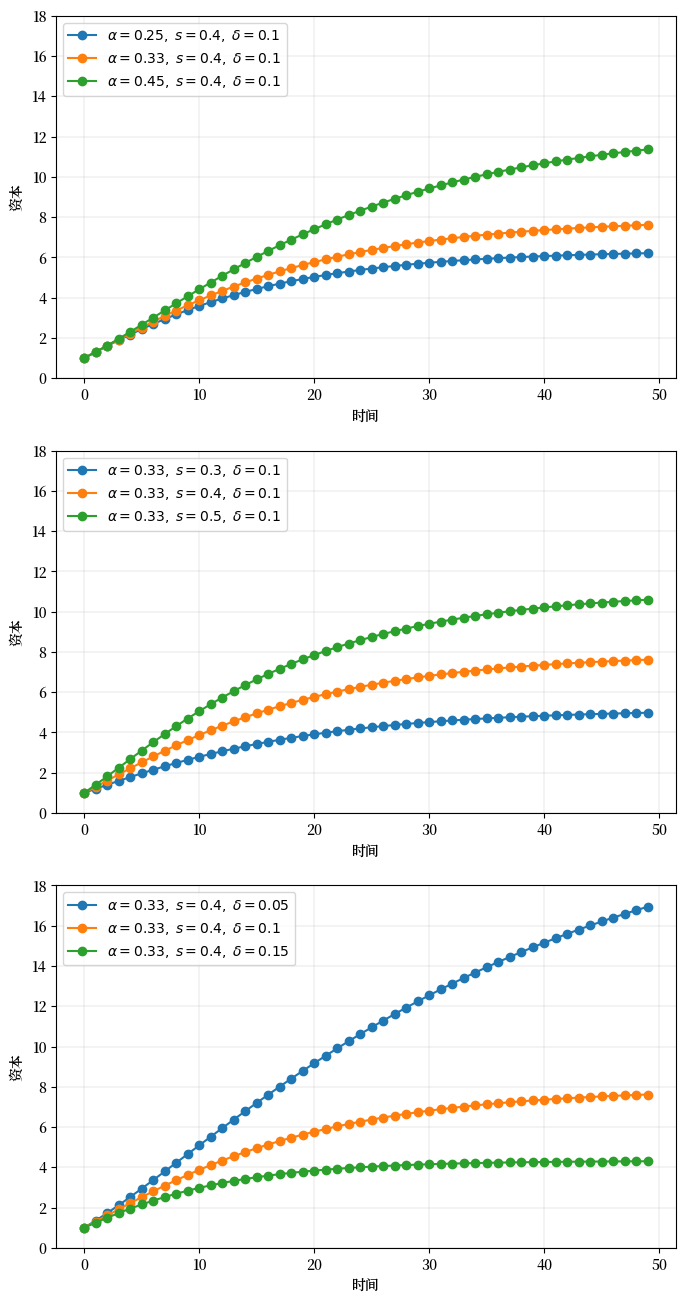
诚然,这段代码或多或少遵循了 PEP8。
但与此同时,它的结构非常糟糕。
让我们来讨论一下原因,以及我们能做些什么。
19.3. 良好的编码实践#
完成给定任务的程序通常有许多不同的写法。
对于上面那样的小程序,代码的编写方式并不太重要。
但如果你志存高远,想要产出有用的东西,你也会编写中型到大型程序。
在那些场景中,编码风格极为重要。
幸运的是,许多聪明人已经思考过编写代码的最佳方式。
以下是一些基本准则。
19.3.1. 不要使用魔法数字#
如果你查看上面的代码,会看到 50、49 和 3 等数字散落在代码中。
代码主体中的这类数字字面量有时被称为”魔法数字”。
这可不是赞美。
虽然数字字面量并非全都是罪恶的,但上述程序中显示的数字肯定应该被命名常量替换。
例如,上面的代码可以声明变量 time_series_length = 50。
然后在循环中,49 应该被替换为 time_series_length - 1。
这样做的优点是:
含义在整个代码中更加清晰
要更改时间序列长度,只需更改一个值
19.3.2. 不要重复自己#
上述代码片段中的另一个致命错误是重复。
逻辑块(例如生成时间序列的循环)以细微变化被一再重复。
这违反了编程的基本原则:不要重复自己(DRY)。
也称为 DIE(重复是邪恶的)。
是的,我们知道你可以直接复制粘贴并更改几个符号。
但作为程序员,你的目标应该是自动化重复,而不是亲自去做。
更重要的是,在不同地方重复相同的逻辑意味着最终其中一处可能会出错。
如果你想了解更多,请阅读此页面上的精彩总结。
我们将在下面讨论如何避免重复。
19.3.3. 最小化全局变量#
当然,全局变量(即在任何函数或类之外赋值给名称的变量)很方便。
新手程序员通常大量使用全局变量——就像我们曾经做的那样。
但全局变量是危险的,尤其是在中型到大型程序中,因为
它们可以影响程序任何部分发生的事情
它们可以被任何函数更改
这使得要确定某段给定代码的某个小部分实际命令了什么变得更加困难。
这里有一个关于该主题的有用讨论。
虽然在小脚本中偶尔使用全局变量没什么大碍,但我们建议你训练自己避免使用它们。
(我们将在下面讨论具体方法)。
19.3.3.1. JIT 编译#
对于科学计算,还有另一个避免全局变量的好理由。
正如我们在以前的讲座中看到的,JIT 编译可以为 Python 等脚本语言生成出色的性能。
但当存在全局变量时,用于 JIT 编译的编译器的任务会变得更加困难。
换句话说,当变量被封装在函数内部时,JIT 编译所需的类型推断更加安全和有效。
19.3.4. 使用函数或类#
幸运的是,我们可以轻松避免全局变量和 WET 代码的弊端。
WET 代表”我们喜欢打字”,是 DRY 的反面。
我们可以通过频繁使用函数或类来做到这一点。
事实上,函数和类正是专门为帮助我们避免重复代码或过度使用全局变量而设计的。
19.3.4.1. 选哪个,函数还是类?#
两者都很有用,事实上它们相互配合得很好。
随着时间的推移,我们将更多地了解这些主题。
(个人偏好也是其中的一部分)
真正重要的是你使用其中一种或两种都用。
19.4. 重新审视示例#
以下代码以更好的编码风格复现了上面的图形。
from itertools import product
def plot_path(ax, αs, s_vals, δs, time_series_length=50):
"""
为所有给定参数向坐标轴 ax 添加时间序列图。
"""
k = np.empty(time_series_length)
for (α, s, δ) in product(αs, s_vals, δs):
k[0] = 1
for t in range(time_series_length-1):
k[t+1] = s * k[t]**α + (1 - δ) * k[t]
ax.plot(k, 'o-', label=rf"$\alpha = {α},\; s = {s},\; \delta = {δ}$")
ax.set_xlabel('时间')
ax.set_ylabel('资本')
ax.set_ylim(0, 18)
ax.legend(loc='upper left', frameon=True)
fig, axes = plt.subplots(3, 1, figsize=(8, 16))
# 参数 (αs, s_vals, δs)
set_one = ([0.25, 0.33, 0.45], [0.4], [0.1])
set_two = ([0.33], [0.3, 0.4, 0.5], [0.1])
set_three = ([0.33], [0.4], [0.05, 0.1, 0.15])
for (ax, params) in zip(axes, (set_one, set_two, set_three)):
αs, s_vals, δs = params
plot_path(ax, αs, s_vals, δs)
plt.show()
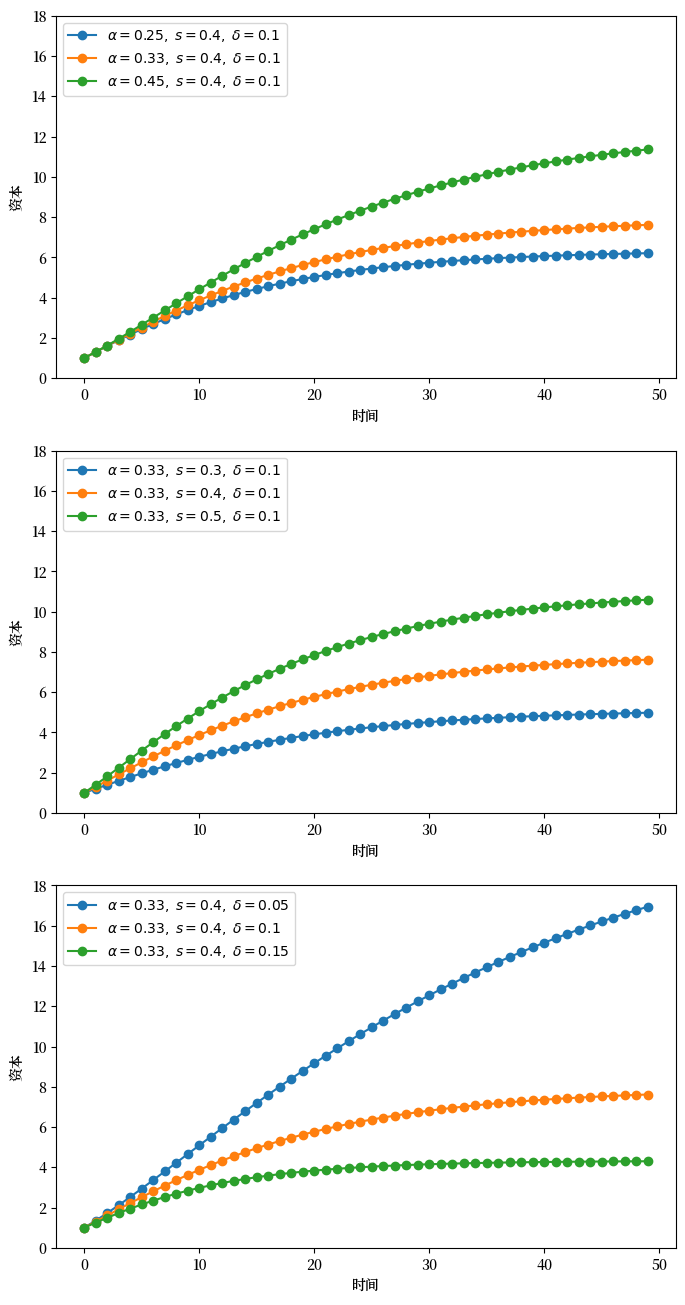
如果你检查这段代码,会发现
它使用函数来避免重复。
全局变量被隔离,集中放在程序末尾而非开头。
避免了魔法数字。
最后执行实际工作的循环简短且相对简单。
19.5. 练习#
Exercise 19.1
以下是一些需要改进的代码。
它涉及一个基本的供求问题。
供给由以下公式给出
需求曲线为
\(\alpha\)、\(\beta\)、\(\gamma\) 和 \(\delta\) 的值是参数
均衡价格 \(p^*\) 是使得 \(q_d(p) = q_s(p)\) 的价格。
我们可以使用求根算法来求解这个均衡。 具体而言,我们将找到使 \(h(p) = 0\) 的 \(p\), 其中
这给出均衡价格 \(p^*\)。由此我们通过 \(q^* = q_s(p^*)\) 得到均衡数量
参数值为
\(\alpha = 0.1\)
\(\beta = 1\)
\(\gamma = 1\)
\(\delta = 1\)
from scipy.optimize import brentq
# 计算均衡
def h(p):
return p**(-1) - (np.exp(0.1 * p) - 1) # 需求 - 供给
p_star = brentq(h, 2, 4)
q_star = np.exp(0.1 * p_star) - 1
print(f'Equilibrium price is {p_star: .2f}')
print(f'Equilibrium quantity is {q_star: .2f}')
Equilibrium price is 2.93
Equilibrium quantity is 0.34
我们也来绘制结果。
# 现在绘图
grid = np.linspace(2, 4, 100)
fig, ax = plt.subplots()
qs = np.exp(0.1 * grid) - 1
qd = grid**(-1)
ax.plot(grid, qd, 'b-', lw=2, label='需求')
ax.plot(grid, qs, 'g-', lw=2, label='供给')
ax.set_xlabel('价格')
ax.set_ylabel('数量')
ax.legend(loc='upper center')
plt.show()
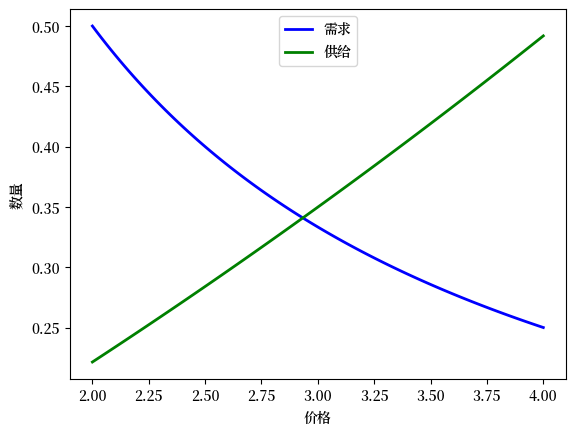
我们还想考虑供给和需求的变动。
例如,让我们看看当需求上移时会发生什么,\(\gamma\) 增加到 \(1.25\):
# 计算均衡
def h(p):
return 1.25 * p**(-1) - (np.exp(0.1 * p) - 1)
p_star = brentq(h, 2, 4)
q_star = np.exp(0.1 * p_star) - 1
print(f'Equilibrium price is {p_star: .2f}')
print(f'Equilibrium quantity is {q_star: .2f}')
Equilibrium price is 3.25
Equilibrium quantity is 0.38
# 现在绘图
p_grid = np.linspace(2, 4, 100)
fig, ax = plt.subplots()
qs = np.exp(0.1 * p_grid) - 1
qd = 1.25 * p_grid**(-1)
ax.plot(grid, qd, 'b-', lw=2, label='需求')
ax.plot(grid, qs, 'g-', lw=2, label='供给')
ax.set_xlabel('价格')
ax.set_ylabel('数量')
ax.legend(loc='upper center')
plt.show()
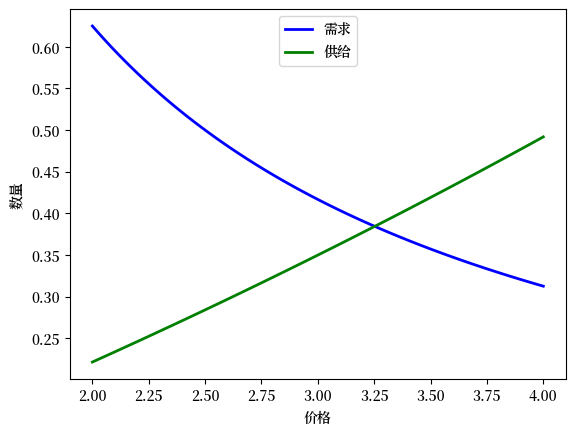
现在我们可以考虑供给的变动,但你已经明白这里有大量重复代码了。
请运用本讲座中讨论的原则,对上述代码进行重构并提升清晰度。
Solution
以下是使用类的一种解决方案:
class Equilibrium:
def __init__(self, α=0.1, β=1, γ=1, δ=1):
self.α, self.β, self.γ, self.δ = α, β, γ, δ
def qs(self, p):
return np.exp(self.α * p) - self.β
def qd(self, p):
return self.γ * p**(-self.δ)
def compute_equilibrium(self):
def h(p):
return self.qd(p) - self.qs(p)
p_star = brentq(h, 2, 4)
q_star = np.exp(self.α * p_star) - self.β
print(f'Equilibrium price is {p_star: .2f}')
print(f'Equilibrium quantity is {q_star: .2f}')
def plot_equilibrium(self):
# 现在绘图
grid = np.linspace(2, 4, 100)
fig, ax = plt.subplots()
ax.plot(grid, self.qd(grid), 'b-', lw=2, label='需求')
ax.plot(grid, self.qs(grid), 'g-', lw=2, label='供给')
ax.set_xlabel('价格')
ax.set_ylabel('数量')
ax.legend(loc='upper center')
plt.show()
让我们用默认参数值创建一个实例。
eq = Equilibrium()
现在我们来计算均衡并绘图。
eq.compute_equilibrium()
Equilibrium price is 2.93
Equilibrium quantity is 0.34
eq.plot_equilibrium()
我们重构后的代码有一个好处是,当我们更改参数时,不需要重复自己:
eq.γ = 1.25
eq.compute_equilibrium()
Equilibrium price is 3.25
Equilibrium quantity is 0.38
eq.plot_equilibrium()