13. Numba#
除了 Anaconda 中已有的库之外,本讲座还需要以下库:
!pip install quantecon
请同时确保您安装了最新版本的 Anaconda,因为旧版本是常见错误来源。
让我们从一些导入开始:
import numpy as np
import quantecon as qe
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
13.1. 概述#
在 之前的讲座 中,我们学习了向量化,这是一种通过将数组处理操作批量发送到高效底层代码来提高执行速度的方法。
然而,正如 之前所讨论的,传统的向量化方案有以下弱点:
对于复合数组操作,内存消耗极大
对于某些算法,向量化无效甚至不可能实现
绕过这些问题的一种方法是使用 Numba,这是一个面向 Python 的即时(JIT)编译器。
Numba 在运行时将函数编译为本地机器码指令。
编译成功后,其性能可与编译后的 C 或 Fortran 媲美。
此外,Numba 还可以完成有用的技巧,例如 多线程。
本讲座将介绍核心思路。
Note
一些读者可能对 Numba 与 Julia 之间的关系感到好奇,Julia 包含其自己的 JIT 编译器。虽然这两种编译器在许多方面相似,但 Numba 的目标更为有限,仅尝试编译 Python 语言的一个小子集。虽然这听起来像是一个缺陷,但也是一种优势:Numba 更具限制性的特性使其易于使用,并且非常擅长其所做的事情。
13.2. 编译函数#
13.2.1. 示例#
让我们考虑一个难以向量化的问题(即难以交给数组处理操作来完成)。
该问题涉及通过二次映射生成轨迹
在下文中,我们设 \(\alpha = 4\)。
13.2.1.1. 基础版本#
以下是从 \(x_0 = 0.1\) 出发的典型轨迹图,横轴为 \(t\)
def qm(x0, n, α=4.0):
x = np.empty(n+1)
x[0] = x0
for t in range(n):
x[t+1] = α * x[t] * (1 - x[t])
return x
x = qm(0.1, 250)
fig, ax = plt.subplots()
ax.plot(x, 'b-', lw=2, alpha=0.8)
ax.set_xlabel('$t$', fontsize=12)
ax.set_ylabel('$x_{t}$', fontsize = 12)
plt.show()
让我们看看在较大的 \(n\) 下运行需要多长时间
n = 10_000_000
with qe.Timer() as timer1:
# Time Python base version
x = qm(0.1, n)
3.7173 seconds elapsed
13.2.1.2. 通过 Numba 加速#
要使用 Numba 加速函数 qm,我们首先导入 jit 函数
from numba import jit
现在我们将其应用于 qm,生成一个新函数:
qm_numba = jit(qm)
函数 qm_numba 是 qm 的一个版本,它被”定向”用于 JIT 编译。
我们稍后将解释这意味着什么。
让我们对这个新版本计时:
with qe.Timer() as timer2:
# Time jitted version
x = qm_numba(0.1, n)
0.1510 seconds elapsed
这已经是非常大的速度提升。
事实上,下一次及之后的每次运行都会更快,因为函数已经被编译并保存在内存中:
with qe.Timer() as timer3:
# Second run
x = qm_numba(0.1, n)
0.0257 seconds elapsed
以下是速度提升
timer1.elapsed / timer3.elapsed
144.80889400750456
对我们原始代码进行少量修改便获得了巨大的提升。
让我们讨论一下这是如何工作的。
13.2.2. 工作原理与适用时机#
Numba 尝试使用 LLVM Project 提供的基础设施生成快速机器码。
它通过动态推断类型信息来实现这一点。
(有关类型的讨论,请参阅我们 之前关于科学计算的讲座。)
基本思路如下:
Python 非常灵活,因此我们可以用多种类型调用函数 qm。
例如,
x0可以是 NumPy 数组或列表,n可以是整数或浮点数,等等。
这使得提前(即在运行时之前)生成高效机器码非常困难。
然而,当我们实际调用函数时,例如运行
qm(0.5, 10),x0、α和n的类型就被确定了。此外,一旦输入类型已知,
qm中其他变量的类型可以被推断出来。因此,Numba 和其他 JIT 编译器的策略是等到函数被调用时,然后再进行编译。
这被称为”即时”编译。
注意,如果你先调用 qm_numba(0.5, 10),然后再调用 qm_numba(0.9, 20),编译只在第一次调用时发生。
这是因为编译后的代码会被缓存并按需重用。
这就是为什么在上面的代码中,qm_numba 的第二次运行更快。
备注
在实践中,我们通常使用装饰器语法,而不是编写 qm_numba = jit(qm),在函数定义前加上 @jit。这等价于在定义之后添加 qm = jit(qm)。
13.3. 注意事项#
Numba 相对容易使用,但并非总是无缝衔接的。
让我们来回顾一些用户常遇到的问题。
13.3.1. 类型推断#
成功的类型推断是 JIT 编译的关键。
在理想情况下,Numba 可以推断出所有必要的类型信息。
当 Numba 无法 推断所有类型信息时,它将抛出错误。
例如,在以下情况中,Numba 在编译 iterate 时无法确定函数 g 的类型:
@jit
def iterate(f, x0, n):
x = x0
for t in range(n):
x = f(x)
return x
# 未经 jit 编译
def g(x):
return np.cos(x) - 2 * np.sin(x)
# 这段代码会抛出错误
try:
iterate(g, 0.5, 100)
except Exception as e:
print(e)
Failed in nopython mode pipeline (step: nopython frontend)
non-precise type pyobject
During: typing of argument at /tmp/ipykernel_3057/4185348615.py (1)
File "../../../../../../tmp/ipykernel_3057/4185348615.py", line 1:
<source missing, REPL/exec in use?>
During: Pass nopython_type_inference
This error may have been caused by the following argument(s):
- argument 0: Cannot determine Numba type of <class 'function'>
我们可以通过编译 g 来轻松修复这个错误。
@jit
def g(x):
return np.cos(x) - 2 * np.sin(x)
iterate(g, 0.5, 100)
2.223875299559663
在其他情况下,例如当我们想使用来自外部库(如 SciPy)的函数时,可能没有简单的解决方法。
13.3.2. 全局变量#
使用 Numba 时另一个需要注意的问题是全局变量的处理。
例如,考虑以下代码:
a = 1
@jit
def add_a(x):
return a + x
print(add_a(10))
11
a = 2
print(add_a(10))
11
注意,更改全局变量对函数返回的值没有任何影响 😱。
当 Numba 为函数编译机器码时,它将全局变量视为常量以确保类型稳定性。
为了避免这种情况,请将值作为函数参数传递,而不是依赖全局变量。
13.4. Numba 中的多线程循环#
除了 JIT 编译之外,Numba 还为 CPU 和 GPU 上的并行计算提供支持。
Numba 中 CPU 并行化的关键工具是 prange 函数,它告诉 Numba 在可用的 CPU 核心上并行执行循环迭代。
为了说明,让我们首先看一个简单的单线程(即非并行化)代码片段。
该代码通过以下规则模拟家庭财富 \(w_t\) 的更新
其中
\(R\) 是资产的总回报率
\(s\) 是家庭的储蓄率,以及
\(y\) 是劳动收入。
我们将 \(R\) 和 \(y\) 均建模为来自对数正态分布的独立抽样。
以下是代码:
@jit
def update(w, r=0.1, s=0.3, v1=0.1, v2=1.0):
" Updates household wealth. "
# Draw shocks
R = np.exp(v1 * np.random.randn()) * (1 + r)
y = np.exp(v2 * np.random.randn())
# Update wealth
w = R * s * w + y
return w
让我们看看在此规则下财富如何演变。
fig, ax = plt.subplots()
T = 100
w = np.empty(T)
w[0] = 5
for t in range(T-1):
w[t+1] = update(w[t])
ax.plot(w)
ax.set_xlabel('$t$', fontsize=12)
ax.set_ylabel('$w_{t}$', fontsize=12)
plt.show()
现在,假设我们有一个庞大的家庭群体,并且想知道中位财富将是多少。
这个问题很难用纸笔求解,因此我们将使用模拟:
向前模拟大量家庭
计算中位财富
以下是代码:
@jit
def compute_long_run_median(w0=1, T=1000, num_reps=50_000):
obs = np.empty(num_reps)
# For each household
for i in range(num_reps):
# Set the initial condition and run forward in time
w = w0
for t in range(T):
w = update(w)
# Record the final value
obs[i] = w
# Take the median of all final values
return np.median(obs)
让我们看看运行速度:
with qe.Timer():
# Warm up
compute_long_run_median()
5.4550 seconds elapsed
with qe.Timer():
# Second run
compute_long_run_median()
4.5685 seconds elapsed
为了加速这个过程,我们将通过多线程对其进行并行化。
为此,我们添加 parallel=True 标志并将 range 更改为 prange:
from numba import prange
@jit(parallel=True)
def compute_long_run_median_parallel(
w0=1, T=1000, num_reps=50_000
):
obs = np.empty(num_reps)
for i in prange(num_reps): # Parallelize over households
w = w0
for t in range(T):
w = update(w)
obs[i] = w
return np.median(obs)
让我们看看计时结果:
with qe.Timer():
# Warm up
compute_long_run_median_parallel()
1.4313 seconds elapsed
with qe.Timer():
# Second run
compute_long_run_median_parallel()
0.9568 seconds elapsed
速度提升非常显著。
注意,我们是跨家庭进行并行化,而非跨时间——单个家庭跨时期的更新本质上是顺序的。
关于基于 GPU 的并行化,请参阅我们关于 JAX 的讲座。
13.5. 练习#
Exercise 13.1
之前 我们考虑了如何用蒙特卡洛方法近似 \(\pi\)。
在这里使用相同的思路,但使用 Numba 使代码高效。
当样本量较大时,比较有无 Numba 的速度。
Solution
以下是一种解法:
@jit
def calculate_pi(n=1_000_000):
count = 0
for i in range(n):
u, v = np.random.uniform(0, 1), np.random.uniform(0, 1)
d = np.sqrt((u - 0.5)**2 + (v - 0.5)**2)
if d < 0.5:
count += 1
area_estimate = count / n
return area_estimate * 4 # 除以半径的平方
现在让我们看看运行速度:
with qe.Timer():
calculate_pi()
0.1524 seconds elapsed
with qe.Timer():
calculate_pi()
0.0250 seconds elapsed
如果我们通过删除 @jit 来关闭 JIT 编译,代码在我们的机器上大约需要慢 150 倍。
因此,通过添加四个字符,我们获得了 2 个数量级的速度提升。
Exercise 13.2
在 Python 定量经济学入门 讲座系列中,您可以学习到关于有限状态马尔可夫链的所有知识。
现在,让我们专注于模拟一个非常简单的此类链的示例。
假设一种资产的回报波动率可以处于两种状态之一——高或低。
跨状态的转移概率如下所示
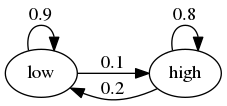
例如,设周期长度为一天,假设当前状态为高。
从图中我们可以看出,明天的状态将是:
以 0.8 的概率为高
以 0.2 的概率为低
您的任务是根据此规则模拟每日波动率状态序列。
将序列长度设为 n = 1_000_000,并从高状态开始。
实现一个纯 Python 版本和一个 Numba 版本,并比较速度。
为了测试您的代码,评估链停留在低状态的时间比例。
如果您的代码正确,该比例应约为 2/3。
Hint
将低状态表示为 0,高状态表示为 1。
如果您想在 NumPy 数组中存储整数,然后应用 JIT 编译,请使用
x = np.empty(n, dtype=np.int64)。
Solution
我们设
0 表示”低”
1 表示”高”
p, q = 0.1, 0.2 # 分别为离开低状态和高状态的概率
以下是函数的纯 Python 版本
def compute_series(n):
x = np.empty(n, dtype=np.int64)
x[0] = 1 # 从状态 1 开始
U = np.random.uniform(0, 1, size=n)
for t in range(1, n):
current_x = x[t-1]
if current_x == 0:
x[t] = U[t] < p
else:
x[t] = U[t] > q
return x
让我们运行这段代码,并检查处于低状态的时间比例约为 0.666
n = 1_000_000
x = compute_series(n)
print(np.mean(x == 0)) # x 处于状态 0 的时间比例
0.667343
这是(近似)正确的输出。
现在让我们计时:
with qe.Timer():
compute_series(n)
0.4380 seconds elapsed
接下来,让我们实现一个 Numba 版本,这很容易
compute_series_numba = jit(compute_series)
让我们检查是否仍然得到正确的数字
x = compute_series_numba(n)
print(np.mean(x == 0))
0.665851
让我们看看时间
with qe.Timer():
compute_series_numba(n)
0.0140 seconds elapsed
对于一行代码来说,这是一个不错的速度提升!
Exercise 13.3
在 之前的练习 中,我们使用 Numba 加速了通过蒙特卡洛方法计算常数 \(\pi\) 的工作。
现在尝试添加并行化,看看是否能获得进一步的速度提升。
这里您不应该期望获得巨大的提升,因为虽然有许多独立的任务(抽取点并测试是否在圆内),但每个任务的执行时间都很短。
一般来说,当要并行化的各个任务相对于总执行时间非常小时,并行化效果较差。
这是由于将所有这些小任务分散到多个 CPU 上所带来的开销。
尽管如此,使用合适的硬件,在本练习中仍然可以获得不可忽视的速度提升。
对于蒙特卡洛模拟的规模,请使用一个较大的值,例如 n = 100_000_000。
Solution
以下是一种解法:
@jit(parallel=True)
def calculate_pi(n=1_000_000):
count = 0
for i in prange(n):
u, v = np.random.uniform(0, 1), np.random.uniform(0, 1)
d = np.sqrt((u - 0.5)**2 + (v - 0.5)**2)
if d < 0.5:
count += 1
area_estimate = count / n
return area_estimate * 4 # 除以半径的平方
现在让我们看看运行速度:
with qe.Timer():
calculate_pi()
0.4277 seconds elapsed
with qe.Timer():
calculate_pi()
0.0057 seconds elapsed
通过打开和关闭并行化(在 @jit 注解中选择 True 或 False),我们可以测试多线程在 JIT 编译之上提供的速度增益。
在我们的工作站上,我们发现并行化将执行速度提高了 2 到 3 倍。
(如果您在本地执行,您将得到不同的数字,主要取决于您机器上的 CPU 数量。)
Exercise 13.4
在 我们关于 SciPy 的讲座 中,我们讨论了在标的股票价格具有简单且众所周知的分布的情况下,如何为看涨期权定价。
这里我们讨论一个更现实的情境。
我们回顾一下,期权的价格满足
其中
\(\beta\) 是贴现因子,
\(n\) 是到期日,
\(K\) 是行权价,以及
\(\{S_t\}\) 是标的资产在每个时刻 \(t\) 的价格。
假设 n, β, K = 20, 0.99, 100。
假设股票价格满足
其中
这里 \(\{\xi_t\}\) 和 \(\{\eta_t\}\) 是独立同分布的标准正态随机变量。
(这是一个随机波动率模型,其中波动率 \(\sigma_t\) 随时间变化。)
使用默认值 μ, ρ, ν, S0, h0 = 0.0001, 0.1, 0.001, 10, 0。
(这里 S0 是 \(S_0\),h0 是 \(h_0\)。)
通过生成 \(M\) 条路径 \(s_0, \ldots, s_n\),计算蒙特卡洛估计值
即价格,应用 Numba 和并行化。
Solution
令 \(s_t := \ln S_t\),价格动态变为
利用这一事实,解可以写成如下形式。
M = 10_000_000
n, β, K = 20, 0.99, 100
μ, ρ, ν, S0, h0 = 0.0001, 0.1, 0.001, 10, 0
@jit(parallel=True)
def compute_call_price_parallel(β=β,
μ=μ,
S0=S0,
h0=h0,
K=K,
n=n,
ρ=ρ,
ν=ν,
M=M):
current_sum = 0.0
# 对每条样本路径
for m in prange(M):
s = np.log(S0)
h = h0
# 向前模拟
for t in range(n):
s = s + μ + np.exp(h) * np.random.randn()
h = ρ * h + ν * np.random.randn()
# 将 max{S_n - K, 0} 的值累加到 current_sum
current_sum += max(np.exp(s) - K, 0)
return β**n * current_sum / M
尝试在 parallel=True 和 parallel=False 之间切换,并注意运行时间的差异。
如果您使用的是具有多个 CPU 的机器,差异应该很显著。