12. SciPy#
除了 Anaconda 中已有的内容之外,本讲座还需要以下库:
!pip install --upgrade quantecon
我们使用以下导入语句。
import numpy as np
import quantecon as qe
12.1. 概述#
SciPy 构建在 NumPy 之上,为科学编程提供了常用工具,例如
与 NumPy 一样,SciPy 稳定、成熟且被广泛使用。
许多 SciPy 程序是对工业标准 Fortran 库(如 LAPACK、BLAS 等)的薄封装。
实际上没有必要将 SciPy 作为一个整体来”学习”。
更常见的做法是大致了解库中有什么,然后在需要时查阅文档。
在本讲座中,我们的目标仅是重点介绍该包中一些有用的部分。
12.2. SciPy 与 NumPy 的比较#
SciPy 是一个包含各种工具的包,这些工具构建在 NumPy 之上,使用其数组数据类型和相关功能。
Note
在较旧版本的 SciPy(scipy < 0.15.1)中,导入该包时也会将 NumPy 符号导入全局命名空间,从 SciPy 初始化文件的以下摘录可以看出:
from numpy import *
from numpy.random import rand, randn
from numpy.fft import fft, ifft
from numpy.lib.scimath import *
然而,更好的做法是显式使用 NumPy 功能。
import numpy as np
a = np.identity(3)
较新版本的 SciPy(1.15+)不再自动导入 NumPy 符号。
SciPy 中有用的部分是其子包中的功能
scipy.optimize、scipy.integrate、scipy.stats等。
让我们来探索一些主要的子包。
12.3. 统计#
scipy.stats 子包提供了
大量的随机变量对象(密度函数、累积分布、随机抽样等)
一些估计方法
一些统计检验
12.3.1. 随机变量与分布#
回想一下,numpy.random 提供了生成随机变量的工具
rng = np.random.default_rng()
rng.beta(5, 5, size=3)
array([0.56731482, 0.54944098, 0.32506521])
当 a, b = 5, 5 时,这从具有以下密度函数的分布中生成一个样本
有时我们需要访问密度函数本身,或者累积分布函数、分位数等。
为此,我们可以使用 scipy.stats,它在一个统一的接口中提供了所有这些功能以及随机数生成。
以下是一个使用示例
from scipy.stats import beta
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
q = beta(5, 5) # Beta(a, b),其中 a = b = 5
obs = q.rvs(2000) # 2000 个观测值
grid = np.linspace(0.01, 0.99, 100)
fig, ax = plt.subplots()
ax.hist(obs, bins=40, density=True)
ax.plot(grid, q.pdf(grid), 'k-', linewidth=2)
plt.show()
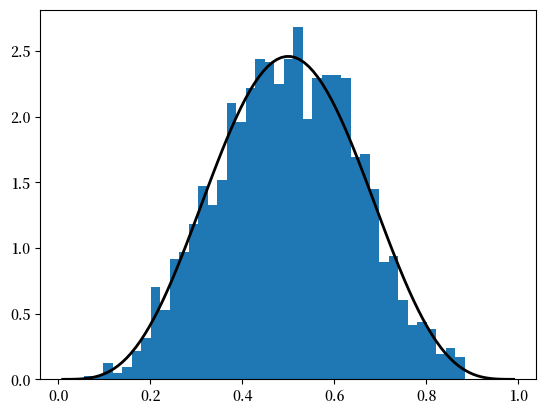
表示该分布的对象 q 还有其他有用的方法,包括
q.cdf(0.4) # 累积分布函数
np.float64(0.26656768000000003)
q.ppf(0.8) # 分位数(逆累积分布函数)函数
np.float64(0.6339134834642708)
q.mean()
np.float64(0.5)
创建这些表示分布的对象(类型为 rv_frozen)的一般语法为
name = scipy.stats.distribution_name(shape_parameters, loc=c, scale=d)
其中 distribution_name 是 scipy.stats 中的一个分布名称。
loc 和 scale 参数将原始随机变量 \(X\) 变换为 \(Y = c + d X\)。
12.3.2. 替代语法#
上述方法有另一种调用方式。
例如,生成上图的代码可以替换为
obs = beta.rvs(5, 5, size=2000)
grid = np.linspace(0.01, 0.99, 100)
fig, ax = plt.subplots()
ax.hist(obs, bins=40, density=True)
ax.plot(grid, beta.pdf(grid, 5, 5), 'k-', linewidth=2)
plt.show()
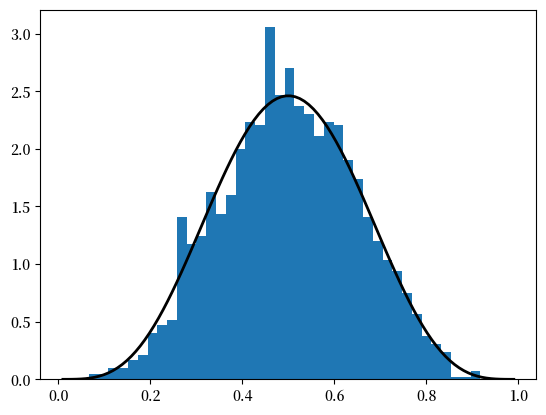
12.3.3. scipy.stats 中的其他功能#
scipy.stats 中有各种统计函数。
例如,scipy.stats.linregress 实现了简单线性回归
from scipy.stats import linregress
x = rng.standard_normal(200)
y = 2 * x + 0.1 * rng.standard_normal(200)
gradient, intercept, r_value, p_value, std_err = linregress(x, y)
gradient, intercept
(np.float64(2.000808611961976), np.float64(0.0034675460682290354))
要查看完整列表,请参阅 文档。
12.4. 根与不动点#
实函数 \(f\) 在 \([a,b]\) 上的根或零点是满足 \(f(x)=0\) 的 \(x \in [a, b]\)。
例如,如果我们绘制函数
其中 \(x \in [0,1]\),我们得到
f = lambda x: np.sin(4 * (x - 1/4)) + x + x**20 - 1
x = np.linspace(0, 1, 100)
fig, ax = plt.subplots()
ax.plot(x, f(x), label='$f(x)$')
ax.axhline(ls='--', c='k')
ax.set_xlabel('$x$', fontsize=12)
ax.set_ylabel('$f(x)$', fontsize=12)
ax.legend(fontsize=12)
plt.show()
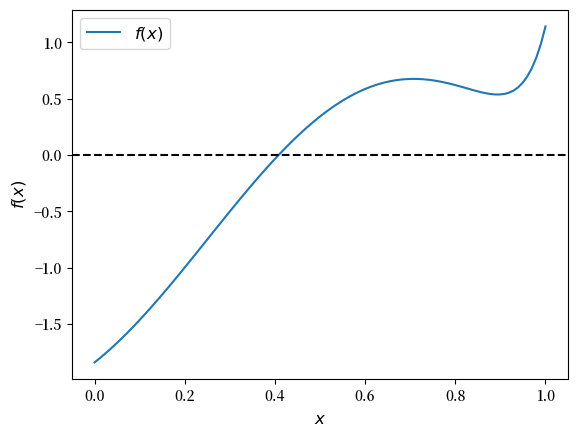
唯一的根大约为 0.408。
让我们考虑一些求根的数值方法。
12.4.1. 二分法#
数值求根最常见的算法之一是二分法。
为了理解这个思路,回忆一下一个众所周知的游戏:
玩家 A 心里想一个 1 到 100 之间的秘密数字
玩家 B 询问它是否小于 50
如果是,B 询问它是否小于 25
如果不是,B 询问它是否小于 75
如此反复。
这就是二分法。
以下是该算法在 Python 中的一个简单实现。
它适用于所有行为足够良好的单调递增连续函数,且满足 \(f(a) < 0 < f(b)\)
def bisect(f, a, b, tol=10e-5):
"""
实现二分法求根算法,假设 f 是 [a, b] 上的
实值函数,满足 f(a) < 0 < f(b)。
"""
lower, upper = a, b
while upper - lower > tol:
middle = 0.5 * (upper + lower)
if f(middle) > 0: # 根在 lower 和 middle 之间
lower, upper = lower, middle
else: # 根在 middle 和 upper 之间
lower, upper = middle, upper
return 0.5 * (upper + lower)
让我们用 (12.2) 中定义的函数 \(f\) 来测试它
bisect(f, 0, 1)
0.408294677734375
不出所料,SciPy 提供了自己的二分函数。
让我们用 (12.2) 中定义的同一函数 \(f\) 来测试它
from scipy.optimize import bisect
bisect(f, 0, 1)
0.4082935042806639
12.4.2. 牛顿-拉弗森法#
另一种非常常见的求根算法是牛顿-拉弗森法。
在 SciPy 中,该算法由 scipy.optimize.newton 实现。
与二分法不同,牛顿-拉弗森法使用局部斜率信息来尝试提高收敛速度。
让我们用上面定义的同一函数 \(f\) 来研究这个问题。
在合适的初始条件下,我们得到收敛:
from scipy.optimize import newton
newton(f, 0.2) # 在初始条件 x = 0.2 处开始搜索
np.float64(0.40829350427935673)
但其他初始条件会导致不收敛:
newton(f, 0.7) # 在 x = 0.7 处开始搜索
np.float64(0.7001700000000279)
12.4.3. 混合方法#
数值方法的一个基本原则如下:
如果您对给定问题有具体的了解,您可能可以利用它来提高效率。
如果没有,那么算法的选择涉及速度和鲁棒性之间的权衡。
在实践中,大多数用于求根、优化和不动点的默认算法都使用混合方法。
这些方法通常将快速方法与鲁棒方法结合起来,方式如下:
尝试使用快速方法
检查诊断信息
如果诊断信息不好,则切换到更鲁棒的算法
在 scipy.optimize 中,函数 brentq 就是这样一种混合方法,也是一个好的默认选择
from scipy.optimize import brentq
brentq(f, 0, 1)
0.40829350427936706
这里找到了正确的解,速度比二分法更快:
with qe.Timer(unit="milliseconds"):
brentq(f, 0, 1)
0.0501 ms elapsed
with qe.Timer(unit="milliseconds"):
bisect(f, 0, 1)
0.1078 ms elapsed
12.4.4. 多元求根#
使用 scipy.optimize.fsolve,这是 MINPACK 中混合方法的一个封装。
详情请参阅文档。
12.4.5. 不动点#
实函数 \(f\) 在 \([a,b]\) 上的不动点是满足 \(f(x)=x\) 的 \(x \in [a, b]\)。
SciPy 也有一个用于寻找(标量)不动点的函数
from scipy.optimize import fixed_point
fixed_point(lambda x: x**2, 10.0) # 10.0 是初始猜测值
array(1.)
如果结果不理想,您随时可以切换回 brentq 求根器,因为函数 \(f\) 的不动点是 \(g(x) := x - f(x)\) 的根。
12.5. 优化#
大多数数值包只提供最小化函数。
最大化可以通过以下方式实现:域 \(D\) 上函数 \(f\) 的最大化点等同于 \(-f\) 在 \(D\) 上的最小化点。
最小化与求根密切相关:对于光滑函数,内部最优点对应于一阶导数的根。
上述速度/鲁棒性权衡在数值优化中同样存在。
除非您有一些先验信息可以利用,否则通常最好使用混合方法。
对于有约束的单变量(即标量)最小化,一个好的混合选项是 fminbound
from scipy.optimize import fminbound
fminbound(lambda x: x**2, -1, 2) # 在 [-1, 2] 中搜索
np.float64(0.0)
12.5.1. 多元优化#
多元局部优化器包括 minimize、fmin、fmin_powell、fmin_cg、fmin_bfgs 和 fmin_ncg。
有约束的多元局部优化器包括 fmin_l_bfgs_b、fmin_tnc、fmin_cobyla。
详情请参阅文档。
12.6. 积分#
大多数数值积分方法通过计算近似多项式的积分来工作。
所产生的误差取决于多项式对被积函数的拟合程度,而这又取决于被积函数的”规则程度”。
在 SciPy 中,数值积分的相关模块是 scipy.integrate。
单变量积分的一个好的默认选择是 quad
from scipy.integrate import quad
integral, error = quad(lambda x: x**2, 0, 1)
integral
0.33333333333333337
实际上,quad 是 Fortran 库 QUADPACK 中一个非常标准的数值积分程序的接口。
它使用克伦肖-柯蒂斯求积,基于切比雪夫多项式展开。
单变量积分还有其他选项——一个有用的选项是 fixed_quad,它速度快,因此在 for 循环内效果很好。
还有用于多元积分的函数。
详情请参阅文档。
12.7. 线性代数#
我们看到 NumPy 提供了一个名为 linalg 的线性代数模块。
SciPy 也提供了一个同名的线性代数模块。
后者不是前者的严格超集,但总体上具有更多功能。
我们留给您自行探索可用程序集。
12.8. 练习#
前几个练习涉及在风险中性假设下为欧式看涨期权定价。价格满足
其中
\(\beta\) 是贴现因子,
\(n\) 是到期日,
\(K\) 是行权价,以及
\(\{S_t\}\) 是标的资产在每个时间 \(t\) 的价格。
例如,如果看涨期权是以行权价 \(K\) 购买亚马逊股票,则持有者有权(但没有义务)在 \(n\) 天后以价格 \(K\) 购买亚马逊 1 股股票。
因此,收益为 \(\max\{S_n - K, 0\}\)
价格是收益的期望值,贴现到当前价值。
Exercise 12.1
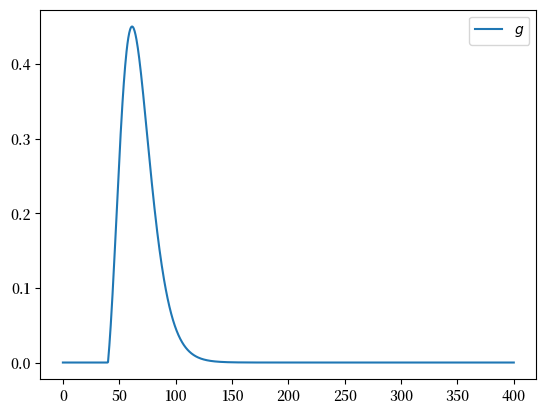
假设 \(S_n\) 服从参数为 \(\mu\) 和 \(\sigma\) 的对数正态分布。设 \(f\) 表示该分布的密度函数。则
在区间 \([0, 400]\) 上绘制函数
当 μ, σ, β, n, K = 4, 0.25, 0.99, 10, 40 时。
Hint
从 scipy.stats 中可以导入 lognorm,然后使用 lognorm.pdf(x, σ, scale=np.exp(μ)) 来获得密度函数 \(f\)。
Solution
以下是一种可能的解答
from scipy.integrate import quad
from scipy.stats import lognorm
μ, σ, β, n, K = 4, 0.25, 0.99, 10, 40
def g(x):
return β**n * np.maximum(x - K, 0) * lognorm.pdf(x, σ, scale=np.exp(μ))
x_grid = np.linspace(0, 400, 1000)
y_grid = g(x_grid)
fig, ax = plt.subplots()
ax.plot(x_grid, y_grid, label="$g$")
ax.legend()
plt.show()
Exercise 12.2
为了得到期权价格,使用 scipy.integrate 中的 quad 对该函数进行数值积分。
Solution
P, error = quad(g, 0, 1_000)
print(f"The numerical integration based option price is {P:.3f}")
The numerical integration based option price is 15.188
Exercise 12.3
尝试使用蒙特卡洛方法来计算期权价格中的期望项,而不是使用 quad,从而得到类似的结果。
特别地,利用以下事实:如果 \(S_n^1, \ldots, S_n^M\) 是从上述指定的对数正态分布中独立抽取的样本,那么根据大数定律,
设 M = 10_000_000
Solution
以下是一种解答:
rng = np.random.default_rng()
M = 10_000_000
S = np.exp(μ + σ * rng.standard_normal(M))
return_draws = np.maximum(S - K, 0)
P = β**n * np.mean(return_draws)
print(f"The Monte Carlo option price is {P:3f}")
The Monte Carlo option price is 15.187791
Solution
以下是一个合理的解答:
def bisect(f, a, b, tol=10e-5):
"""
实现二分法求根算法,假设 f 是 [a, b] 上的
实值函数,满足 f(a) < 0 < f(b)。
"""
lower, upper = a, b
if upper - lower < tol:
return 0.5 * (upper + lower)
else:
middle = 0.5 * (upper + lower)
print(f'Current mid point = {middle}')
if f(middle) > 0: # 意味着根在 lower 和 middle 之间
return bisect(f, lower, middle)
else: # 意味着根在 middle 和 upper 之间
return bisect(f, middle, upper)
我们可以如下测试它
f = lambda x: np.sin(4 * (x - 0.25)) + x + x**20 - 1
bisect(f, 0, 1)
Current mid point = 0.5
Current mid point = 0.25
Current mid point = 0.375
Current mid point = 0.4375
Current mid point = 0.40625
Current mid point = 0.421875
Current mid point = 0.4140625
Current mid point = 0.41015625
Current mid point = 0.408203125
Current mid point = 0.4091796875
Current mid point = 0.40869140625
Current mid point = 0.408447265625
Current mid point = 0.4083251953125
Current mid point = 0.40826416015625
0.408294677734375