8. OOP II:构建类#
8.1. 概述#
在前面的讲座中,我们学习了面向对象编程的一些基础知识。
本讲座的目标是
更深入地介绍面向对象编程
学习如何构建适合我们需求的自定义对象
例如,您已经知道如何
创建列表、字符串和其他 Python 对象
使用它们的方法来修改其内容
现在假设您想编写一个包含消费者的程序,消费者可以
持有和花费现金
消费商品
工作并赚取现金
在 Python 中,一个自然的解决方案是将消费者创建为具有以下内容的对象
数据,例如手头的现金
方法,例如影响此数据的
buy或work
Python 通过提供类定义使这一切变得容易。
类是帮助您根据自己的规格构建对象的蓝图。
语法需要一些时间来适应,所以我们将提供大量示例。
我们将使用以下导入:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
8.2. 面向对象编程回顾#
面向对象编程在许多语言中都有支持:
JAVA 和 Ruby 是相对纯粹的面向对象编程语言。
Python 同时支持过程式和面向对象编程。
Fortran 和 MATLAB 主要是过程式的,最近才添加了一些面向对象的特性。
C 是过程式语言,而 C++ 是在 C 之上添加了面向对象编程。
在专门介绍 Python 之前,让我们先介绍一般的面向对象编程概念。
8.2.1. 核心概念#
如前面的讲座所讨论的,在面向对象编程范式中,数据和函数被捆绑在一起形成”对象”。
一个例子是 Python 列表,它不仅存储数据,还知道如何对自身排序等。
x = [1, 5, 4]
x.sort()
x
[1, 4, 5]
正如我们现在所知,sort 是一个”属于”列表对象的函数——因此被称为方法。
如果我们想创建自己的对象类型,就需要使用类定义。
类定义是特定类对象(例如列表、字符串或复数)的蓝图。
它描述了
该类存储什么类型的数据
它有什么方法来操作这些数据
对象或实例是从蓝图创建的类的一个具体实现
每个实例都有其自己独特的数据。
在类定义中设定的方法作用于这些(及其他)数据。
在 Python 中,对象的数据和方法统称为属性。
属性通过”点属性表示法”访问
object_name.dataobject_name.method_name()
在以下示例中
x = [1, 5, 4]
x.sort()
x.__class__
list
x是从 Python 列表定义创建的对象或实例,但具有其自己的特定数据。x.sort()和x.__class__是x的两个属性。dir(x)可用于查看x的所有属性。
8.2.2. 面向对象编程为何有用?#
面向对象编程有用的原因与抽象有用的原因相同:识别和利用共同结构。
例如,
马尔可夫链由一组状态、状态上的初始概率分布以及跨状态转移的概率集合组成
一般均衡理论由商品空间、偏好、技术和均衡定义组成
博弈由玩家列表、每个玩家可采取的行动列表、每个玩家的收益(作为所有其他玩家行动的函数)以及时序协议组成
这些都是将相同”类型”的”对象”收集在一起的抽象。
识别共同结构使我们能够使用通用工具。
在经济理论中,这可能是适用于某种类型所有博弈的命题。
在 Python 中,这可能是对所有马尔可夫链都有用的方法(例如 simulate)。
当我们使用面向对象编程时,simulate 方法便捷地与马尔可夫链对象捆绑在一起。
8.3. 定义您自己的类#
让我们首先构建一些简单的类。
在此之前,为了展示类的一些功能,我们将定义两个函数,分别称为 earn 和 spend。
def earn(w,y):
"Consumer with inital wealth w earns y"
return w+y
def spend(w,x):
"consumer with initial wealth w spends x"
new_wealth = w -x
if new_wealth < 0:
print("Insufficient funds")
else:
return new_wealth
earn 函数接受消费者的初始财富 \(w\) 并将其当前收入 \(y\) 加到其中。
spend 函数接受消费者的初始财富 \(w\) 并从中扣除其当前支出 \(x\)。
我们可以使用这两个函数来跟踪消费者在赚取和花费时的财富变化。
例如
w0=100
w1=earn(w0,10)
w2=spend(w1,20)
w3=earn(w2,10)
w4=spend(w3,20)
print("w0,w1,w2,w3,w4 = ", w0,w1,w2,w3,w4)
w0,w1,w2,w3,w4 = 100 110 90 100 80
类将与特定实例绑定的一组数据与一组对数据进行操作的函数捆绑在一起。
在我们的示例中,实例将是特定人的名字,其实例数据仅由其财富组成。
(在其他示例中,实例数据将由一组数据向量组成。)
在我们的示例中,earn 和 spend 两个函数可以应用于当前的实例数据。
实例数据和函数合称为属性。
这些可以按我们现在将要描述的方式方便地访问。
8.3.1. 示例:消费者类#
我们将构建一个 Consumer 类,具有
存储消费者财富的
wealth属性(数据)一个
earn方法,其中earn(y)将消费者的财富增加y一个
spend方法,其中spend(x)要么将财富减少x,要么在资金不足时返回错误
尽管有些刻意,这个类的示例帮助我们内化一些特殊的语法。
以下是我们如何设置消费者类。
class Consumer:
def __init__(self, w):
"Initialize consumer with w dollars of wealth"
self.wealth = w
def earn(self, y):
"The consumer earns y dollars"
self.wealth += y
def spend(self, x):
"The consumer spends x dollars if feasible"
new_wealth = self.wealth - x
if new_wealth < 0:
print("Insufficent funds")
else:
self.wealth = new_wealth
这里有一些特殊语法,让我们仔细逐步分析
class关键字表示我们正在构建一个类。
Consumer 类定义了实例数据 wealth 和三个方法:__init__、earn 和 spend
wealth是实例数据,因为我们创建的每个消费者(Consumer类的每个实例)将拥有其自己的财富数据。
earn 和 spend 方法部署了我们之前描述的函数,这些函数可以潜在地应用于 wealth 实例数据。
__init__ 方法是构造方法。
每次创建类的实例时,__init__ 方法都会自动被调用。
调用 __init__ 会设置一个”命名空间”来保存实例数据——稍后我们会详细介绍。
我们还将在下面详细讨论特殊的 self 记账设备的作用。
8.3.1.1. 用法#
以下是一个使用 Consumer 类创建消费者实例的示例,我们亲切地将其命名为 \(c1\)。
创建消费者 \(c1\) 并赋予其初始财富 \(10\) 后,我们将应用 spend 方法。
c1 = Consumer(10) # Create instance with initial wealth 10
c1.spend(5)
c1.wealth
5
c1.earn(15)
c1.spend(100)
Insufficent funds
我们当然可以创建多个实例,即多个消费者,每个都有自己的名字和数据
c1 = Consumer(10)
c2 = Consumer(12)
c2.spend(4)
c2.wealth
8
c1.wealth
10
每个实例,即每个消费者,将其数据存储在一个单独的命名空间字典中
c1.__dict__
{'wealth': 10}
c2.__dict__
{'wealth': 8}
当我们访问或设置属性时,我们实际上只是在修改由实例维护的字典。
8.3.1.2. Self#
如果您再次查看 Consumer 类定义,您会在整个代码中看到 self 这个词。
在创建类时使用 self 的规则是
任何实例数据都应以
self为前缀例如,
earn方法使用self.wealth而不仅仅是wealth
在定义类的代码中定义的方法应以
self作为第一个参数例如,
def earn(self, y)而不仅仅是def earn(y)
在类内引用的任何方法都应以
self.method_name的形式调用
在前面的代码中没有最后一条规则的示例,但我们很快会看到一些。
8.3.1.3. 详情#
在本节中,我们将研究与类和 self 相关的一些更正式的细节
您在第一次阅读本讲座时可能希望跳过下一节。
在您熟悉了更多示例之后,可以返回这些细节。
方法实际上存储在解释器读取类定义时形成的类对象中
print(Consumer.__dict__) # Show __dict__ attribute of class object
{'__module__': '__main__', '__firstlineno__': 1, '__init__': <function Consumer.__init__ at 0x7f0787fe4400>, 'earn': <function Consumer.earn at 0x7f0787fe4540>, 'spend': <function Consumer.spend at 0x7f0787fe45e0>, '__static_attributes__': ('wealth',), '__dict__': <attribute '__dict__' of 'Consumer' objects>, '__weakref__': <attribute '__weakref__' of 'Consumer' objects>, '__doc__': None}
注意三个方法 __init__、earn 和 spend 是如何存储在类对象中的。
考虑以下代码
c1 = Consumer(10)
c1.earn(10)
c1.wealth
20
当您通过 c1.earn(10) 调用 earn 时,解释器将实例 c1 和参数 10 传递给 Consumer.earn。
实际上,以下两者是等价的
c1.earn(10)Consumer.earn(c1, 10)
在函数调用 Consumer.earn(c1, 10) 中,注意 c1 是第一个参数。
回想一下,在 earn 方法的定义中,self 是第一个参数
def earn(self, y):
"The consumer earns y dollars"
self.wealth += y
最终结果是 self 在函数调用中被绑定到实例 c1。
这就是为什么 earn 中的语句 self.wealth += y 最终修改了 c1.wealth。
8.3.2. 示例:索洛增长模型#
对于下一个示例,让我们编写一个简单的类来实现索洛增长模型。
索洛增长模型是一个新古典增长模型,其中人均资本存量 \(k_t\) 按以下规则演变
这里
\(s\) 是外生给定的储蓄率
\(z\) 是生产率参数
\(\alpha\) 是资本的收入份额
\(n\) 是人口增长率
\(\delta\) 是折旧率
该模型的稳态是当 \(k_{t+1} = k_t = k\) 时满足 (8.1) 的 \(k\)。
以下是实现该模型的类。
代码中一些值得注意的点是
实例在变量
self.k中记录其当前资本存量。h方法实现 (8.1) 的右侧。update方法使用h按照 (8.1) 更新资本。注意在
update内部,对局部方法h的引用是self.h。
方法 steady_state 和 generate_sequence 相当直观
class Solow:
r"""
Implements the Solow growth model with the update rule
k_{t+1} = [(s z k^α_t) + (1 - δ)k_t] /(1 + n)
"""
def __init__(self, n=0.05, # population growth rate
s=0.25, # savings rate
δ=0.1, # depreciation rate
α=0.3, # share of labor
z=2.0, # productivity
k=1.0): # current capital stock
self.n, self.s, self.δ, self.α, self.z = n, s, δ, α, z
self.k = k
def h(self):
"Evaluate the h function"
# Unpack parameters (get rid of self to simplify notation)
n, s, δ, α, z = self.n, self.s, self.δ, self.α, self.z
# Apply the update rule
return (s * z * self.k**α + (1 - δ) * self.k) / (1 + n)
def update(self):
"Update the current state (i.e., the capital stock)."
self.k = self.h()
def steady_state(self):
"Compute the steady state value of capital."
# Unpack parameters (get rid of self to simplify notation)
n, s, δ, α, z = self.n, self.s, self.δ, self.α, self.z
# Compute and return steady state
return ((s * z) / (n + δ))**(1 / (1 - α))
def generate_sequence(self, t):
"Generate and return a time series of length t"
path = []
for i in range(t):
path.append(self.k)
self.update()
return path
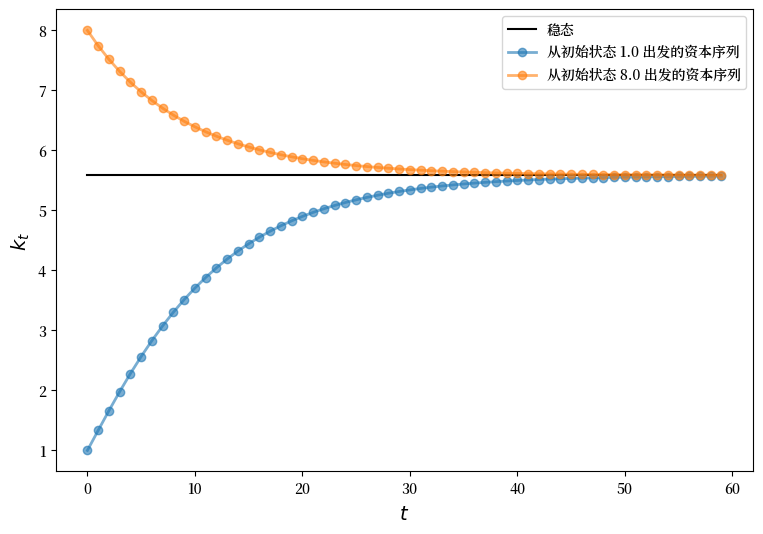
以下是一个使用该类从两个不同初始条件计算时间序列的小程序。
还绘制了共同的稳态以供比较
s1 = Solow()
s2 = Solow(k=8.0)
T = 60
fig, ax = plt.subplots(figsize=(9, 6))
# 绘制共同的稳态资本值
ax.plot([s1.steady_state()]*T, 'k-', label='稳态')
# 绘制每个经济体的时间序列
for s in s1, s2:
lb = f'从初始状态 {s.k} 出发的资本序列'
ax.plot(s.generate_sequence(T), 'o-', lw=2, alpha=0.6, label=lb)
ax.set_xlabel('$t$', fontsize=14)
ax.set_ylabel('$k_t$', fontsize=14)
ax.legend()
plt.show()
8.3.3. 示例:市场#
接下来,让我们为买卖双方都是价格接受者的竞争市场编写一个类。
该市场由以下对象组成:
线性需求曲线 \(Q = a_d - b_d p\)
线性供给曲线 \(Q = a_z + b_z (p - t)\)
这里
\(p\) 是买方支付的价格,\(Q\) 是数量,\(t\) 是单位税。
其他符号是需求和供给参数。
该类提供计算各种感兴趣值的方法,包括竞争均衡价格和数量、税收收入、消费者剩余和生产者剩余。
以下是我们的实现。
(它使用 SciPy 中的 quad 函数进行数值积分——这是我们稍后将详细介绍的主题。)
from scipy.integrate import quad
class Market:
def __init__(self, ad, bd, az, bz, tax):
"""
Set up market parameters. All parameters are scalars. See
https://lectures.quantecon.org/py/python_oop.html for interpretation.
"""
self.ad, self.bd, self.az, self.bz, self.tax = ad, bd, az, bz, tax
if ad < az:
raise ValueError('Insufficient demand.')
def price(self):
"Compute equilibrium price"
return (self.ad - self.az + self.bz * self.tax) / (self.bd + self.bz)
def quantity(self):
"Compute equilibrium quantity"
return self.ad - self.bd * self.price()
def consumer_surp(self):
"Compute consumer surplus"
# == Compute area under inverse demand function == #
integrand = lambda x: (self.ad / self.bd) - (1 / self.bd) * x
area, error = quad(integrand, 0, self.quantity())
return area - self.price() * self.quantity()
def producer_surp(self):
"Compute producer surplus"
# == Compute area above inverse supply curve, excluding tax == #
integrand = lambda x: -(self.az / self.bz) + (1 / self.bz) * x
area, error = quad(integrand, 0, self.quantity())
return (self.price() - self.tax) * self.quantity() - area
def taxrev(self):
"Compute tax revenue"
return self.tax * self.quantity()
def inverse_demand(self, x):
"Compute inverse demand"
return self.ad / self.bd - (1 / self.bd)* x
def inverse_supply(self, x):
"Compute inverse supply curve"
return -(self.az / self.bz) + (1 / self.bz) * x + self.tax
def inverse_supply_no_tax(self, x):
"Compute inverse supply curve without tax"
return -(self.az / self.bz) + (1 / self.bz) * x
以下是使用示例
baseline_params = 15, .5, -2, .5, 3
m = Market(*baseline_params)
print("equilibrium price = ", m.price())
equilibrium price = 18.5
print("consumer surplus = ", m.consumer_surp())
consumer surplus = 33.0625
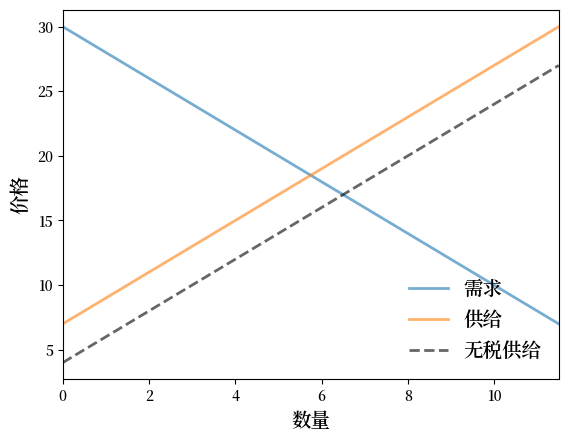
以下是一个使用该类绘制逆需求曲线以及有税和无税的逆供给曲线的短程序
# 基准参数 ad, bd, az, bz, tax
baseline_params = 15, .5, -2, .5, 3
m = Market(*baseline_params)
q_max = m.quantity() * 2
q_grid = np.linspace(0.0, q_max, 100)
pd = m.inverse_demand(q_grid)
ps = m.inverse_supply(q_grid)
psno = m.inverse_supply_no_tax(q_grid)
fig, ax = plt.subplots()
ax.plot(q_grid, pd, lw=2, alpha=0.6, label='需求')
ax.plot(q_grid, ps, lw=2, alpha=0.6, label='供给')
ax.plot(q_grid, psno, '--k', lw=2, alpha=0.6, label='无税供给')
ax.set_xlabel('数量', fontsize=14)
ax.set_xlim(0, q_max)
ax.set_ylabel('价格', fontsize=14)
ax.legend(loc='lower right', frameon=False, fontsize=14)
plt.show()
下一个程序提供了一个函数,该函数
以
Market的一个实例作为参数计算因征税而产生的无谓损失
def deadw(m):
"Computes deadweight loss for market m."
# == Create analogous market with no tax == #
m_no_tax = Market(m.ad, m.bd, m.az, m.bz, 0)
# == Compare surplus, return difference == #
surp1 = m_no_tax.consumer_surp() + m_no_tax.producer_surp()
surp2 = m.consumer_surp() + m.producer_surp() + m.taxrev()
return surp1 - surp2
以下是使用示例
baseline_params = 15, .5, -2, .5, 3
m = Market(*baseline_params)
deadw(m) # Show deadweight loss
1.125
8.3.4. 示例:混沌#
让我们再看一个示例,与非线性系统中的混沌动力学相关。
一个可以产生不规则时间路径的简单转移规则是逻辑斯谛映射
让我们为从该模型生成时间序列编写一个类。
以下是一种实现
class Chaos:
"""
Models the dynamical system :math:`x_{t+1} = r x_t (1 - x_t)`
"""
def __init__(self, x0, r):
"""
Initialize with state x0 and parameter r
"""
self.x, self.r = x0, r
def update(self):
"Apply the map to update state."
self.x = self.r * self.x *(1 - self.x)
def generate_sequence(self, n):
"Generate and return a sequence of length n."
path = []
for i in range(n):
path.append(self.x)
self.update()
return path
以下是使用示例
ch = Chaos(0.1, 4.0) # x0 = 0.1 and r = 0.4
ch.generate_sequence(5) # First 5 iterates
[0.1, 0.36000000000000004, 0.9216, 0.28901376000000006, 0.8219392261226498]
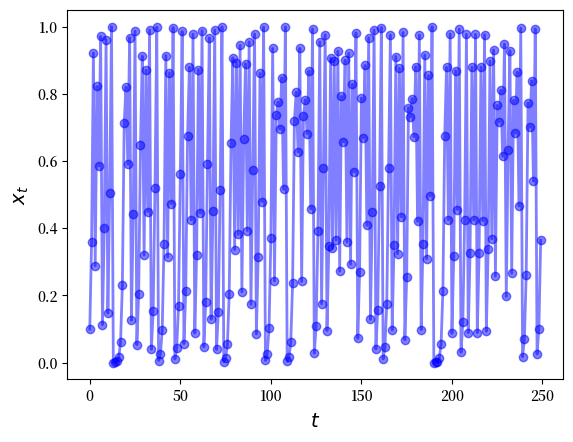
以下代码绘制了一个较长的轨迹
ch = Chaos(0.1, 4.0)
ts_length = 250
fig, ax = plt.subplots()
ax.set_xlabel('$t$', fontsize=14)
ax.set_ylabel('$x_t$', fontsize=14)
x = ch.generate_sequence(ts_length)
ax.plot(range(ts_length), x, 'bo-', alpha=0.5, lw=2, label='$x_t$')
plt.show()
下一段代码提供了一个分岔图
fig, ax = plt.subplots()
ch = Chaos(0.1, 4)
r = 2.5
while r < 4:
ch.r = r
t = ch.generate_sequence(1000)[950:]
ax.plot([r] * len(t), t, 'b.', ms=0.6)
r = r + 0.005
ax.set_xlabel('$r$', fontsize=16)
ax.set_ylabel('$x_t$', fontsize=16)
plt.show()
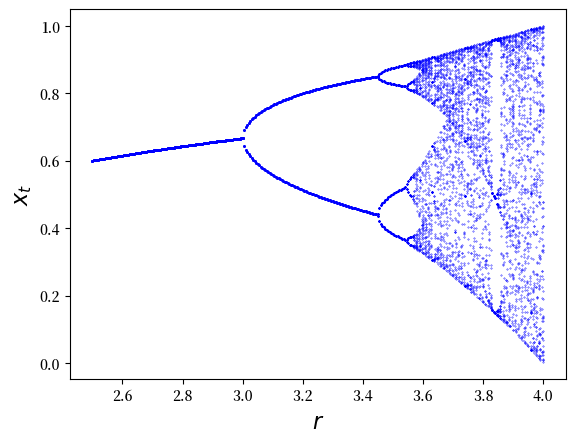
横轴是 (8.2) 中的参数 \(r\)。
纵轴是状态空间 \([0, 1]\)。
对于每个 \(r\),我们计算一个长时间序列,然后绘制其尾部(最后 50 个点)。
序列的尾部显示了轨迹在收敛到某种稳态(如果稳态存在)后的集中位置。
它是否收敛,以及它所收敛到的稳态的特征,取决于 \(r\) 的值。
对于 \(r\) 大约在 2.5 到 3 之间,时间序列收敛到纵轴上绘制的单个不动点。
对于 \(r\) 大约在 3 到 3.45 之间,时间序列收敛到在纵轴上绘制的两个值之间振荡。
对于 \(r\) 稍高于 3.45,时间序列收敛到在纵轴上绘制的四个值之间振荡。
注意没有任何 \(r\) 的值会导致在三个值之间振荡的稳态。
8.4. 特殊方法#
Python 提供了一些非常方便的特殊方法。
例如,回想一下列表和元组有长度的概念,可以通过 len 函数查询
x = (10, 20)
len(x)
2
如果您想在将 len 函数应用于您的用户自定义对象时提供返回值,请使用 __len__ 特殊方法
class Foo:
def __len__(self):
return 42
现在我们得到
f = Foo()
len(f)
42
我们将定期使用的一个特殊方法是 __call__ 方法。
此方法可用于使您的实例像函数一样可调用
class Foo:
def __call__(self, x):
return x + 42
运行后我们得到
f = Foo()
f(8) # Exactly equivalent to f.__call__(8)
50
练习 1 提供了一个更有用的示例。
8.5. 练习#
Exercise 8.1
对应于样本 \(\{X_i\}_{i=1}^n\) 的经验累积分布函数(ecdf)定义为
这里 \(\mathbf{1}\{X_i \leq x\}\) 是指示函数(如果 \(X_i \leq x\) 则为 1,否则为 0),因此 \(F_n(x)\) 是样本中落在 \(x\) 以下的比例。
Glivenko-Cantelli 定理指出,只要样本是独立同分布的,经验累积分布函数 \(F_n\) 就会收敛到真实分布函数 \(F\)。
将 \(F_n\) 实现为一个名为 ECDF 的类,其中
给定的样本 \(\{X_i\}_{i=1}^n\) 是实例数据,存储为
self.observations。该类实现了一个
__call__方法,对任意 \(x\) 返回 \(F_n(x)\)。
您的代码应按如下方式工作(随机性除外)
from random import uniform
samples = [uniform(0, 1) for i in range(10)]
F = ECDF(samples)
F(0.5) # Evaluate ecdf at x = 0.5
F.observations = [uniform(0, 1) for i in range(1000)]
F(0.5)
追求清晰,而非效率。
Solution
class ECDF:
def __init__(self, observations):
self.observations = observations
def __call__(self, x):
counter = 0.0
for obs in self.observations:
if obs <= x:
counter += 1
return counter / len(self.observations)
# == 测试 == #
from random import uniform
samples = [uniform(0, 1) for i in range(10)]
F = ECDF(samples)
print(F(0.5)) # 在 x = 0.5 处评估经验累积分布函数
F.observations = [uniform(0, 1) for i in range(1000)]
print(F(0.5))
0.7
0.486
Exercise 8.2
在前面的练习中,您编写了一个用于计算多项式的函数。
本练习是对其的扩展,任务是构建一个名为 Polynomial 的简单类,用于表示和操作多项式函数,例如
Polynomial 类的实例数据将是系数(在 (8.4) 的情况下,是数字 \(a_0, \ldots, a_N\))。
提供以下方法
计算多项式 (8.4),对任意 \(x\) 返回 \(p(x)\)。
对多项式求导,用其导数 \(p'\) 的系数替换原始系数。
避免使用任何 import 语句。
Solution
class Polynomial:
def __init__(self, coefficients):
"""
Creates an instance of the Polynomial class representing
p(x) = a_0 x^0 + ... + a_N x^N,
where a_i = coefficients[i].
"""
self.coefficients = coefficients
def __call__(self, x):
"Evaluate the polynomial at x."
y = 0
for i, a in enumerate(self.coefficients):
y += a * x**i
return y
def differentiate(self):
"Reset self.coefficients to those of p' instead of p."
new_coefficients = []
for i, a in enumerate(self.coefficients):
new_coefficients.append(i * a)
# Remove the first element, which is zero
del new_coefficients[0]
# And reset coefficients data to new values
self.coefficients = new_coefficients
return new_coefficients