3. 入门示例#
3.1. 概述#
我们现在准备开始学习 Python 语言本身。
在本讲座中,我们将编写并逐步解析小型 Python 程序。
目标是向您介绍基本的 Python 语法和数据结构。
更深层的概念将在后续讲座中介绍。
在开始本讲座之前,您应该已经阅读过关于 Python 入门的讲座。
3.2. 任务:绘制白噪声过程#
假设我们想要模拟并绘制白噪声过程 \(\epsilon_0, \epsilon_1, \ldots, \epsilon_T\),其中每个抽取值 \(\epsilon_t\) 是独立的标准正态分布。
换句话说,我们想要生成如下所示的图形:
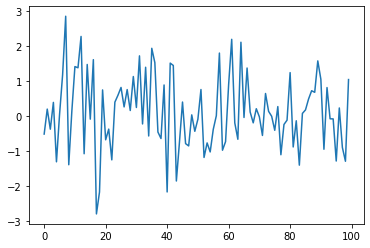
(这里 \(t\) 在横轴上,\(\epsilon_t\) 在纵轴上。)
我们将以几种不同的方式来完成这个任务,每次都会学到更多关于 Python 的知识。
3.3. 版本一#
以下几行代码可以完成我们设定的任务
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
rng = np.random.default_rng()
ϵ_values = rng.standard_normal(100)
plt.plot(ϵ_values)
plt.show()
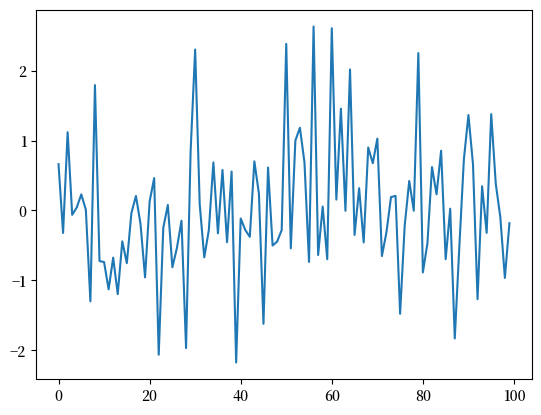
让我们拆解这个程序,看看它是如何工作的。
3.3.1. 导入语句#
程序的前两行从外部代码库中导入功能。
第一行导入 NumPy,这是一个常用的 Python 包,用于以下任务:
处理数组(向量和矩阵)
常用数学函数,如
cos和sqrt生成随机数
线性代数等
在执行 import numpy as np 之后,我们可以通过语法 np.属性名 访问这些属性。
下面是两个更多的示例
np.sqrt(4)
np.float64(2.0)
np.log(4)
np.float64(1.3862943611198906)
3.3.1.1. 为什么需要这么多导入语句?#
Python 程序通常需要多条导入语句。
原因是核心语言被刻意保持精简,以便于学习、维护和改进。
当您想用 Python 做一些有趣的事情时,几乎总是需要导入额外的功能。
3.3.1.2. 包#
如上所述,NumPy 是一个 Python 包。
开发者使用包来组织他们希望共享的代码。
实际上,包就是一个包含以下内容的目录:
包含 Python 代码的文件——在 Python 中称为模块
可能还有一些可被 Python 访问的编译代码(例如,从 C 或 FORTRAN 代码编译的函数)
一个名为
__init__.py的文件,用于指定当我们键入import package_name时将执行的内容
您可以通过运行以下代码来检查 NumPy 的 __init__.py 在 Python 中的位置:
import numpy as np
print(np.__file__)
3.3.1.3. 子包#
考虑这行代码 rng = np.random.default_rng()。
这里 np 指的是 NumPy 包,而 random 是 NumPy 的一个子包。
子包就是另一个包的子目录中的包。
例如,您可以在 NumPy 的目录下找到 random 文件夹。
3.3.2. 直接导入名称#
回顾我们上面看到的这段代码
import numpy as np
np.sqrt(4)
np.float64(2.0)
这是访问 NumPy 平方根函数的另一种方式
from numpy import sqrt
sqrt(4)
np.float64(2.0)
这也是可以的。
如果我们在代码中经常使用 sqrt,其优点是打字更少。
缺点是,在一个较长的程序中,这两行可能被许多其他行分隔开。
这样的话,如果读者想知道 sqrt 来自哪里,就会更难找到。
3.3.3. 随机抽取#
回到我们绘制白噪声的程序,导入语句之后的剩余三行是
ϵ_values = rng.standard_normal(100)
plt.plot(ϵ_values)
plt.show()
第一行生成 100 个(准)独立的标准正态随机数,并将它们存储在 ϵ_values 中。
接下来两行生成图形。
我们可以并且将在下面研究配置和改进这个图形的各种方式。
3.4. 替代实现#
让我们尝试编写第一个程序的一些替代版本,该程序绘制了来自标准正态分布的独立同分布抽取值。
下面的程序比原始版本效率更低,因此有些刻意为之。
但它们确实帮助我们在熟悉的设置中说明一些重要的 Python 语法和语义。
3.4.1. 使用 For 循环的版本#
这是一个说明 for 循环和 Python 列表的版本。
ts_length = 100
ϵ_values = [] # 空列表
for i in range(ts_length):
e = rng.standard_normal()
ϵ_values.append(e)
plt.plot(ϵ_values)
plt.show()
简而言之,
第一行设置时间序列的期望长度。
下一行创建一个名为
ϵ_values的空列表,用于在生成时存储 \(\epsilon_t\) 值。语句
# 空列表是一个注释,被 Python 解释器忽略。接下来的三行是
for循环,它反复抽取一个新的随机数 \(\epsilon_t\) 并将其追加到列表ϵ_values的末尾。最后两行生成图形并将其显示给用户。
让我们更详细地研究这个程序的某些部分。
3.4.2. 列表#
考虑语句 ϵ_values = [],它创建一个空列表。
列表是 Python 的原生数据结构,用于将一组对象组合在一起。
列表中的项目是有序的,列表中允许有重复项。
例如,尝试
x = [10, 'foo', False]
type(x)
list
向列表添加值时,我们可以使用语法 list_name.append(some_value)
x
[10, 'foo', False]
x.append(2.5)
x
[10, 'foo', False, 2.5]
这里 append() 就是所谓的方法,它是”附属于”对象的函数——在本例中是列表 x。
我们将在后面学习所有关于方法的内容,但为了给您一些概念,
另一个有用的列表方法是 pop()
x
[10, 'foo', False, 2.5]
x.pop()
2.5
x
[10, 'foo', False]
Python 中的列表是基于零的(与 C、Java 或 Go 一样),所以第一个元素通过 x[0] 引用
x[0] # x 的第一个元素
10
x[1] # x 的第二个元素
'foo'
3.4.3. For 循环#
现在让我们考虑上面程序中的 for 循环,它是
for i in range(ts_length):
e = rng.standard_normal()
ϵ_values.append(e)
Python 在继续之前会执行这两个缩进行 ts_length 次。
这两行被称为代码块,因为它们构成了我们循环遍历的代码”块”。
与大多数其他语言不同,Python 仅通过缩进来知道代码块的范围。
在我们的程序中,缩进在 ϵ_values.append(e) 行之后减少,告诉 Python 这行标志着代码块的下边界。
关于缩进的更多内容见下文——现在让我们看另一个 for 循环的例子
animals = ['dog', 'cat', 'bird']
for animal in animals:
print("The plural of " + animal + " is " + animal + "s")
The plural of dog is dogs
The plural of cat is cats
The plural of bird is birds
这个例子有助于阐明 for 循环的工作原理:当我们执行以下形式的循环时
for variable_name in sequence:
<code block>
Python 解释器执行以下操作:
对于
sequence的每个元素,它将名称variable_name“绑定”到该元素,然后执行代码块。
3.4.4. 关于缩进的说明#
在讨论 for 循环时,我们解释了被循环的代码块由缩进来分隔。
事实上,在 Python 中,所有代码块(即那些出现在循环、if 子句、函数定义等内部的代码块)都由缩进来分隔。
因此,与大多数其他语言不同,Python 代码中的空白会影响程序的输出。
一旦您习惯了这一点,这是一件好事,因为它:
强制使用整洁、一致的缩进,提高可读性
消除冗余,例如其他语言中使用的括号或结束语句
另一方面,需要一点注意才能做对,所以请记住:
代码块开始之前的行总是以冒号结尾
for i in range(10):if x > y:while x < 100:等等
代码块中的所有行必须具有相同的缩进量。
Python 标准是 4 个空格,这也是您应该使用的。
3.4.5. While 循环#
for 循环是 Python 中最常见的迭代技术。
但为了说明目的,让我们修改上面的程序,改用 while 循环。
ts_length = 100
ϵ_values = []
i = 0
while i < ts_length:
e = rng.standard_normal()
ϵ_values.append(e)
i = i + 1
plt.plot(ϵ_values)
plt.show()
while 循环将持续执行由缩进分隔的代码块,直到条件(i < ts_length)被满足。
在本例中,程序将持续向列表 ϵ_values 添加值,直到 i 等于 ts_length:
i == ts_length # while 循环的终止条件
True
注意:
while循环的代码块同样仅由缩进来分隔。语句
i = i + 1可以替换为i += 1。
3.5. 另一个应用#
在我们转向练习之前,让我们再做一个应用。
在这个应用中,我们随时间绘制银行账户余额。
在整个时间段内没有取款,时间段的最后日期用 \(T\) 表示。
初始余额为 \(b_0\),利率为 \(r\)。
余额从第 \(t\) 期到第 \(t+1\) 期按 \(b_{t+1} = (1 + r) b_t\) 更新。
在下面的代码中,我们生成并绘制序列 \(b_0, b_1, \ldots, b_T\)。
我们将使用 NumPy 数组来存储这个序列,而不是使用 Python 列表。
r = 0.025 # 利率
T = 50 # 终止日期
b = np.empty(T+1) # 一个空的 NumPy 数组,用于存储所有的 b_t
b[0] = 10 # 初始余额
for t in range(T):
b[t+1] = (1 + r) * b[t]
plt.plot(b, label='银行余额')
plt.legend()
plt.show()
语句 b = np.empty(T+1) 在内存中分配存储空间,用于存放 T+1 个(浮点数)数字。
这些数字由 for 循环填入。
在开始时分配内存比使用 Python 列表和 append 更高效,因为后者必须反复向操作系统申请存储空间。
注意我们在图中添加了图例——这是您将被要求在练习中使用的功能。
3.6. 练习#
现在我们转向练习。在继续之前完成这些练习非常重要,因为它们介绍了我们将需要的新概念。
Exercise 3.1
您的第一个任务是模拟并绘制相关时间序列
冲击序列 \(\{\epsilon_t\}\) 假设为独立同分布的标准正态分布。
在您的解答中,将导入语句限制为
import numpy as np
import matplotlib.pyplot as plt
设 \(T=200\) 且 \(\alpha = 0.9\)。
Solution
以下是一种解答。
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
rng = np.random.default_rng()
for t in range(T):
x[t+1] = α * x[t] + rng.standard_normal()
plt.plot(x)
plt.show()
Exercise 3.2
从练习一的解答出发,绘制三条模拟时间序列,分别对应 \(\alpha=0\)、\(\alpha=0.8\) 和 \(\alpha=0.98\) 三种情况。
使用 for 循环来遍历 \(\alpha\) 的值。
如果可以的话,添加图例以帮助区分三条时间序列。
Hint
如果在调用
show()之前多次调用plot()函数,您生成的所有线条都会出现在同一张图上。对于图例,注意假设
var = 42,表达式f'foo{var}'的求值结果为'foo42'。
Solution
α_values = [0.0, 0.8, 0.98]
T = 200
x = np.empty(T+1)
rng = np.random.default_rng()
for α in α_values:
x[0] = 0
for t in range(T):
x[t+1] = α * x[t] + rng.standard_normal()
plt.plot(x, label=f'$\\alpha = {α}$')
plt.legend()
plt.show()
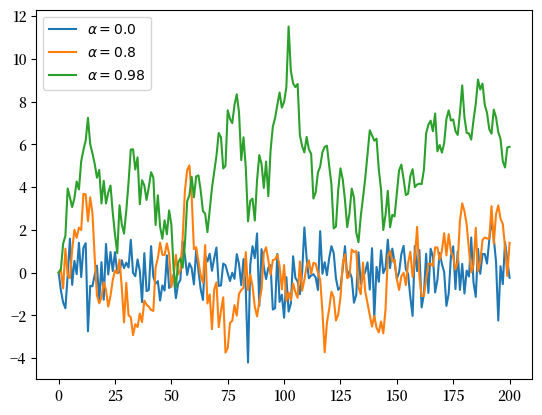
Exercise 3.3
与前面的练习类似,绘制时间序列
使用 \(T=200\)、\(\alpha = 0.9\) 以及和之前一样的 \(\{\epsilon_t\}\)。
在网上搜索一个可用于计算绝对值 \(|x_t|\) 的函数。
Solution
以下是一种解答:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
rng = np.random.default_rng()
for t in range(T):
x[t+1] = α * np.abs(x[t]) + rng.standard_normal()
plt.plot(x)
plt.show()
Exercise 3.4
几乎所有编程语言的一个重要方面是分支和条件判断。
在 Python 中,条件通常使用 if–else 语法实现。
下面是一个示例,对数组中的每个负数打印 -1,对每个非负数打印 1
numbers = [-9, 2.3, -11, 0]
for x in numbers:
if x < 0:
print(-1)
else:
print(1)
-1
1
-1
1
现在,编写练习三的新解答,不使用现有函数来计算绝对值。
用 if–else 条件替换这个现有函数。
Solution
以下是一种方式:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
rng = np.random.default_rng()
for t in range(T):
if x[t] < 0:
abs_x = - x[t]
else:
abs_x = x[t]
x[t+1] = α * abs_x + rng.standard_normal()
plt.plot(x)
plt.show()
以下是写同样内容的更简短方式:
α = 0.9
T = 200
x = np.empty(T+1)
x[0] = 0
rng = np.random.default_rng()
for t in range(T):
abs_x = - x[t] if x[t] < 0 else x[t]
x[t+1] = α * abs_x + rng.standard_normal()
plt.plot(x)
plt.show()
Exercise 3.5
这是一个需要一些思考和规划的较难练习。
任务是使用 蒙特卡洛 方法计算 \(\pi\) 的近似值。
除以下内容外不使用其他导入语句
import numpy as np
Hint
您的提示如下:
如果 \(U\) 是单位正方形 \((0, 1)^2\) 上的二元均匀随机变量,那么 \(U\) 落在 \((0,1)^2\) 的子集 \(B\) 中的概率等于 \(B\) 的面积。
如果 \(U_1,\ldots,U_n\) 是 \(U\) 的独立同分布副本,那么随着 \(n\) 变大,落在 \(B\) 中的比例收敛到落在 \(B\) 中的概率。
对于圆,\(面积 = \pi \times 半径^2\)。
Solution
考虑嵌入单位正方形中的直径为 1 的圆。
设 \(A\) 为其面积,\(r=1/2\) 为其半径。
如果我们知道 \(\pi\),则可以通过 \(A = \pi r^2\) 计算 \(A\)。
但这里的重点是计算 \(\pi\),我们可以通过 \(\pi = A / r^2\) 来做到这一点。
总结:如果我们能估计直径为 1 的圆的面积,那么除以 \(r^2 = (1/2)^2 = 1/4\) 就得到 \(\pi\) 的估计值。
我们通过抽取二元均匀随机数并观察落入圆中的比例来估计面积。
n = 1000000 # 蒙特卡洛模拟的样本量
rng = np.random.default_rng()
count = 0
for i in range(n):
# 在正方形上随机抽取位置
u, v = rng.uniform(), rng.uniform()
# 检查该点是否落在以 (0.5,0.5) 为圆心的
# 单位圆的边界内
d = np.sqrt((u - 0.5)**2 + (v - 0.5)**2)
# 如果落在内切圆内,
# 将其加入计数
if d < 0.5:
count += 1
area_estimate = count / n
print(area_estimate * 4) # 除以半径的平方
3.141568