17. Pandas#
除了 Anaconda 中已有的内容之外,本讲座还需要以下库:
!pip install --upgrade wbgapi
!pip install --upgrade yfinance
17.1. 概述#
Pandas 是一个用于 Python 的快速、高效的数据分析工具包。
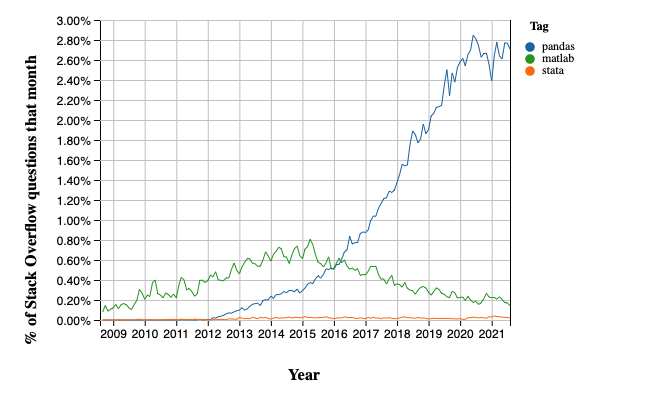
近年来,随着数据科学和机器学习等领域的兴起,其受欢迎程度急剧上升。
以下是来自 Stack Overflow Trends 的与 Matlab 和 STATA 的历史受欢迎程度比较:
正如 NumPy 提供基本的数组数据类型和核心数组操作一样,pandas
定义了用于处理数据的基础结构,并且
赋予了它们便于执行以下操作的方法:
读入数据
调整索引
处理日期和时间序列
排序、分组、重新排序和一般数据整理 [1]
处理缺失值,等等
更复杂的统计功能留给其他包,如构建在 pandas 之上的 statsmodels 和 scikit-learn。
本讲座将提供 pandas 的基本介绍。
在整个讲座中,我们将假设已进行了以下导入:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl # i18n
import matplotlib.font_manager # i18n
import requests
FONTPATH = "_fonts/SourceHanSerifSC-SemiBold.otf" # i18n
mpl.font_manager.fontManager.addfont(FONTPATH) # i18n
mpl.rcParams['font.family'] = ['Source Han Serif SC'] # i18n
pandas 定义的两种重要数据类型是 Series 和 DataFrame。
你可以将 Series 视为数据的”一列”,例如对单个变量的一组观测值。
DataFrame 是一个二维对象,用于存储相关的数据列。
17.2. Series#
让我们从 Series 开始。
我们首先创建一个包含四个随机观测值的 Series:
s = pd.Series(np.random.randn(4), name='每日收益')
s
0 0.100885
1 -0.962581
2 -0.053455
3 -1.085028
Name: 每日收益, dtype: float64
在这里,你可以将索引 0, 1, 2, 3 想象为四家上市公司的编号,而值则是它们股票的每日收益。
pandas 的 Series 建立在 NumPy 数组之上,支持许多类似的操作:
s * 100
0 10.088454
1 -96.258109
2 -5.345509
3 -108.502754
Name: 每日收益, dtype: float64
np.abs(s)
0 0.100885
1 0.962581
2 0.053455
3 1.085028
Name: 每日收益, dtype: float64
但 Series 提供的功能比 NumPy 数组更多。
它们不仅有一些额外的(面向统计的)方法:
s.describe()
count 4.000000
mean -0.500045
std 0.610110
min -1.085028
25% -0.993193
50% -0.508018
75% -0.014870
max 0.100885
Name: 每日收益, dtype: float64
而且它们的索引更加灵活:
s.index = ['AMZN', 'AAPL', 'MSFT', 'GOOG']
s
AMZN 0.100885
AAPL -0.962581
MSFT -0.053455
GOOG -1.085028
Name: 每日收益, dtype: float64
从这个角度来看,Series 就像快速、高效的 Python 字典(限制是字典中的所有项目具有相同的类型——在本例中为浮点数)。
事实上,你可以使用与 Python 字典相同的许多语法:
s['AMZN']
np.float64(0.10088454120138937)
s['AMZN'] = 0
s
AMZN 0.000000
AAPL -0.962581
MSFT -0.053455
GOOG -1.085028
Name: 每日收益, dtype: float64
'AAPL' in s
True
17.3. DataFrames#
Series 是单列数据,而 DataFrame 是多列数据,每个变量对应一列。
本质上,pandas 中的 DataFrame 类似于(高度优化的)Excel 电子表格。
因此,它是表示和分析自然组织成行和列的数据的强大工具,通常具有用于单个行和单个列的描述性索引。
让我们看一个从 CSV 文件 pandas/data/test_pwt.csv 读取数据的示例,该文件取自 Penn World Tables。
该数据集包含以下指标:
变量名 |
描述 |
|---|---|
POP |
人口(千人) |
XRAT |
对美元汇率 |
tcgdp |
PPP 转换后的总国内生产总值(百万国际元) |
cc |
PPP 转换后人均国内生产总值的消费份额(%) |
cg |
PPP 转换后人均国内生产总值的政府消费份额(%) |
我们将使用 pandas 函数 read_csv 从 URL 读取数据。
df = pd.read_csv('https://raw.githubusercontent.com/QuantEcon/lecture-python-programming/main/lectures/_static/lecture_specific/pandas/data/test_pwt.csv')
type(df)
pandas.core.frame.DataFrame
以下是 test_pwt.csv 的内容:
df
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.653 | 0.999500 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000 | 19053.186 | 1.724830 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000 | 1006300.297 | 44.941600 | 1.728144e+06 | 64.575551 | 14.072206 |
| 3 | Israel | ISR | 2000 | 6114.570 | 4.077330 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000 | 11801.505 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.939830 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000 | 282171.957 | 1.000000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000 | 3219.793 | 12.099592 | 2.525596e+04 | 78.978740 | 5.108068 |
17.3.1. 按位置选择数据#
在实践中,我们经常需要查找、选择并处理我们感兴趣的数据子集。
我们可以使用标准 Python 数组切片符号选择特定行:
df[2:5]
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 2 | India | IND | 2000 | 1006300.297 | 44.941600 | 1.728144e+06 | 64.575551 | 14.072206 |
| 3 | Israel | ISR | 2000 | 6114.570 | 4.077330 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000 | 11801.505 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
要选择列,我们可以传递一个包含所需列名(以字符串表示)的列表:
df[['country', 'tcgdp']]
| country | tcgdp | |
|---|---|---|
| 0 | Argentina | 2.950722e+05 |
| 1 | Australia | 5.418047e+05 |
| 2 | India | 1.728144e+06 |
| 3 | Israel | 1.292539e+05 |
| 4 | Malawi | 5.026222e+03 |
| 5 | South Africa | 2.272424e+05 |
| 6 | United States | 9.898700e+06 |
| 7 | Uruguay | 2.525596e+04 |
要使用整数选择行和列,应使用 iloc 属性,格式为 .iloc[行, 列]:
df.iloc[2:5, 0:4]
| country | country isocode | year | POP | |
|---|---|---|---|---|
| 2 | India | IND | 2000 | 1006300.297 |
| 3 | Israel | ISR | 2000 | 6114.570 |
| 4 | Malawi | MWI | 2000 | 11801.505 |
要使用整数和标签的混合选择行和列,可以以类似方式使用 loc 属性:
df.loc[df.index[2:5], ['country', 'tcgdp']]
| country | tcgdp | |
|---|---|---|
| 2 | India | 1.728144e+06 |
| 3 | Israel | 1.292539e+05 |
| 4 | Malawi | 5.026222e+03 |
17.3.2. 按条件选择数据#
除了使用整数和名称索引行和列外,我们还可以获取满足某些(可能较复杂)条件的数据子框架。
本节演示各种实现方法。
最直接的方式是使用 [] 运算符:
df[df.POP >= 20000]
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.653 | 0.99950 | 2.950722e+05 | 75.716805 | 5.578804 |
| 2 | India | IND | 2000 | 1006300.297 | 44.94160 | 1.728144e+06 | 64.575551 | 14.072206 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.93983 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000 | 282171.957 | 1.00000 | 9.898700e+06 | 72.347054 | 6.032454 |
要理解这里发生了什么,注意 df.POP >= 20000 返回一系列布尔值:
df.POP >= 20000
0 True
1 False
2 True
3 False
4 False
5 True
6 True
7 False
Name: POP, dtype: bool
在这种情况下,df[___] 接受一系列布尔值,只返回值为 True 的行。
再看一个示例:
df[(df.country.isin(['Argentina', 'India', 'South Africa'])) & (df.POP > 40000)]
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 2 | India | IND | 2000 | 1006300.297 | 44.94160 | 1.728144e+06 | 64.575551 | 14.072206 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.93983 | 2.272424e+05 | 72.718710 | 5.726546 |
然而,还有另一种方法可以做到同样的事情,对于大型数据框,它可能稍快一些,且语法更自然:
# 上面的代码等价于
df.query("POP >= 20000")
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.653 | 0.99950 | 2.950722e+05 | 75.716805 | 5.578804 |
| 2 | India | IND | 2000 | 1006300.297 | 44.94160 | 1.728144e+06 | 64.575551 | 14.072206 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.93983 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000 | 282171.957 | 1.00000 | 9.898700e+06 | 72.347054 | 6.032454 |
df.query("country in ['Argentina', 'India', 'South Africa'] and POP > 40000")
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 2 | India | IND | 2000 | 1006300.297 | 44.94160 | 1.728144e+06 | 64.575551 | 14.072206 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.93983 | 2.272424e+05 | 72.718710 | 5.726546 |
我们还可以允许不同列之间的算术运算:
df[(df.cc + df.cg >= 80) & (df.POP <= 20000)]
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 4 | Malawi | MWI | 2000 | 11801.505 | 59.543808 | 5026.221784 | 74.707624 | 11.658954 |
| 7 | Uruguay | URY | 2000 | 3219.793 | 12.099592 | 25255.961693 | 78.978740 | 5.108068 |
# 上面的代码等价于
df.query("cc + cg >= 80 & POP <= 20000")
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 4 | Malawi | MWI | 2000 | 11801.505 | 59.543808 | 5026.221784 | 74.707624 | 11.658954 |
| 7 | Uruguay | URY | 2000 | 3219.793 | 12.099592 | 25255.961693 | 78.978740 | 5.108068 |
例如,我们可以使用条件来选择家庭消费占 GDP 份额 cc 最大的国家:
df.loc[df.cc == max(df.cc)]
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 7 | Uruguay | URY | 2000 | 3219.793 | 12.099592 | 25255.961693 | 78.97874 | 5.108068 |
当我们只想查看选定子数据框的某些列时,可以将上述条件与 .loc[__ , __] 命令结合使用。
第一个参数接受条件,第二个参数接受我们想要返回的列的列表:
df.loc[(df.cc + df.cg >= 80) & (df.POP <= 20000), ['country', 'year', 'POP']]
| country | year | POP | |
|---|---|---|---|
| 4 | Malawi | 2000 | 11801.505 |
| 7 | Uruguay | 2000 | 3219.793 |
应用:对数据框进行子集化
现实世界的数据集可能 非常庞大。
有时需要使用数据的子集来提高计算效率并减少冗余。
假设我们只对人口(POP)和总 GDP(tcgdp)感兴趣。
将数据框 df 缩减为仅包含这些变量的一种方法是使用上述选择方法覆盖数据框:
df_subset = df[['country', 'POP', 'tcgdp']]
df_subset
| country | POP | tcgdp | |
|---|---|---|---|
| 0 | Argentina | 37335.653 | 2.950722e+05 |
| 1 | Australia | 19053.186 | 5.418047e+05 |
| 2 | India | 1006300.297 | 1.728144e+06 |
| 3 | Israel | 6114.570 | 1.292539e+05 |
| 4 | Malawi | 11801.505 | 5.026222e+03 |
| 5 | South Africa | 45064.098 | 2.272424e+05 |
| 6 | United States | 282171.957 | 9.898700e+06 |
| 7 | Uruguay | 3219.793 | 2.525596e+04 |
然后我们可以保存较小的数据集以供进一步分析:
df_subset.to_csv('pwt_subset.csv', index=False)
17.3.3. Apply 方法#
另一个广泛使用的 pandas 方法是 df.apply()。
它将函数应用于每行/列并返回一个 Series。
这个函数可以是一些内置函数(如 max 函数)、lambda 函数或用户自定义函数。
以下是使用 max 函数的示例:
df[['year', 'POP', 'XRAT', 'tcgdp', 'cc', 'cg']].apply(max)
year 2.000000e+03
POP 1.006300e+06
XRAT 5.954381e+01
tcgdp 9.898700e+06
cc 7.897874e+01
cg 1.407221e+01
dtype: float64
这行代码将 max 函数应用于所有选定的列。
lambda 函数通常与 df.apply() 方法一起使用。
一个简单的示例是为数据框中的每一行返回其自身:
df.apply(lambda row: row, axis=1)
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.653 | 0.999500 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000 | 19053.186 | 1.724830 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000 | 1006300.297 | 44.941600 | 1.728144e+06 | 64.575551 | 14.072206 |
| 3 | Israel | ISR | 2000 | 6114.570 | 4.077330 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000 | 11801.505 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.939830 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000 | 282171.957 | 1.000000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000 | 3219.793 | 12.099592 | 2.525596e+04 | 78.978740 | 5.108068 |
Note
对于 .apply() 方法:
axis = 0 – 将函数应用于每列(变量)
axis = 1 – 将函数应用于每行(观测值)
axis = 0 是默认参数
我们可以将它与 .loc[] 一起使用来进行一些更高级的选择:
complexCondition = df.apply(
lambda row: row.POP > 40000 if row.country in ['Argentina', 'India', 'South Africa'] else row.POP < 20000,
axis=1), ['country', 'year', 'POP', 'XRAT', 'tcgdp']
这里的 df.apply() 返回一系列布尔值,表示满足 if-else 语句中指定条件的行。
此外,它还定义了感兴趣的变量子集:
complexCondition
(0 False
1 True
2 True
3 True
4 True
5 True
6 False
7 True
dtype: bool,
['country', 'year', 'POP', 'XRAT', 'tcgdp'])
当我们将此条件应用于数据框时,结果为:
df.loc[complexCondition]
| country | year | POP | XRAT | tcgdp | |
|---|---|---|---|---|---|
| 1 | Australia | 2000 | 19053.186 | 1.724830 | 5.418047e+05 |
| 2 | India | 2000 | 1006300.297 | 44.941600 | 1.728144e+06 |
| 3 | Israel | 2000 | 6114.570 | 4.077330 | 1.292539e+05 |
| 4 | Malawi | 2000 | 11801.505 | 59.543808 | 5.026222e+03 |
| 5 | South Africa | 2000 | 45064.098 | 6.939830 | 2.272424e+05 |
| 7 | Uruguay | 2000 | 3219.793 | 12.099592 | 2.525596e+04 |
17.3.4. 修改 DataFrames#
修改数据框的能力对于生成用于未来分析的干净数据集非常重要。
1. 我们可以方便地使用 df.where() 来”保留”我们已选择的行,并将其余行替换为 NaN:
df.where(df.POP >= 20000)
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000.0 | 37335.653 | 0.99950 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | India | IND | 2000.0 | 1006300.297 | 44.94160 | 1.728144e+06 | 64.575551 | 14.072206 |
| 3 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | South Africa | ZAF | 2000.0 | 45064.098 | 6.93983 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000.0 | 282171.957 | 1.00000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
2. 我们可以简单地使用 .loc[] 来指定我们想要修改的列,并赋值:
df.loc[df.cg == max(df.cg), 'cg'] = np.nan
df
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.653 | 0.999500 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000 | 19053.186 | 1.724830 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000 | 1006300.297 | 44.941600 | 1.728144e+06 | 64.575551 | NaN |
| 3 | Israel | ISR | 2000 | 6114.570 | 4.077330 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000 | 11801.505 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 6.939830 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000 | 282171.957 | 1.000000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000 | 3219.793 | 12.099592 | 2.525596e+04 | 78.978740 | 5.108068 |
3. 我们可以使用 .apply() 方法整体修改行/列:
def update_row(row):
# 修改 POP
row.POP = np.nan if row.POP<= 10000 else row.POP
# 修改 XRAT
row.XRAT = row.XRAT / 10
return row
df.apply(update_row, axis=1)
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.653 | 0.099950 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000 | 19053.186 | 0.172483 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000 | 1006300.297 | 4.494160 | 1.728144e+06 | 64.575551 | NaN |
| 3 | Israel | ISR | 2000 | NaN | 0.407733 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000 | 11801.505 | 5.954381 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000 | 45064.098 | 0.693983 | 2.272424e+05 | 72.718710 | 5.726546 |
| 6 | United States | USA | 2000 | 282171.957 | 0.100000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000 | NaN | 1.209959 | 2.525596e+04 | 78.978740 | 5.108068 |
4. 我们可以使用 .map() 方法一次修改数据框中所有单个条目:
# 将所有小数四舍五入到2位小数
df.map(lambda x : round(x,2) if type(x)!=str else x)
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000 | 37335.65 | 1.00 | 295072.22 | 75.72 | 5.58 |
| 1 | Australia | AUS | 2000 | 19053.19 | 1.72 | 541804.65 | 67.76 | 6.72 |
| 2 | India | IND | 2000 | 1006300.30 | 44.94 | 1728144.37 | 64.58 | NaN |
| 3 | Israel | ISR | 2000 | 6114.57 | 4.08 | 129253.89 | 64.44 | 10.27 |
| 4 | Malawi | MWI | 2000 | 11801.50 | 59.54 | 5026.22 | 74.71 | 11.66 |
| 5 | South Africa | ZAF | 2000 | 45064.10 | 6.94 | 227242.37 | 72.72 | 5.73 |
| 6 | United States | USA | 2000 | 282171.96 | 1.00 | 9898700.00 | 72.35 | 6.03 |
| 7 | Uruguay | URY | 2000 | 3219.79 | 12.10 | 25255.96 | 78.98 | 5.11 |
应用:缺失值插补
替换缺失值是数据整理的重要步骤。
让我们随机插入一些 NaN 值:
for idx in list(zip([0, 3, 5, 6], [3, 4, 6, 2])):
df.iloc[idx] = np.nan
df
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000.0 | NaN | 0.999500 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000.0 | 19053.186 | 1.724830 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000.0 | 1006300.297 | 44.941600 | 1.728144e+06 | 64.575551 | NaN |
| 3 | Israel | ISR | 2000.0 | 6114.570 | NaN | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000.0 | 11801.505 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000.0 | 45064.098 | 6.939830 | 2.272424e+05 | NaN | 5.726546 |
| 6 | United States | USA | NaN | 282171.957 | 1.000000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000.0 | 3219.793 | 12.099592 | 2.525596e+04 | 78.978740 | 5.108068 |
这里的 zip() 函数从两个列表中创建值对(即 [0,3]、[3,4] 等)。
我们可以再次使用 .map() 方法将所有缺失值替换为 0:
# 将所有NaN值替换为0
def replace_nan(x):
if type(x)!=str:
return 0 if np.isnan(x) else x
else:
return x
df.map(replace_nan)
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000.0 | 0.000 | 0.999500 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000.0 | 19053.186 | 1.724830 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000.0 | 1006300.297 | 44.941600 | 1.728144e+06 | 64.575551 | 0.000000 |
| 3 | Israel | ISR | 2000.0 | 6114.570 | 0.000000 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000.0 | 11801.505 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000.0 | 45064.098 | 6.939830 | 2.272424e+05 | 0.000000 | 5.726546 |
| 6 | United States | USA | 0.0 | 282171.957 | 1.000000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000.0 | 3219.793 | 12.099592 | 2.525596e+04 | 78.978740 | 5.108068 |
pandas 还为我们提供了便捷的方法来替换缺失值。
例如,使用变量均值进行单一插补在 pandas 中可以很容易地完成:
df = df.fillna(df.iloc[:,2:8].mean())
df
| country | country isocode | year | POP | XRAT | tcgdp | cc | cg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Argentina | ARG | 2000.0 | 1.962465e+05 | 0.999500 | 2.950722e+05 | 75.716805 | 5.578804 |
| 1 | Australia | AUS | 2000.0 | 1.905319e+04 | 1.724830 | 5.418047e+05 | 67.759026 | 6.720098 |
| 2 | India | IND | 2000.0 | 1.006300e+06 | 44.941600 | 1.728144e+06 | 64.575551 | 7.298802 |
| 3 | Israel | ISR | 2000.0 | 6.114570e+03 | 18.178451 | 1.292539e+05 | 64.436451 | 10.266688 |
| 4 | Malawi | MWI | 2000.0 | 1.180150e+04 | 59.543808 | 5.026222e+03 | 74.707624 | 11.658954 |
| 5 | South Africa | ZAF | 2000.0 | 4.506410e+04 | 6.939830 | 2.272424e+05 | 71.217322 | 5.726546 |
| 6 | United States | USA | 2000.0 | 2.821720e+05 | 1.000000 | 9.898700e+06 | 72.347054 | 6.032454 |
| 7 | Uruguay | URY | 2000.0 | 3.219793e+03 | 12.099592 | 2.525596e+04 | 78.978740 | 5.108068 |
缺失值插补是数据科学中的一个大领域,涉及各种机器学习技术。
Python 中还有更多 高级工具 可用于插补缺失值。
17.3.5. 标准化与可视化#
假设我们只对人口(POP)和总 GDP(tcgdp)感兴趣。
将数据框 df 缩减为仅包含这些变量的一种方法是使用上述选择方法覆盖数据框:
df = df[['country', 'POP', 'tcgdp']]
df
| country | POP | tcgdp | |
|---|---|---|---|
| 0 | Argentina | 1.962465e+05 | 2.950722e+05 |
| 1 | Australia | 1.905319e+04 | 5.418047e+05 |
| 2 | India | 1.006300e+06 | 1.728144e+06 |
| 3 | Israel | 6.114570e+03 | 1.292539e+05 |
| 4 | Malawi | 1.180150e+04 | 5.026222e+03 |
| 5 | South Africa | 4.506410e+04 | 2.272424e+05 |
| 6 | United States | 2.821720e+05 | 9.898700e+06 |
| 7 | Uruguay | 3.219793e+03 | 2.525596e+04 |
这里索引 0, 1,..., 7 是多余的,因为我们可以使用国家名称作为索引。
为此,我们将索引设置为数据框中的 country 变量:
df = df.set_index('country')
df
| POP | tcgdp | |
|---|---|---|
| country | ||
| Argentina | 1.962465e+05 | 2.950722e+05 |
| Australia | 1.905319e+04 | 5.418047e+05 |
| India | 1.006300e+06 | 1.728144e+06 |
| Israel | 6.114570e+03 | 1.292539e+05 |
| Malawi | 1.180150e+04 | 5.026222e+03 |
| South Africa | 4.506410e+04 | 2.272424e+05 |
| United States | 2.821720e+05 | 9.898700e+06 |
| Uruguay | 3.219793e+03 | 2.525596e+04 |
让我们给列取更好的名称:
df.columns = 'population', 'total GDP'
df
| population | total GDP | |
|---|---|---|
| country | ||
| Argentina | 1.962465e+05 | 2.950722e+05 |
| Australia | 1.905319e+04 | 5.418047e+05 |
| India | 1.006300e+06 | 1.728144e+06 |
| Israel | 6.114570e+03 | 1.292539e+05 |
| Malawi | 1.180150e+04 | 5.026222e+03 |
| South Africa | 4.506410e+04 | 2.272424e+05 |
| United States | 2.821720e+05 | 9.898700e+06 |
| Uruguay | 3.219793e+03 | 2.525596e+04 |
population 变量以千为单位,让我们恢复为单个单位:
df['population'] = df['population'] * 1e3
df
| population | total GDP | |
|---|---|---|
| country | ||
| Argentina | 1.962465e+08 | 2.950722e+05 |
| Australia | 1.905319e+07 | 5.418047e+05 |
| India | 1.006300e+09 | 1.728144e+06 |
| Israel | 6.114570e+06 | 1.292539e+05 |
| Malawi | 1.180150e+07 | 5.026222e+03 |
| South Africa | 4.506410e+07 | 2.272424e+05 |
| United States | 2.821720e+08 | 9.898700e+06 |
| Uruguay | 3.219793e+06 | 2.525596e+04 |
接下来,我们将添加一列显示人均实际 GDP,乘以 1,000,000,因为总 GDP 以百万为单位:
df['GDP percap'] = df['total GDP'] * 1e6 / df['population']
df
| population | total GDP | GDP percap | |
|---|---|---|---|
| country | |||
| Argentina | 1.962465e+08 | 2.950722e+05 | 1503.579625 |
| Australia | 1.905319e+07 | 5.418047e+05 | 28436.433261 |
| India | 1.006300e+09 | 1.728144e+06 | 1717.324719 |
| Israel | 6.114570e+06 | 1.292539e+05 | 21138.672749 |
| Malawi | 1.180150e+07 | 5.026222e+03 | 425.896679 |
| South Africa | 4.506410e+07 | 2.272424e+05 | 5042.647686 |
| United States | 2.821720e+08 | 9.898700e+06 | 35080.381854 |
| Uruguay | 3.219793e+06 | 2.525596e+04 | 7843.970620 |
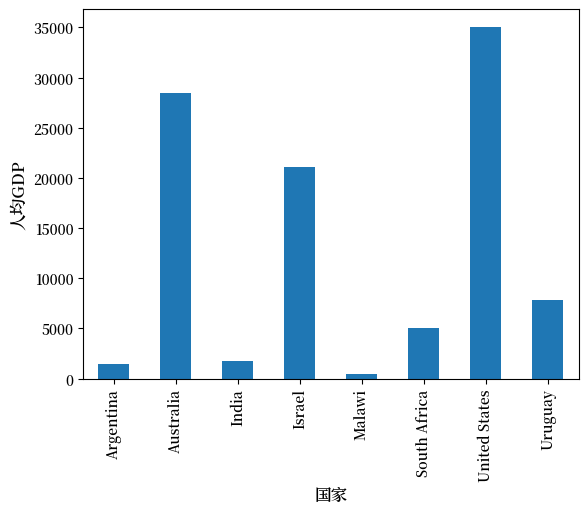
pandas DataFrame 和 Series 对象的一个优点是它们具有通过 Matplotlib 进行绘图和可视化的方法。
例如,我们可以轻松地生成人均 GDP 的条形图:
ax = df['GDP percap'].plot(kind='bar')
ax.set_xlabel('国家', fontsize=12)
ax.set_ylabel('人均GDP', fontsize=12)
plt.show()
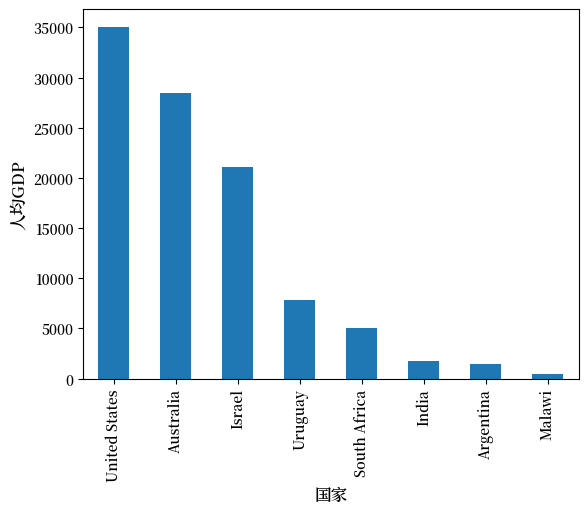
目前数据框按国家字母顺序排列——让我们改为按人均 GDP 排列:
df = df.sort_values(by='GDP percap', ascending=False)
df
| population | total GDP | GDP percap | |
|---|---|---|---|
| country | |||
| United States | 2.821720e+08 | 9.898700e+06 | 35080.381854 |
| Australia | 1.905319e+07 | 5.418047e+05 | 28436.433261 |
| Israel | 6.114570e+06 | 1.292539e+05 | 21138.672749 |
| Uruguay | 3.219793e+06 | 2.525596e+04 | 7843.970620 |
| South Africa | 4.506410e+07 | 2.272424e+05 | 5042.647686 |
| India | 1.006300e+09 | 1.728144e+06 | 1717.324719 |
| Argentina | 1.962465e+08 | 2.950722e+05 | 1503.579625 |
| Malawi | 1.180150e+07 | 5.026222e+03 | 425.896679 |
与之前一样进行绘图现在会产生:
ax = df['GDP percap'].plot(kind='bar')
ax.set_xlabel('国家', fontsize=12)
ax.set_ylabel('人均GDP', fontsize=12)
plt.show()
17.4. 在线数据来源#
Python 使得以编程方式查询在线数据库变得简单。
对于经济学家来说,一个重要的数据库是 FRED —— 由圣路易斯联储维护的大量时间序列数据集合。
例如,假设我们对失业率感兴趣。
(要将数据下载为 csv,点击右上角的 Download 并选择 CSV (data) 选项。)
或者,我们可以在 Python 程序中访问 CSV 文件。
这可以通过多种方法完成。
我们从一个相对低级的方法开始,然后回到 pandas。
17.4.1. 使用 requests 访问数据#
一个选择是使用 requests,这是一个用于通过互联网请求数据的标准 Python 库。
首先,在你的计算机上尝试以下代码:
r = requests.get('https://fred.stlouisfed.org/graph/fredgraph.csv?bgcolor=%23e1e9f0&chart_type=line&drp=0&fo=open%20sans&graph_bgcolor=%23ffffff&height=450&mode=fred&recession_bars=on&txtcolor=%23444444&ts=12&tts=12&width=1318&nt=0&thu=0&trc=0&show_legend=yes&show_axis_titles=yes&show_tooltip=yes&id=UNRATE&scale=left&cosd=1948-01-01&coed=2024-06-01&line_color=%234572a7&link_values=false&line_style=solid&mark_type=none&mw=3&lw=2&ost=-99999&oet=99999&mma=0&fml=a&fq=Monthly&fam=avg&fgst=lin&fgsnd=2020-02-01&line_index=1&transformation=lin&vintage_date=2024-07-29&revision_date=2024-07-29&nd=1948-01-01')
如果没有错误消息,则调用成功。
如果你确实收到了错误,那么有两种可能的原因:
你没有连接到互联网——希望这不是问题所在。
你的机器通过代理服务器访问互联网,而 Python 不知道这一点。
在第二种情况下,你可以:
切换到另一台机器
通过阅读文档解决代理问题
假设一切正常,你现在可以使用调用 requests.get('https://research.stlouisfed.org/fred2/series/UNRATE/downloaddata/UNRATE.csv') 返回的 source 对象继续操作:
url = 'https://fred.stlouisfed.org/graph/fredgraph.csv?bgcolor=%23e1e9f0&chart_type=line&drp=0&fo=open%20sans&graph_bgcolor=%23ffffff&height=450&mode=fred&recession_bars=on&txtcolor=%23444444&ts=12&tts=12&width=1318&nt=0&thu=0&trc=0&show_legend=yes&show_axis_titles=yes&show_tooltip=yes&id=UNRATE&scale=left&cosd=1948-01-01&coed=2024-06-01&line_color=%234572a7&link_values=false&line_style=solid&mark_type=none&mw=3&lw=2&ost=-99999&oet=99999&mma=0&fml=a&fq=Monthly&fam=avg&fgst=lin&fgsnd=2020-02-01&line_index=1&transformation=lin&vintage_date=2024-07-29&revision_date=2024-07-29&nd=1948-01-01'
source = requests.get(url).content.decode().split("\n")
source[0]
'observation_date,UNRATE'
source[1]
'1948-01-01,3.4'
source[2]
'1948-02-01,3.8'
我们现在可以编写一些额外的代码来解析这个文本并将其存储为数组。
但这是不必要的——pandas 的 read_csv 函数可以为我们处理这个任务。
我们使用 parse_dates=True,这样 pandas 就能识别我们的日期列,从而能够进行简单的日期过滤:
data = pd.read_csv(url, index_col=0, parse_dates=True)
数据已被读入一个名为 data 的 pandas DataFrame,我们现在可以以通常的方式操作它:
type(data)
pandas.core.frame.DataFrame
data.head() # 一个有用的方法,可以快速查看数据框
| UNRATE | |
|---|---|
| observation_date | |
| 1948-01-01 | 3.4 |
| 1948-02-01 | 3.8 |
| 1948-03-01 | 4.0 |
| 1948-04-01 | 3.9 |
| 1948-05-01 | 3.5 |
pd.set_option('display.precision', 1)
data.describe() # 你的输出可能略有不同
| UNRATE | |
|---|---|
| count | 918.0 |
| mean | 5.7 |
| std | 1.7 |
| min | 2.5 |
| 25% | 4.4 |
| 50% | 5.5 |
| 75% | 6.7 |
| max | 14.8 |
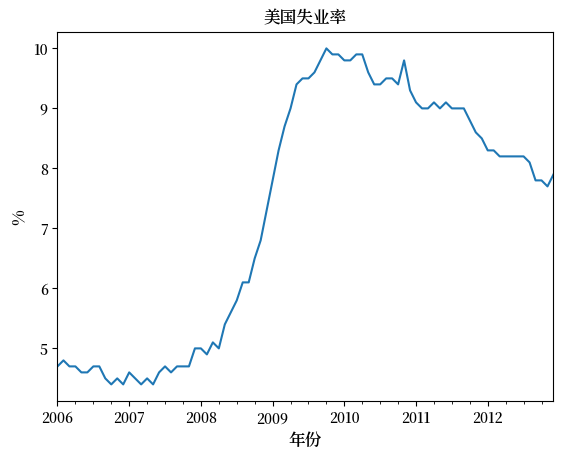
我们还可以如下绘制 2006 年至 2012 年的失业率:
ax = data['2006':'2012'].plot(title='美国失业率', legend=False)
ax.set_xlabel('年份', fontsize=12)
ax.set_ylabel('%', fontsize=12)
plt.show()
请注意,pandas 提供了许多其他文件类型的替代方案。
pandas 有多种顶级方法,我们可以用来读取 excel、json、parquet 文件或直接连接到数据库服务器。
17.4.2. 使用 wbgapi 和 yfinance 访问数据#
wbgapi Python 库可用于从世界银行发布的众多数据库中获取数据。
我们还将在练习中使用 yfinance 从 Yahoo Finance 获取数据。
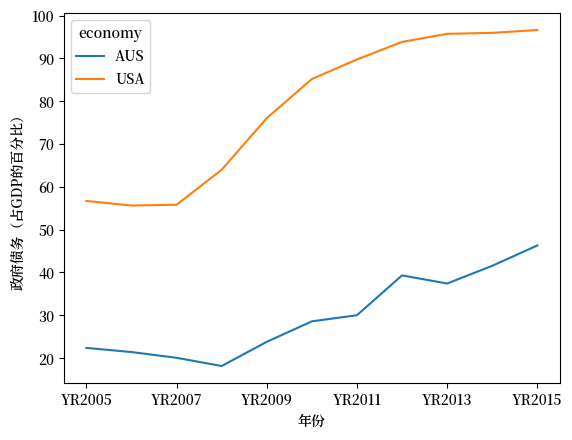
现在让我们来看一个下载和绘制数据的示例——这次来自世界银行。
世界银行收集并整理了大量指标的数据。
例如,这里是一些关于政府债务占 GDP 比率的数据。
下面的代码示例为你获取数据并绘制美国和澳大利亚的时间序列:
import wbgapi as wb
wb.series.info('GC.DOD.TOTL.GD.ZS')
| id | value |
|---|---|
| GC.DOD.TOTL.GD.ZS | Central government debt, total (% of GDP) |
| 1 elements |
govt_debt = wb.data.DataFrame('GC.DOD.TOTL.GD.ZS', economy=['USA','AUS'], time=range(2005,2016))
govt_debt = govt_debt.T # 将年份从列移到行以便绘图
govt_debt.plot(xlabel='年份', ylabel='政府债务(占GDP的百分比)');
17.5. 练习#
Exercise 17.1
使用以下导入:
import datetime as dt
import yfinance as yf
编写一个程序,计算以下股票在 2021 年的价格百分比变化:
ticker_list = {'INTC': 'Intel',
'MSFT': 'Microsoft',
'IBM': 'IBM',
'BHP': 'BHP',
'TM': 'Toyota',
'AAPL': 'Apple',
'AMZN': 'Amazon',
'C': 'Citigroup',
'QCOM': 'Qualcomm',
'KO': 'Coca-Cola',
'GOOG': 'Google'}
以下是程序的第一部分:
def read_data(ticker_list,
start=dt.datetime(2021, 1, 1),
end=dt.datetime(2021, 12, 31)):
"""
此函数从 Yahoo 读取 ticker_list 中每个
股票代码的收盘价数据。
"""
ticker = pd.DataFrame()
for tick in ticker_list:
stock = yf.Ticker(tick)
prices = stock.history(start=start, end=end)
# 将索引改为仅日期
prices.index = pd.to_datetime(prices.index.date)
closing_prices = prices['Close']
ticker[tick] = closing_prices
return ticker
ticker = read_data(ticker_list)
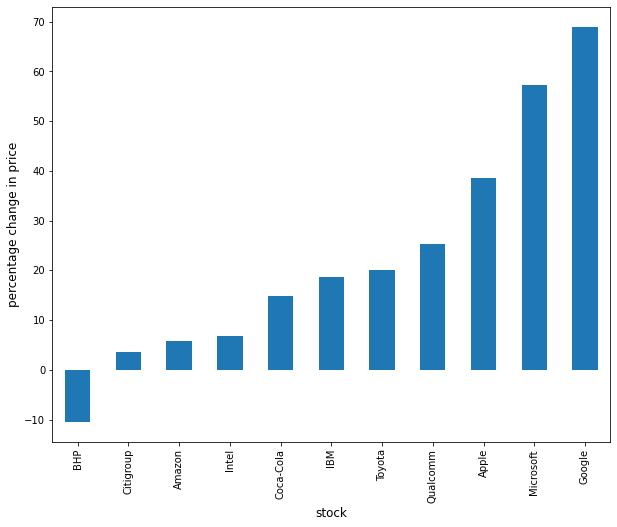
完成程序,将结果绘制为如下所示的条形图:
Solution
有几种方法可以使用 pandas 计算百分比变化来解决这个问题。
首先,你可以提取数据并执行如下计算:
p1 = ticker.iloc[0] # 获取第一组价格作为 Series
p2 = ticker.iloc[-1] # 获取最后一组价格作为 Series
price_change = (p2 - p1) / p1 * 100
price_change
INTC 6.9
MSFT 57.2
IBM 18.7
BHP -2.2
TM 23.4
AAPL 38.6
AMZN 5.8
C 3.6
QCOM 25.3
KO 14.9
GOOG 69.0
dtype: float64
或者,你可以使用内置方法 pct_change,并使用 periods 参数配置它以执行正确的计算:
change = ticker.pct_change(periods=len(ticker)-1, axis='rows')*100
price_change = change.iloc[-1]
price_change
INTC 6.9
MSFT 57.2
IBM 18.7
BHP -2.2
TM 23.4
AAPL 38.6
AMZN 5.8
C 3.6
QCOM 25.3
KO 14.9
GOOG 69.0
Name: 2021-12-30 00:00:00, dtype: float64
然后绘制图表:
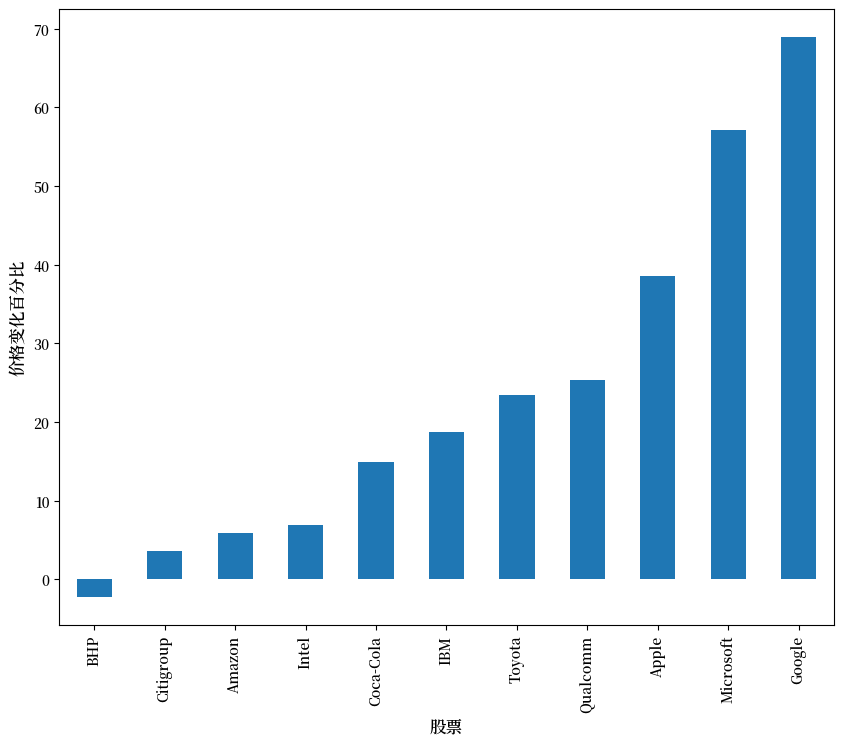
price_change.sort_values(inplace=True)
price_change.rename(index=ticker_list, inplace=True)
/tmp/ipykernel_2694/1503263560.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
price_change.sort_values(inplace=True)
/tmp/ipykernel_2694/1503263560.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
price_change.rename(index=ticker_list, inplace=True)
fig, ax = plt.subplots(figsize=(10,8))
ax.set_xlabel('股票', fontsize=12)
ax.set_ylabel('价格变化百分比', fontsize=12)
price_change.plot(kind='bar', ax=ax)
plt.show()
Exercise 17.2
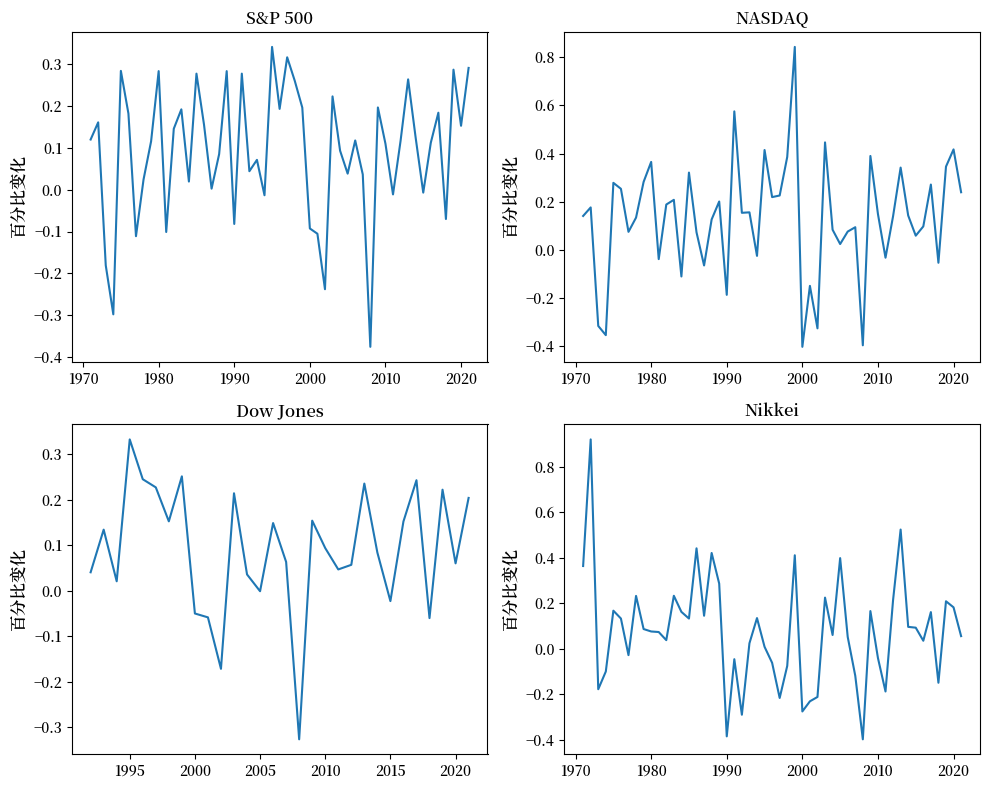
使用 Exercise 17.1 中介绍的 read_data 方法,编写一个程序来获取以下指数的年同比百分比变化:
indices_list = {'^GSPC': 'S&P 500',
'^IXIC': 'NASDAQ',
'^DJI': 'Dow Jones',
'^N225': 'Nikkei'}
完成程序,显示汇总统计数据并将结果绘制为如下所示的时间序列图:
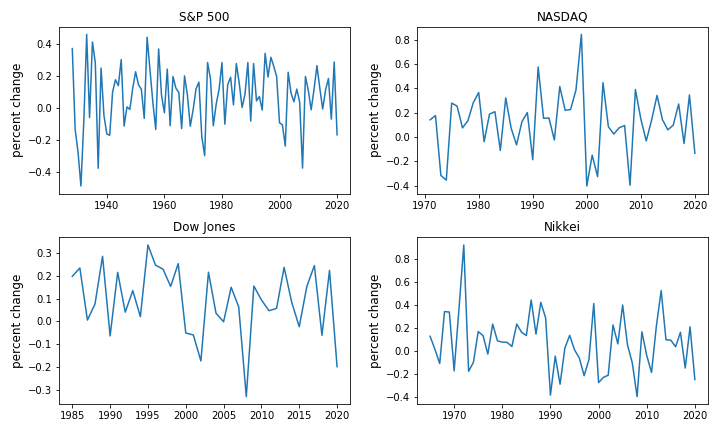
Solution
按照你在 Exercise 17.1 中所做的工作,你可以通过相应地更新开始和结束日期,使用 read_data 查询数据:
indices_data = read_data(
indices_list,
start=dt.datetime(1971, 1, 1), # 共同起始日期
end=dt.datetime(2021, 12, 31)
)
然后,提取每年的第一组和最后一组价格作为 DataFrames,并计算年度回报:
yearly_returns = pd.DataFrame()
for index, name in indices_list.items():
p1 = indices_data.groupby(indices_data.index.year)[index].first() # 获取第一组回报作为 DataFrame
p2 = indices_data.groupby(indices_data.index.year)[index].last() # 获取最后一组回报作为 DataFrame
returns = (p2 - p1) / p1
yearly_returns[name] = returns
yearly_returns
| S&P 500 | NASDAQ | Dow Jones | Nikkei | |
|---|---|---|---|---|
| 1971 | 1.2e-01 | 1.4e-01 | NaN | 3.6e-01 |
| 1972 | 1.6e-01 | 1.8e-01 | NaN | 9.2e-01 |
| 1973 | -1.8e-01 | -3.2e-01 | NaN | -1.8e-01 |
| 1974 | -3.0e-01 | -3.5e-01 | NaN | -9.9e-02 |
| 1975 | 2.8e-01 | 2.8e-01 | NaN | 1.7e-01 |
| 1976 | 1.8e-01 | 2.5e-01 | NaN | 1.3e-01 |
| 1977 | -1.1e-01 | 7.5e-02 | NaN | -2.7e-02 |
| 1978 | 2.4e-02 | 1.3e-01 | NaN | 2.3e-01 |
| 1979 | 1.2e-01 | 2.8e-01 | NaN | 8.7e-02 |
| 1980 | 2.8e-01 | 3.7e-01 | NaN | 7.7e-02 |
| 1981 | -1.0e-01 | -3.8e-02 | NaN | 7.4e-02 |
| 1982 | 1.5e-01 | 1.9e-01 | NaN | 3.9e-02 |
| 1983 | 1.9e-01 | 2.1e-01 | NaN | 2.3e-01 |
| 1984 | 2.0e-02 | -1.1e-01 | NaN | 1.6e-01 |
| 1985 | 2.8e-01 | 3.2e-01 | NaN | 1.3e-01 |
| 1986 | 1.6e-01 | 7.3e-02 | NaN | 4.4e-01 |
| 1987 | 2.6e-03 | -6.4e-02 | NaN | 1.5e-01 |
| 1988 | 8.5e-02 | 1.3e-01 | NaN | 4.2e-01 |
| 1989 | 2.8e-01 | 2.0e-01 | NaN | 2.9e-01 |
| 1990 | -8.2e-02 | -1.9e-01 | NaN | -3.8e-01 |
| 1991 | 2.8e-01 | 5.8e-01 | NaN | -4.5e-02 |
| 1992 | 4.4e-02 | 1.5e-01 | 4.1e-02 | -2.9e-01 |
| 1993 | 7.1e-02 | 1.6e-01 | 1.3e-01 | 2.5e-02 |
| 1994 | -1.3e-02 | -2.4e-02 | 2.1e-02 | 1.4e-01 |
| 1995 | 3.4e-01 | 4.1e-01 | 3.3e-01 | 9.4e-03 |
| 1996 | 1.9e-01 | 2.2e-01 | 2.5e-01 | -6.1e-02 |
| 1997 | 3.2e-01 | 2.3e-01 | 2.3e-01 | -2.2e-01 |
| 1998 | 2.6e-01 | 3.9e-01 | 1.5e-01 | -7.5e-02 |
| 1999 | 2.0e-01 | 8.4e-01 | 2.5e-01 | 4.1e-01 |
| 2000 | -9.3e-02 | -4.0e-01 | -5.0e-02 | -2.7e-01 |
| 2001 | -1.1e-01 | -1.5e-01 | -5.9e-02 | -2.3e-01 |
| 2002 | -2.4e-01 | -3.3e-01 | -1.7e-01 | -2.1e-01 |
| 2003 | 2.2e-01 | 4.5e-01 | 2.1e-01 | 2.3e-01 |
| 2004 | 9.3e-02 | 8.4e-02 | 3.6e-02 | 6.1e-02 |
| 2005 | 3.8e-02 | 2.5e-02 | -1.1e-03 | 4.0e-01 |
| 2006 | 1.2e-01 | 7.6e-02 | 1.5e-01 | 5.3e-02 |
| 2007 | 3.7e-02 | 9.5e-02 | 6.3e-02 | -1.2e-01 |
| 2008 | -3.8e-01 | -4.0e-01 | -3.3e-01 | -4.0e-01 |
| 2009 | 2.0e-01 | 3.9e-01 | 1.5e-01 | 1.7e-01 |
| 2010 | 1.1e-01 | 1.5e-01 | 9.4e-02 | -4.0e-02 |
| 2011 | -1.1e-02 | -3.2e-02 | 4.7e-02 | -1.9e-01 |
| 2012 | 1.2e-01 | 1.4e-01 | 5.7e-02 | 2.1e-01 |
| 2013 | 2.6e-01 | 3.4e-01 | 2.4e-01 | 5.2e-01 |
| 2014 | 1.2e-01 | 1.4e-01 | 8.4e-02 | 9.7e-02 |
| 2015 | -6.9e-03 | 5.9e-02 | -2.3e-02 | 9.3e-02 |
| 2016 | 1.1e-01 | 9.8e-02 | 1.5e-01 | 3.6e-02 |
| 2017 | 1.8e-01 | 2.7e-01 | 2.4e-01 | 1.6e-01 |
| 2018 | -7.0e-02 | -5.3e-02 | -6.0e-02 | -1.5e-01 |
| 2019 | 2.9e-01 | 3.5e-01 | 2.2e-01 | 2.1e-01 |
| 2020 | 1.5e-01 | 4.2e-01 | 6.0e-02 | 1.8e-01 |
| 2021 | 2.9e-01 | 2.4e-01 | 2.0e-01 | 5.6e-02 |
接下来,你可以使用 describe 方法获取汇总统计数据:
yearly_returns.describe()
| S&P 500 | NASDAQ | Dow Jones | Nikkei | |
|---|---|---|---|---|
| count | 5.1e+01 | 5.1e+01 | 3.0e+01 | 5.1e+01 |
| mean | 9.2e-02 | 1.3e-01 | 9.1e-02 | 7.9e-02 |
| std | 1.6e-01 | 2.5e-01 | 1.4e-01 | 2.4e-01 |
| min | -3.8e-01 | -4.0e-01 | -3.3e-01 | -4.0e-01 |
| 25% | -2.2e-03 | 1.6e-04 | 2.5e-02 | -6.8e-02 |
| 50% | 1.2e-01 | 1.4e-01 | 8.9e-02 | 7.7e-02 |
| 75% | 2.0e-01 | 2.8e-01 | 2.1e-01 | 2.0e-01 |
| max | 3.4e-01 | 8.4e-01 | 3.3e-01 | 9.2e-01 |
然后,绘制图表:
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
for iter_, ax in enumerate(axes.flatten()): # 将二维数组展平为一维数组
index_name = yearly_returns.columns[iter_] # 每次迭代获取指数名称
ax.plot(yearly_returns[index_name]) # 绘制每个指数年度回报的百分比变化
ax.set_ylabel("百分比变化", fontsize = 12)
ax.set_title(index_name)
plt.tight_layout()