14. JAX#
本讲座简要介绍 Google JAX。
GPU
本讲座使用了配备 GPU 的机器进行构建——但没有 GPU 也可以运行。
Google Colab 提供了免费的 GPU 访问, 您可以按照以下步骤使用:
点击右上角的”play”图标
选择 Colab
将运行时环境设置为包含 GPU
JAX 是一个高性能科学计算库,提供以下功能:
JAX 也在日益维护和提供 更多专业化的科学计算例程,例如那些最初在 SciPy 中找到的例程。
除了 Anaconda 中已有的内容外,本讲座还需要以下库:
!pip install jax quantecon
我们将使用以下导入:
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import quantecon as qe
注意我们导入了 jax.numpy as jnp,它提供了类似 NumPy 的接口。
14.1. JAX 作为 NumPy 的替代品#
JAX 的一个吸引人之处在于,它的数组处理操作在尽可能的情况下遵循 NumPy API。
这意味着在许多情况下,我们可以将 JAX 作为 NumPy 的直接替代品使用。
让我们来看看 JAX 和 NumPy 之间的异同。
14.1.1. 相似之处#
以下是使用 jnp 进行的一些标准数组操作:
a = jnp.asarray((1.0, 3.2, -1.5))
print(a)
[ 1. 3.2 -1.5]
print(jnp.sum(a))
2.6999998
print(jnp.dot(a, a))
13.490001
然而,数组对象 a 并不是 NumPy 数组:
a
Array([ 1. , 3.2, -1.5], dtype=float32)
type(a)
jaxlib._jax.ArrayImpl
即使是数组上的标量值映射也会返回 JAX 数组,而不是标量!
jnp.sum(a)
Array(2.6999998, dtype=float32)
14.1.2. 差异#
现在让我们来看看 JAX 和 NumPy 数组操作之间的一些差异。
14.1.2.1. 速度!#
假设我们想在许多点上计算余弦函数。
n = 50_000_000
x = np.linspace(0, 10, n)
14.1.2.1.1. 使用 NumPy#
让我们先用 NumPy 试试:
with qe.Timer():
# First NumPy timing
y = np.cos(x)
0.6332 seconds elapsed
再来一次。
with qe.Timer():
# Second NumPy timing
y = np.cos(x)
0.6343 seconds elapsed
这里
NumPy 使用预编译的二进制文件对浮点数数组应用余弦函数
该二进制文件在本地机器的 CPU 上运行
14.1.2.1.2. 使用 JAX#
现在让我们用 JAX 试试。
x = jnp.linspace(0, 10, n)
让我们对相同的过程计时。
with qe.Timer():
# First run
y = jnp.cos(x)
# Hold the interpreter until the array operation finishes
jax.block_until_ready(y);
0.1233 seconds elapsed
Note
这里,为了测量实际速度,我们使用 block_until_ready 方法来阻塞解释器,直到计算结果返回。
这是必要的,因为 JAX 使用异步调度,允许 Python 解释器在数值计算之前运行。
对于非计时代码,可以删除包含 block_until_ready 的那一行。
再来计时一次。
with qe.Timer():
# Second run
y = jnp.cos(x)
# Hold interpreter
jax.block_until_ready(y);
0.0957 seconds elapsed
在 GPU 上,此代码的运行速度远快于其 NumPy 等效代码。
此外,通常第二次运行比第一次更快,这是由于 JIT 编译的缘故。
这是因为即使是像 jnp.cos 这样的内置函数也是经过 JIT 编译的——第一次运行包含了编译时间。
为什么 JAX 要对像 jnp.cos 这样的内置函数进行 JIT 编译,而不是像 NumPy 那样直接提供预编译版本?
原因是 JIT 编译器希望针对所使用数组的大小(以及数据类型)进行专门优化。
大小对于生成优化代码很重要,因为高效的并行化需要将任务大小与可用硬件相匹配。
14.1.2.2. 大小实验#
我们可以通过更改输入大小并观察运行时间来验证 JAX 针对数组大小进行专门化的说法。
x = jnp.linspace(0, 10, n + 1)
with qe.Timer():
# First run
y = jnp.cos(x)
# Hold interpreter
jax.block_until_ready(y);
0.1357 seconds elapsed
with qe.Timer():
# Second run
y = jnp.cos(x)
# Hold interpreter
jax.block_until_ready(y);
0.0869 seconds elapsed
运行时间先增加后减少(这在 GPU 上会更明显)。
这与上面的讨论一致——更改数组大小后的第一次运行显示了编译开销。
关于 JIT 编译的进一步讨论见下文。
14.1.2.3. 精度#
NumPy 和 JAX 之间的另一个差异是 JAX 默认使用 32 位浮点数。
这是因为 JAX 经常用于 GPU 计算,而大多数 GPU 计算使用 32 位浮点数。
使用 32 位浮点数可以在精度损失很小的情况下带来显著的速度提升。
然而,对于某些计算,精度至关重要。
在这些情况下,可以通过以下命令强制使用 64 位浮点数:
jax.config.update("jax_enable_x64", True)
让我们验证这是否有效:
jnp.ones(3)
Array([1., 1., 1.], dtype=float64)
14.1.2.4. 不可变性#
作为 NumPy 的替代品,一个更显著的差异是数组被视为不可变的。
例如,在 NumPy 中我们可以这样写:
a = np.linspace(0, 1, 3)
a
array([0. , 0.5, 1. ])
然后在内存中修改数据:
a[0] = 1
a
array([1. , 0.5, 1. ])
在 JAX 中,这会失败!
a = jnp.linspace(0, 1, 3)
a
Array([0. , 0.5, 1. ], dtype=float64)
try:
a[0] = 1
except Exception as e:
print(e)
JAX arrays are immutable and do not support in-place item assignment. Instead of x[idx] = y, use x = x.at[idx].set(y) or another .at[] method: https://docs.jax.dev/en/latest/_autosummary/jax.numpy.ndarray.at.html
JAX 的设计者选择将数组设为不可变的,因为 JAX 使用函数式编程风格,我们将在下面讨论这一点。
14.1.2.5. 变通方法#
我们注意到 JAX 确实提供了一种替代原地数组修改的方式,使用 at 方法。
a = jnp.linspace(0, 1, 3)
应用 at[0].set(1) 会返回一个新的 a 的副本,其中第一个元素被设置为 1:
a = a.at[0].set(1)
a
Array([1. , 0.5, 1. ], dtype=float64)
显然,使用 at 有一些缺点:
语法繁琐,且
每次更改单个值时,我们都希望避免在内存中创建新数组!
因此,在大多数情况下,我们尽量避免使用这种语法。
(尽管它在 JIT 编译的函数中实际上可以很高效——但现在先把这个放在一边。)
14.2. 函数式编程#
来自 JAX 的文档:
当在意大利乡间漫步时,当地人会毫不犹豫地告诉你 JAX 有”una anima di pura programmazione funzionale”(纯函数式编程的灵魂)。
换句话说,JAX 假设采用 函数式编程 风格。
14.2.1. 纯函数#
最主要的含义是 JAX 函数应该是纯函数。
纯函数具有以下特征:
确定性
无副作用
确定性意味着:
相同输入 \(\implies\) 相同输出
输出不依赖于全局状态
特别地,纯函数在使用相同输入调用时将始终返回相同的结果。
无副作用意味着函数:
不会改变全局状态
不会修改传递给函数的数据(不可变数据)
14.2.2. 示例——纯函数与非纯函数#
以下是一个非纯函数的示例:
tax_rate = 0.1
def add_tax(prices):
for i, price in enumerate(prices):
prices[i] = price * (1 + tax_rate)
prices = [10.0, 20.0]
add_tax(prices)
prices
[11.0, 22.0]
这个函数不是纯函数,因为:
副作用——它修改了全局变量
prices非确定性——对全局变量
tax_rate的更改会修改函数输出,即使使用相同的输入数组prices。
以下是一个纯版本:
def add_tax_pure(prices, tax_rate):
new_prices = [price * (1 + tax_rate) for price in prices]
return new_prices
tax_rate = 0.1
prices = (10.0, 20.0)
after_tax_prices = add_tax_pure(prices, tax_rate)
after_tax_prices
[11.0, 22.0]
这是纯函数,因为:
所有依赖关系通过函数参数显式传递
并且不修改任何外部状态
14.2.3. 为什么要函数式编程?#
在 QuantEcon,我们热爱纯函数,因为它们:
有助于测试:每个函数可以独立运行
促进确定性行为,从而提高可重复性
防止由于修改共享状态而产生的错误
JAX 编译器热爱纯函数和函数式编程,因为:
数据依赖关系是显式的,有助于优化复杂计算
纯函数更易于微分(自动微分)
纯函数更易于并行化和优化(不依赖于共享的可变状态)
另一种理解方式如下:
JAX 将函数表示为计算图,然后对其进行编译或变换(例如,微分)。
这些计算图描述了给定的一组输入如何被转换为输出。
JAX 的计算图在构造上是纯粹的。
JAX 使用函数式编程风格,以便用户构建的函数能够直接映射到 JAX 所支持的图论表示中。
14.3. 随机数#
JAX 中的随机数生成与 NumPy 或 MATLAB 中的模式有很大不同。
14.3.1. NumPy / MATLAB 方法#
在 NumPy / MATLAB 中,生成通过维护隐藏的全局状态来工作。
np.random.seed(42)
print(np.random.randn(2))
[ 0.49671415 -0.1382643 ]
每次我们调用随机函数时,隐藏状态都会被更新:
print(np.random.randn(2))
[0.64768854 1.52302986]
这个函数不是纯函数,因为:
它是非确定性的:相同的输入,不同的输出
它有副作用:它修改了全局随机数生成器状态
在并行化下很危险——必须仔细控制每个线程中发生的事情。
14.3.2. JAX#
在 JAX 中,随机数生成器的状态被显式控制。
首先我们生成一个密钥,它为随机数生成器提供种子。
seed = 1234
key = jax.random.key(seed)
现在我们可以使用密钥生成一些随机数:
x = jax.random.normal(key, (3, 3))
x
Array([[-0.54019824, 0.43957585, -0.01978102],
[ 0.90665474, -0.90831359, 1.32846635],
[ 0.20408174, 0.93096529, 3.30373914]], dtype=float64)
如果我们再次使用相同的密钥,我们会以相同的种子初始化,因此随机数是相同的:
jax.random.normal(key, (3, 3))
Array([[-0.54019824, 0.43957585, -0.01978102],
[ 0.90665474, -0.90831359, 1.32846635],
[ 0.20408174, 0.93096529, 3.30373914]], dtype=float64)
要生成(准)独立的抽取,一种选择是”分裂”现有密钥:
key, subkey = jax.random.split(key)
jax.random.normal(key, (3, 3))
Array([[ 1.24104247, 0.12018902, -2.23990047],
[ 0.70507261, -0.85702845, -1.24582014],
[ 0.38454486, 1.32117717, 0.56866901]], dtype=float64)
jax.random.normal(subkey, (3, 3))
Array([[ 0.07627173, -1.30349831, 0.86524323],
[-0.75550773, 0.63958052, 0.47052126],
[-1.72866044, -1.14696564, -1.23328892]], dtype=float64)
下图说明了 split 如何从单个根密钥生成密钥树,每个密钥生成独立的随机抽取。
/tmp/ipykernel_2894/3497588807.py:64: UserWarning: Glyph 23494 (\N{CJK UNIFIED IDEOGRAPH-5BC6}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_2894/3497588807.py:64: UserWarning: Glyph 38053 (\N{CJK UNIFIED IDEOGRAPH-94A5}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_2894/3497588807.py:64: UserWarning: Glyph 25286 (\N{CJK UNIFIED IDEOGRAPH-62C6}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_2894/3497588807.py:64: UserWarning: Glyph 20998 (\N{CJK UNIFIED IDEOGRAPH-5206}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/tmp/ipykernel_2894/3497588807.py:64: UserWarning: Glyph 26641 (\N{CJK UNIFIED IDEOGRAPH-6811}) missing from font(s) DejaVu Sans.
plt.tight_layout()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 23494 (\N{CJK UNIFIED IDEOGRAPH-5BC6}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 38053 (\N{CJK UNIFIED IDEOGRAPH-94A5}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 25286 (\N{CJK UNIFIED IDEOGRAPH-62C6}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 20998 (\N{CJK UNIFIED IDEOGRAPH-5206}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 26641 (\N{CJK UNIFIED IDEOGRAPH-6811}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
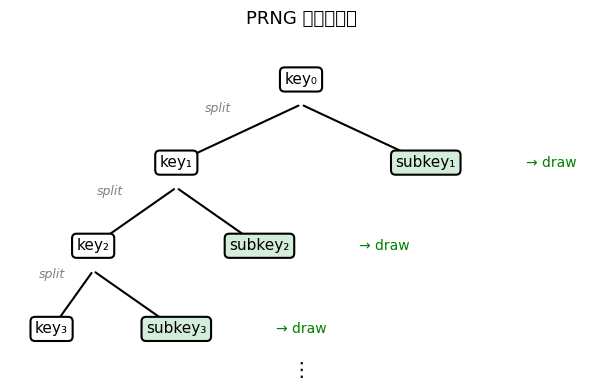
对于 NumPy 或 Matlab 用户来说,这种语法看起来很不寻常——但当我们进入并行编程时,就会很有意义。
下面的函数使用 split 生成 k 个(准)独立的随机 n x n 矩阵。
def gen_random_matrices(
key, # JAX key for random numbers
n=2, # Matrices will be n x n
k=3 # Number of matrices to generate
):
matrices = []
for _ in range(k):
key, subkey = jax.random.split(key)
A = jax.random.uniform(subkey, (n, n))
matrices.append(A)
return matrices
seed = 42
key = jax.random.key(seed)
gen_random_matrices(key)
[Array([[0.74211901, 0.54715578],
[0.05988742, 0.32206803]], dtype=float64),
Array([[0.65877976, 0.57087415],
[0.97301903, 0.10138266]], dtype=float64),
Array([[0.68745522, 0.25974132],
[0.06595873, 0.83589118]], dtype=float64)]
这个函数是纯函数:
确定性的:相同的输入,相同的输出
无副作用:没有隐藏状态被修改
14.3.3. 好处#
如上所述,这种显式性是很有价值的:
可复现性:通过重用密钥轻松重现结果
并行化:控制各个线程上发生的事情
调试:没有隐藏状态使代码更容易测试
JIT 兼容性:编译器可以更积极地优化纯函数
14.4. JIT 编译#
JAX 的即时(JIT)编译器通过生成随任务大小和硬件变化的高效机器码来加速执行。
我们在 上文 中已经看到了 JAX 的 JIT 编译器结合并行硬件的强大之处,当时我们对一个大数组应用了 cos 函数。
这里我们研究更复杂函数的 JIT 编译。
14.4.1. 使用 NumPy#
我们先用 NumPy 试试,使用:
def f(x):
y = np.cos(2 * x**2) + np.sqrt(np.abs(x)) + 2 * np.sin(x**4) - x**2
return y
用较大的 x 运行:
n = 50_000_000
x = np.linspace(0, 10, n)
with qe.Timer():
# Time NumPy code
y = f(x)
2.2643 seconds elapsed
急切(Eager)执行模型
每个操作在遇到时立即执行,在下一个操作开始之前将其结果实体化。
缺点
并行化程度最低
较大的内存占用——产生许多中间数组
大量内存读写
14.4.2. 使用 JAX#
作为第一步,我们将整个代码中的 np 替换为 jnp:
def f(x):
y = jnp.cos(2 * x**2) + jnp.sqrt(jnp.abs(x)) + 2 * jnp.sin(x**4) - x**2
return y
x = jnp.linspace(0, 10, n)
现在让我们计时。
with qe.Timer():
# First call
y = f(x)
# Hold interpreter
jax.block_until_ready(y);
1.1309 seconds elapsed
with qe.Timer():
# Second call
y = f(x)
# Hold interpreter
jax.block_until_ready(y);
0.9483 seconds elapsed
结果与 cos 示例类似——JAX 更快,尤其是在 JIT 编译后的第二次运行中。
这是因为单个数组操作在 GPU 上并行化了。
但我们仍在使用即时执行:
由于中间数组导致大量内存占用
大量内存读写
此外,GPU 上还会启动许多独立的内核。
14.4.3. 编译整个函数#
幸运的是,使用 JAX,我们还有另一个技巧——我们可以对整个函数进行 JIT 编译,而不仅仅是单个操作。
编译器将所有数组运算融合到单个优化内核中。
让我们用函数 f 来试试这个:
f_jax = jax.jit(f)
with qe.Timer():
# First run
y = f_jax(x)
# Hold interpreter
jax.block_until_ready(y);
0.6365 seconds elapsed
with qe.Timer():
# Second run
y = f_jax(x)
# Hold interpreter
jax.block_until_ready(y);
0.6003 seconds elapsed
运行时间再次改善——现在是因为我们融合了所有操作:
基于整个计算序列的积极优化
消除对硬件加速器的多次调用
内存占用也大大降低——不再创建中间数组。
顺便提一下,当针对 JIT 编译器的函数时,更常见的语法是:
@jax.jit
def f(x):
pass # put function body here
14.4.4. JIT 编译的工作原理#
当我们对一个函数应用 jax.jit 时,JAX 会对其进行追踪:它不会立即执行操作,而是将操作序列记录为计算图,并将该图交给 XLA 编译器。
XLA 随后将这些操作融合并优化为针对可用硬件(CPU、GPU 或 TPU)定制的单个编译内核。
对 JIT 编译函数的第一次调用会产生编译开销,但对于具有相同输入形状和类型的后续调用,将重用缓存的编译代码并以全速运行。
14.4.5. 编译非纯函数#
虽然 JAX 在编译非纯函数时通常不会抛出错误,但执行会变得不可预测!
以下是一个例子:
a = 1 # global
@jax.jit
def f(x):
return a + x
x = jnp.ones(2)
f(x)
Array([2., 2.], dtype=float64)
在上面的代码中,全局值 a=1 被融入了 JIT 编译的函数中。
即使我们更改 a,只要调用的是相同的编译版本,f 的输出也不会受到影响。
a = 42
f(x)
Array([2., 2.], dtype=float64)
更改输入的维度会触发函数的重新编译,此时 a 值的变化才会生效:
x = jnp.ones(3)
f(x)
Array([43., 43., 43.], dtype=float64)
这个故事的寓意:使用 JAX 时请编写纯函数!
14.5. 使用 vmap 进行向量化#
JAX 的另一个强大变换是 jax.vmap,它能够自动将针对单个输入编写的函数向量化,使其可以对批量数据进行操作。
这样就无需手动编写向量化代码或使用显式循环。
14.5.1. 一个简单的示例#
假设我们有一个函数,用于计算一组数字的均值与中位数之差。
def mm_diff(x):
return jnp.mean(x) - jnp.median(x)
我们可以将其应用于单个向量:
x = jnp.array([1.0, 2.0, 5.0])
mm_diff(x)
Array(0.66666667, dtype=float64)
现在假设我们有一个矩阵,希望对每一行计算这些统计量。
不使用 vmap 时,我们需要显式循环:
X = jnp.array([[1.0, 2.0, 5.0],
[4.0, 5.0, 6.0],
[1.0, 8.0, 9.0]])
for row in X:
print(mm_diff(row))
0.6666666666666665
0.0
-2.0
然而,Python 循环速度较慢,无法被 JAX 高效编译或并行化。
使用 vmap,我们可以避免循环,并将计算保留在加速器上:
batch_mm_diff = jax.vmap(mm_diff) # Create a new "vectorized" version
batch_mm_diff(X) # Apply to each row of X
Array([ 0.66666667, 0. , -2. ], dtype=float64)
14.5.2. 组合变换#
JAX 的优势之一在于各种变换可以自然地组合使用。
例如,我们可以对向量化函数进行 JIT 编译:
fast_batch_mm_diff = jax.jit(jax.vmap(mm_diff))
fast_batch_mm_diff(X)
Array([ 6.66666667e-01, -2.77555756e-16, -2.00000000e+00], dtype=float64)
jit、vmap 以及(我们接下来将看到的)grad 的这种组合是 JAX 设计的核心,使其在科学计算和机器学习领域尤为强大。
14.6. 练习#
Exercise 14.1
在关于 Numba 的讲座的练习部分,我们使用蒙特卡洛方法为欧式看涨期权定价。
该代码通过基于 Numba 的多线程进行了加速。
尝试使用所有相同的参数为 JAX 编写此操作的版本。
Solution
以下是一种解法:
M = 10_000_000
n, β, K = 20, 0.99, 100
μ, ρ, ν, S0, h0 = 0.0001, 0.1, 0.001, 10, 0
@jax.jit
def compute_call_price_jax(β=β,
μ=μ,
S0=S0,
h0=h0,
K=K,
n=n,
ρ=ρ,
ν=ν,
M=M,
key=jax.random.key(1)):
s = jnp.full(M, np.log(S0))
h = jnp.full(M, h0)
def update(i, loop_state):
s, h, key = loop_state
key, subkey = jax.random.split(key)
Z = jax.random.normal(subkey, (2, M))
s = s + μ + jnp.exp(h) * Z[0, :]
h = ρ * h + ν * Z[1, :]
new_loop_state = s, h, key
return new_loop_state
initial_loop_state = s, h, key
final_loop_state = jax.lax.fori_loop(0, n, update, initial_loop_state)
s, h, key = final_loop_state
expectation = jnp.mean(jnp.maximum(jnp.exp(s) - K, 0))
return β**n * expectation
Note
我们使用 jax.lax.fori_loop 代替 Python 的 for 循环。
这允许 JAX 在不展开循环的情况下高效地编译循环,
从而显著减少大数组的编译时间。
让我们运行一次以编译它:
with qe.Timer():
compute_call_price_jax().block_until_ready()
5.7661 seconds elapsed
现在让我们计时:
with qe.Timer():
compute_call_price_jax().block_until_ready()
5.3184 seconds elapsed