15. NumPy vs Numba vs JAX#
在前面的讲座中,我们讨论了三个用于科学和数值计算的核心库:
在任何给定情况下,我们应该使用哪一个?
本讲座通过讨论一些使用场景,至少部分地回答了这个问题。
在开始之前,我们注意到前两者是一对天然的组合:NumPy 和 Numba 配合良好。
而 JAX 则独立存在。
在考虑每种方法时,我们不仅会考虑效率和内存占用,还会考虑代码的清晰度和易用性。
除了 Anaconda 中已有的内容,本讲座还需要以下库:
!pip install quantecon jax
GPU
本讲座使用了配备 GPU 的机器进行构建——但没有 GPU 也可以运行。
Google Colab 提供了免费的 GPU 访问, 您可以按照以下步骤使用:
点击右上角的”play”图标
选择 Colab
将运行时环境设置为包含 GPU
我们将使用以下导入。
import random
from functools import partial
import numpy as np
import numba
import quantecon as qe
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
from mpl_toolkits.mplot3d.axes3d import Axes3D
from matplotlib import cm
import jax
import jax.numpy as jnp
from jax import lax
15.1. 向量化运算#
某些运算可以被完美地向量化——所有循环都可以轻松消除,数值运算被简化为对数组的计算。
在这种情况下,哪种方法最好?
15.1.1. 问题陈述#
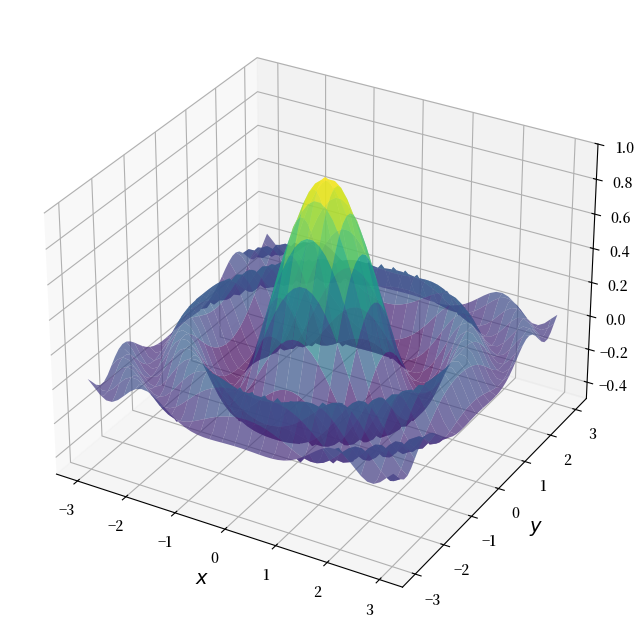
考虑在正方形 \([-a, a] \times [-a, a]\) 上最大化两个变量 \((x,y)\) 的函数 \(f\) 的问题。
对于 \(f\) 和 \(a\),我们选择
以下是 \(f\) 的图像
def f(x, y):
return np.cos(x**2 + y**2) / (1 + x**2 + y**2)
xgrid = np.linspace(-3, 3, 50)
ygrid = xgrid
x, y = np.meshgrid(xgrid, ygrid)
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(x,
y,
f(x, y),
rstride=2, cstride=2,
cmap=cm.viridis,
alpha=0.7,
linewidth=0.25)
ax.set_zlim(-0.5, 1.0)
ax.set_xlabel('$x$', fontsize=14)
ax.set_ylabel('$y$', fontsize=14)
plt.show()
为了本练习的目的,我们将使用暴力搜索来求最大值。
在正方形上的网格中计算所有 \((x,y)\) 处的 \(f\) 值。
返回观测值中的最大值。
为了说明这个思路,这里有一个使用 Python 循环的非向量化版本。
grid = np.linspace(-3, 3, 50)
m = -np.inf
for x in grid:
for y in grid:
z = f(x, y)
m = max(m, z)
15.1.2. NumPy 向量化#
让我们切换到 NumPy 并使用更大的网格。
grid = np.linspace(-3, 3, 3_000) # Large grid
作为向量化的第一步,我们可能会尝试这样的方式
# Large grid
z = np.max(f(grid, grid)) # This is wrong!
这里的问题是 f(grid, grid) 并不遵循嵌套循环。
从上图来看,它只计算了对角线上的 f 值。
要让 NumPy 在每个 x,y 对上计算 f(x,y),我们需要使用 np.meshgrid。
这里我们使用 np.meshgrid 来创建二维输入网格 x 和 y,使得 f(x, y) 能生成乘积网格上的所有计算结果。
# Large grid
grid = np.linspace(-3, 3, 3_000)
x_mesh, y_mesh = np.meshgrid(grid, grid) # MATLAB style meshgrid
with qe.Timer():
z_max_numpy = np.max(f(x_mesh, y_mesh)) # This works
0.1541 seconds elapsed
在向量化版本中,所有循环都在编译后的代码中执行。
使用 meshgrid 可以复现嵌套的 for 循环。
输出结果应接近于 1:
print(f"NumPy result: {z_max_numpy:.6f}")
NumPy result: 0.999998
15.1.3. 内存问题#
我们在合理的时间内得到了正确的解——但内存使用量非常大。
虽然扁平数组占用内存较少
grid.nbytes
24000
但网格矩阵是二维的,因此内存占用非常大
x_mesh.nbytes + y_mesh.nbytes
144000000
此外,NumPy 的即时执行会创建许多相同大小的中间数组!
在实际研究计算中,这种内存使用可能是一个大问题。
15.1.4. 与 Numba 的比较#
让我们看看能否使用简单循环的 Numba 获得更好的性能。
@numba.jit
def compute_max_numba(grid):
m = -np.inf
for x in grid:
for y in grid:
z = np.cos(x**2 + y**2) / (1 + x**2 + y**2)
m = max(m, z)
return m
让我们测试一下:
grid = np.linspace(-3, 3, 3_000)
with qe.Timer():
# First run
z_max_numba = compute_max_numba(grid)
0.2272 seconds elapsed
让我们再次运行以消除编译时间。
with qe.Timer():
# Second run
compute_max_numba(grid)
0.1073 seconds elapsed
注意我们几乎不使用任何内存——我们只需要一维的 grid。
此外,执行速度也很好。
在大多数机器上,Numba 版本会比 NumPy 稍快一些。
原因是高效的机器码加上更少的内存读写。
15.1.5. 并行化的 Numba#
现在让我们使用 prange 尝试 Numba 的并行化:
@numba.jit(parallel=True)
def compute_max_numba_parallel(grid):
n = len(grid)
m = -np.inf
for i in numba.prange(n):
for j in range(n):
x = grid[i]
y = grid[j]
z = np.cos(x**2 + y**2) / (1 + x**2 + y**2)
m = max(m, z)
return m
以下是预热运行和测试。
with qe.Timer():
# First run
z_max_parallel = compute_max_numba_parallel(grid)
0.4573 seconds elapsed
以下是预编译版本的计时结果。
with qe.Timer():
# Second run
compute_max_numba_parallel(grid)
0.0459 seconds elapsed
如果您有多个核心,您应该能在此处看到并行化带来的收益。
让我们确认结果仍然正确(接近于 1):
print(f"Numba result: {z_max_parallel:.6f}")
Numba result: 0.999998
对于强大的机器和更大的网格尺寸,即使在 CPU 上,并行化也能带来有用的速度提升。
15.1.6. 使用 JAX 的向量化代码#
让我们尝试用 JAX 复现 NumPy 的向量化方法。
让我们从函数开始,将 np 替换为 jnp 并添加 jax.jit
@jax.jit
def f(x, y):
return jnp.cos(x**2 + y**2) / (1 + x**2 + y**2)
我们使用 NumPy 风格的 meshgrid 方法:
grid = jnp.linspace(-3, 3, 3_000)
x_mesh, y_mesh = jnp.meshgrid(grid, grid)
现在让我们运行并计时
with qe.Timer():
# First run
z_max = jnp.max(f(x_mesh, y_mesh))
# Hold interpreter
z_max.block_until_ready()
print(f"Plain vanilla JAX result: {z_max:.6f}")
0.0621 seconds elapsed
Plain vanilla JAX result: 0.999998
让我们再次运行以消除编译时间。
with qe.Timer():
# Second run
z_max = jnp.max(f(x_mesh, y_mesh))
# Hold interpreter
z_max.block_until_ready()
0.0189 seconds elapsed
编译完成后,JAX 明显快于 NumPy,在 GPU 上尤为如此。
编译开销是一次性成本,当函数被反复调用时,这种开销是值得的。
15.1.7. JAX 加 vmap#
由于我们在上面使用了 jax.jit,我们避免了创建许多中间数组。
但我们仍然创建了大数组 z_max、x_mesh 和 y_mesh。
幸运的是,我们可以通过使用 jax.vmap 来避免这一问题。
以下是我们将其应用于当前问题的方式。
@jax.jit
def compute_max_vmap(grid):
# 构建一个对给定 y,在所有 x 上取最大值的函数
compute_column_max = lambda y: jnp.max(f(grid, y))
# 向量化该函数,以便我们可以同时对所有 y 调用
vectorized_compute_column_max = jax.vmap(compute_column_max)
# 在每一行处计算列最大值
column_maxes = vectorized_compute_column_max(grid)
# 计算列最大值的最大值并返回
return jnp.max(column_maxes)
注意我们从不创建
二维网格
x_mesh二维网格
y_mesh或二维数组
f(x,y)
与 Numba 类似,我们只使用扁平数组 grid。
并且由于所有内容都在单个 @jax.jit 下,编译器可以将所有操作融合为一个优化的内核。
让我们试试。
with qe.Timer():
# First run
z_max = compute_max_vmap(grid)
# Hold interpreter
z_max.block_until_ready()
print(f"JAX vmap result: {z_max:.6f}")
0.0762 seconds elapsed
JAX vmap result: 0.999998
让我们再次运行以消除编译时间:
with qe.Timer():
# Second run
z_max = compute_max_vmap(grid)
# Hold interpreter
z_max.block_until_ready()
0.0192 seconds elapsed
15.1.8. 总结#
在我们看来,JAX 是向量化运算的赢家。
它在速度(通过 JIT 编译和并行化)和内存效率(通过 vmap)两方面都优于 NumPy。
在 GPU 上运行时,它也优于 Numba。
Note
Numba 可以通过 numba.cuda 支持 GPU 编程,但这样我们需要手动进行并行化。对于经济学、计量经济学和金融学中遇到的大多数情况,将高效并行化的工作交给 JAX 编译器,远比尝试手工编写这些例程要好得多。
15.2. 顺序运算#
某些运算本质上是顺序的——因此难以或不可能向量化。
在这种情况下,NumPy 是一个较差的选择,我们只剩下 Numba 或 JAX 可以选择。
为了比较这两种选择,我们将重新回顾在 Numba 讲座 中看到的迭代二次映射问题。
15.2.1. Numba 版本#
以下是 Numba 版本。
@numba.jit
def qm(x0, n, α=4.0):
x = np.empty(n+1)
x[0] = x0
for t in range(n):
x[t+1] = α * x[t] * (1 - x[t])
return x
让我们生成一个长度为 10,000,000 的时间序列并计时:
n = 10_000_000
with qe.Timer():
# First run
x = qm(0.1, n)
0.0969 seconds elapsed
让我们再次运行以消除编译时间:
with qe.Timer():
# Second run
x = qm(0.1, n)
0.0242 seconds elapsed
Numba 非常高效地处理了这个顺序运算。
15.2.2. JAX 版本#
我们不能直接用 jax.jit 替换 numba.jit,因为 JAX 数组是不可变的。
但我们仍然可以实现这一运算。
15.2.2.1. 第一种尝试#
以下是使用 at[t].set 语法的变通方案,我们在 JAX 讲座中讨论过。
我们将应用 lax.fori_loop,这是一种可以被 XLA 编译的 for 循环版本。
cpu = jax.devices("cpu")[0]
# Pin the input to the CPU, which keeps the whole computation there
x0_cpu = jax.device_put(0.1, cpu)
@partial(jax.jit, static_argnames=("n",))
def qm_jax_fori(x0, n, α=4.0):
x = jnp.empty(n + 1).at[0].set(x0)
def update(t, x):
return x.at[t + 1].set(α * x[t] * (1 - x[t]))
x = lax.fori_loop(0, n, update, x)
return x
我们将
n设为静态,因为它影响数组大小,JAX 希望在编译代码中针对其值进行特化处理。我们通过
jax.device_put将输入固定到 CPU(从而使整个计算保持在 CPU 上),因为这种顺序工作负载由许多小型运算组成,几乎没有机会利用 GPU 并行性。
重要提示:虽然 at[t].set 看起来在每一步都创建了一个新数组,但在 JIT 编译的函数内部,编译器会检测到旧数组不再需要,并就地执行更新!
让我们使用相同的参数计时:
with qe.Timer():
# First run
x_jax = qm_jax_fori(x0_cpu, n)
# Hold interpreter
x_jax.block_until_ready()
0.0985 seconds elapsed
让我们再次运行以消除编译开销:
with qe.Timer():
# Second run
x_jax = qm_jax_fori(x0_cpu, n)
# Hold interpreter
x_jax.block_until_ready()
0.0515 seconds elapsed
JAX 对于这种顺序运算也相当高效!
15.2.2.2. 第二种尝试#
还有另一种使用 lax.scan 实现该循环的方式。
这种替代方案可以说更符合 JAX 的函数式风格——尽管语法难以记忆。
@partial(jax.jit, static_argnames=("n",))
def qm_jax_scan(x0, n, α=4.0):
def update(x, t):
x_new = α * x * (1 - x)
return x_new, x_new
_, x = lax.scan(update, x0, jnp.arange(n))
return jnp.concatenate([jnp.array([x0]), x])
这段代码不易阅读,但本质上,lax.scan 反复调用 update 并将返回值 x_new 累积到一个数组中。
让我们使用相同的参数计时:
with qe.Timer():
# First run
x_jax = qm_jax_scan(x0_cpu, n)
# Hold interpreter
x_jax.block_until_ready()
0.1041 seconds elapsed
让我们再次运行以消除编译开销:
with qe.Timer():
# Second run
x_jax = qm_jax_scan(x0_cpu, n)
# Hold interpreter
x_jax.block_until_ready()
0.0546 seconds elapsed
令人惊讶的是,JAX 在编译后也能提供出色的性能。
15.2.3. 总结#
虽然 Numba 和 JAX 在顺序运算中都能提供出色的性能,但在代码可读性和易用性方面存在差异。
Numba 版本简单直观,易于阅读:我们只需分配一个数组,然后使用标准 Python 循环逐元素填充它。
这正是大多数程序员思考该算法的方式。
另一方面,JAX 版本需要使用 lax.fori_loop 或 lax.scan,这两者都不如标准 Python 循环直观。
虽然 JAX 的 at[t].set 语法确实允许逐元素更新,但整体代码仍然比 Numba 等价版本更难阅读。
15.3. 总体建议#
让我们退一步,总结一下各方的权衡取舍。
对于向量化操作,JAX 是最强的选择。
得益于 JIT 编译和在 CPU 与 GPU 上的高效并行化,它在速度上与 NumPy 持平或超越 NumPy。
vmap 变换降低了内存使用量,并且通常比传统的基于网格的向量化产生更清晰的代码。
此外,JAX 函数支持自动微分,我们将在 自动微分探险 中进一步探讨。
对于顺序操作,Numba 具有更简洁的语法。
代码自然且可读——只需一个带有装饰器的 Python 循环——性能也非常出色。
JAX 可以通过 lax.fori_loop 或 lax.scan 处理顺序问题,但语法不够直观。
另一方面,JAX 版本支持自动微分。
例如,当我们希望计算轨迹对模型参数的敏感性时,这可能会很有用。