45. 最大似然估计#
from scipy.stats import lognorm, pareto, expon
import numpy as np
from scipy.integrate import quad
import matplotlib.pyplot as plt
import matplotlib as mpl
import pandas as pd
from math import exp
FONTPATH = "fonts/SourceHanSerifSC-SemiBold.otf"
mpl.font_manager.fontManager.addfont(FONTPATH)
plt.rcParams['font.family'] = ['Source Han Serif SC']
45.1. 介绍#
假设你是一位政策制定者,你想尝试估算增加财富税将带来多少收入。
财富税的计算公式为:
其中 \(w\) 代表财富。
Example 45.1
例如,如果 \(a = 0.05\),\(b = 0.1\),且 \(\bar w = 2.5\),意味着:
对于2.5及以下的财富征收5%的税,
对超过2.5的部分征收10%的税。
这里财富的单位是100,000,所以 \(w= 2.5\) 指 250,000 美元。
接下来,我们定义函数 \(h\):
def h(w, a=0.05, b=0.1, w_bar=2.5):
if w <= w_bar:
return a * w
else:
return a * w_bar + b * (w - w_bar)
对于一个人口数量为 \(N\) 的地区,每个人 \(i\) 拥有财富 \(w_i\),则财富税收入总额为
而我们希望计算这一数量。
但问题是,在大多数国家中,并不是所有的个人财富都能被观测到。
收集并追踪一国所有个人或家庭的财富数据是非常困难的。
因此,假设我们得到了一个样本 \(w_1, w_2, \cdots, w_n\),它包含了 \(n\) 位随机选择的个人的财富。
在练习中,我们将使用 \(n = 10,000\) 来自2016年美国的财富数据样本。
n = 10_000
这些数据来源于消费者财务状况调查 (SCF)。
以下代码导入了数据并将其读入名为 sample 的数组。
我们先绘制该样本的直方图。
fig, ax = plt.subplots()
ax.set_xlim(-1, 20)
density, edges = np.histogram(sample, bins=5000, density=True)
prob = density * np.diff(edges)
plt.stairs(prob, edges, fill=True, alpha=0.8, label=r"单位:\$100,000")
plt.ylabel("概率")
plt.xlabel("净资产")
plt.legend()
plt.show()
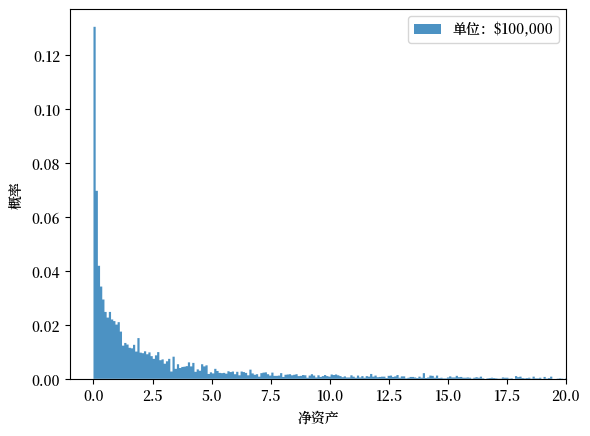
该直方图显示,大部分人的财富水平很低,而少部分人却拥有非常多的财富。
我们假定全体人口规模为
N = 100_000_000
仅依靠样本数据,我们又该如何估计全体人口的总收入呢?
我们的计划是,假设每个人的财富是从密度为 \(f\) 的分布中抽取的。
如果我们获得 \(f\) 的估计,那么我们可以按照以下方式近似 \(T\):
(根据大数定律,样本均值应该接近总体均值。)
现在的问题是:我们要如何估计 \(f\)?
45.2. 最大似然估计#
最大似然估计 是一种估计未知分布的方法。
最大似然估计有两个步骤:
猜测潜在分布是什么(例如,均值为 \(\mu\),标准差为 \(\sigma\) 的正态分布)。
估计参数值(例如,估计正态分布的 \(\mu\) 和 \(\sigma\))。
对于财富而言,一种假设是每个 \(w_i\) 都符合对数正态分布的,其中参数 \(\mu \in (-\infty, \infty)\),\(\sigma \in (0, \infty)\)。
(这意味着 \(\ln w_i\) 是以 \(\mu\) 为均值,\(\sigma\) 为标准差的正态分布。)
不难发现,这个假设不是完全没有道理,因为如果我们用直方图表示财富的对数(而不是财富本身),直方图将看起来像一个钟形曲线。
ln_sample = np.log(sample)
fig, ax = plt.subplots()
ax.hist(ln_sample, density=True, bins=200, histtype='stepfilled', alpha=0.8)
plt.show()
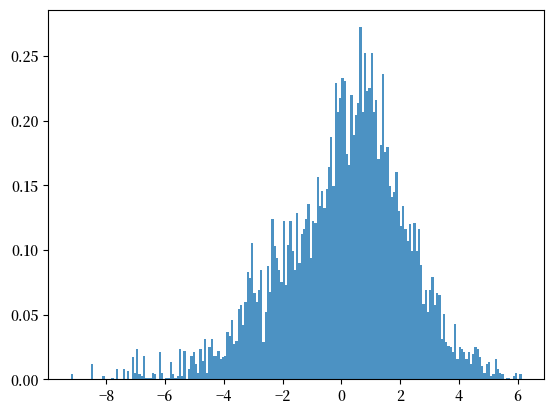
我们现在的任务是获取 \(\mu\) 和 \(\sigma\) 的最大似然估计值,我们用 \(\hat{\mu}\) 和 \(\hat{\sigma}\) 表示。
这些估计值可以通过最大化给定数据的似然函数获得。
对数正态分布随机变量 \(X\) 的概率密度函数 (PDF) 如下:
对于我们的样本 \(w_1, w_2, \cdots, w_n\),似然函数是:
似然函数可以被视为:
样本(假设是独立同分布)的联合分布和
给定数据的参数 \((\mu, \sigma)\) 的“似然性”。
对两边取对数,我们得到对数似然函数:
要找到这个函数的最大值,我们需要计算对 \(\mu\) 和 \(\sigma ^2\) 的偏导数,并令结果为 \(0\).
我们首先推导 \(\mu\) 的最大似然估计(MLE)
现在让我们推导 \(\sigma\) 的最大似然估计
至此我们已经推导出 \(\hat{\mu}\) 和 \(\hat{\sigma}\) 的表达式,现在要通过财富样本计算具体数值。
μ_hat = np.mean(ln_sample) # 计算 μ 的估计值
μ_hat
0.0634375526654064
num = (ln_sample - μ_hat)**2 # 计算方差的分子
σ_hat = (np.mean(num))**(1/2) # 计算 σ 的估计值
σ_hat
2.1507346258433424
我们绘制对数正态分布概率密度函数(使用估计的参数),并与样本数据进行对比。
dist_lognorm = lognorm(σ_hat, scale = exp(μ_hat)) # 初始化对数正态分布
x = np.linspace(0,50,10000) # 产生数据点
fig, ax = plt.subplots() # 创建图形和轴
ax.set_xlim(-1,20) # 设置x轴的范围
ax.hist(sample, density=True, bins=5_000, histtype='stepfilled', alpha=0.5) # 绘制样本的直方图
ax.plot(x, dist_lognorm.pdf(x), 'k-', lw=0.5, label='对数正态分布PDF') # 绘制对数正态分布的PDF
ax.legend() # 显示图例
plt.show() # 展示图形
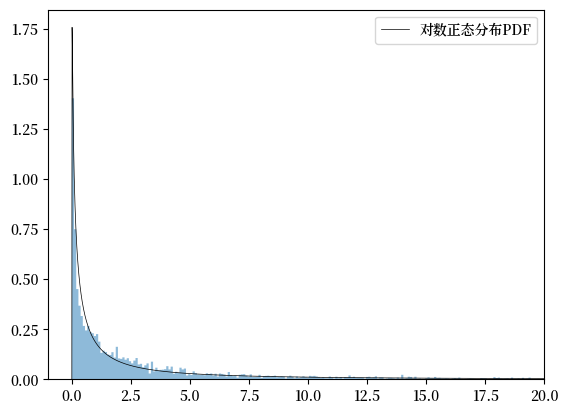
我们估计的对数正态分布看起来很适合整体数据。
我们现在使用方程(45.1)来计算总收入。
我们将通过 SciPy 的 quad 函数,使用数值积分的方式计算积分。
def total_revenue(dist):
integral, _ = quad(lambda x: h(x) * dist.pdf(x), 0, 100_000) # 计算积分
T = N * integral # 总收入 = 人数 * 单个收入
return T # 返回总收入
tr_lognorm = total_revenue(dist_lognorm) # 使用对数正态分布计算总收入
tr_lognorm # 显示总收入
101105326.82814859
(我们的单位是10万美元,这意味着实际收入是这一数字的10万倍。)
45.3. 帕累托分布#
如上所示,使用最大似然估计时,我们需要先对分布做出假设。
刚才我们假定这个分布是对数正态分布。
如果,我们改为假设 \(w_i\) 抽样自参数为 \(b\) 和 \(x_m\) 的帕累托分布。
在这种情况下,最大似然估计为
下面,我们来计算它们。
xm_hat = min(sample)
xm_hat
0.0001
den = np.log(sample/xm_hat)
b_hat = 1/np.mean(den)
b_hat
0.10783091940803055
现在让我们重新计算总收入。
dist_pareto = pareto(b = b_hat, scale = xm_hat)
tr_pareto = total_revenue(dist_pareto)
tr_pareto
12933168365.762571
这个数字差别很大!
tr_pareto / tr_lognorm
127.91777418162567
可见,选择正确的分布极其重要。
我们将拟合的帕累托分布与直方图进行比较:
fig, ax = plt.subplots()
ax.set_xlim(-1, 20)
ax.set_ylim(0,1.75)
ax.hist(sample, density=True, bins=5_000, histtype='stepfilled', alpha=0.5)
ax.plot(x, dist_pareto.pdf(x), 'k-', lw=0.5, label='帕累托分布PDF')
ax.legend()
plt.show()
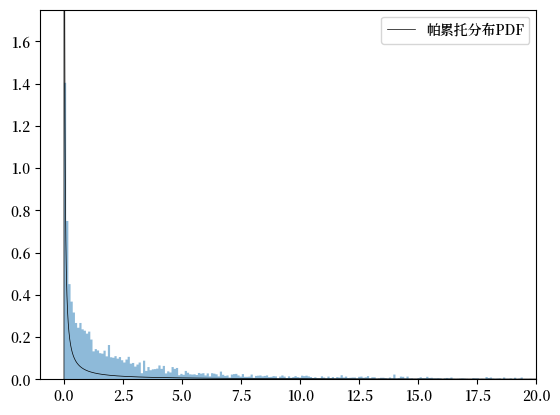
我们观察到在这种情况下,帕累托分布的拟合效果并不理想,所以我们很可能会拒绝这一假设。
45.4. 最好的分布是怎样的?#
没有“最好”的分布——我们做出的每一个选择,都只是一种假设。
我们唯一能做的,就是不断尝试,选择一个能很好拟合数据的分布。
上面的图表表明,对数正态分布是最佳的。
然而,当我们检查右尾部(最富有的人)时,帕累托分布可能是一个更好的选择。
要看清楚这一点,让我们设定数据集中净资产最低阈值。
我们不妨设定阈值为 $500,000,并将数据读入 sample_tail。
接下来,绘制这些数据。
fig, ax = plt.subplots()
ax.set_xlim(0,50)
ax.hist(sample_tail, density=True, bins=500, histtype='stepfilled', alpha=0.8)
plt.show()
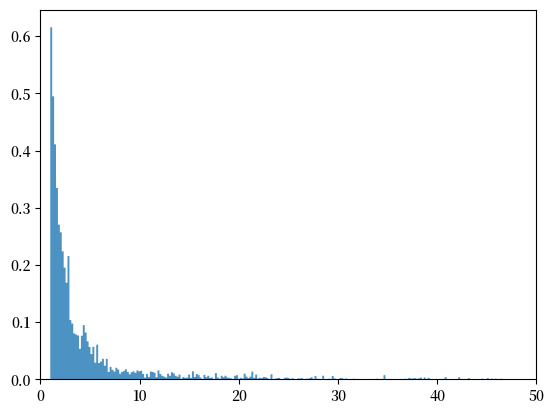
现在,我们尝试用不同的分布来拟合数据。
45.4.1. 用对数正态分布拟合右尾部#
让我们从对数正态分布开始。
我们重新估计参数并绘制概率密度函数,与数据进行对比。
ln_sample_tail = np.log(sample_tail)
μ_hat_tail = np.mean(ln_sample_tail)
num_tail = (ln_sample_tail - μ_hat_tail)**2
σ_hat_tail = (np.mean(num_tail))**(1/2)
dist_lognorm_tail = lognorm(σ_hat_tail, scale = exp(μ_hat_tail))
fig, ax = plt.subplots()
ax.set_xlim(0,50)
ax.hist(sample_tail, density=True, bins=500, histtype='stepfilled', alpha=0.5)
ax.plot(x, dist_lognorm_tail.pdf(x), 'k-', lw=0.5, label='对数正态分布PDF')
ax.legend()
plt.show()
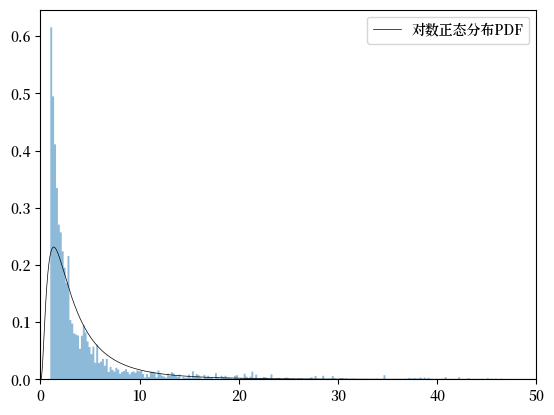
虽然对数正态分布对整个数据集拟合良好, 但它对于右尾部的拟合效果并不好。
45.4.2. 用帕累托分布拟合右尾部#
现在假设截取的数据集符合帕累托分布。
我们再次估计参数,并将概率密度函数与数据进行对比。
xm_hat_tail = min(sample_tail)
den_tail = np.log(sample_tail/xm_hat_tail)
b_hat_tail = 1/np.mean(den_tail)
dist_pareto_tail = pareto(b = b_hat_tail, scale = xm_hat_tail)
fig, ax = plt.subplots()
ax.set_xlim(0, 50)
ax.set_ylim(0,0.65)
ax.hist(sample_tail, density=True, bins= 500, histtype='stepfilled', alpha=0.5)
ax.plot(x, dist_pareto_tail.pdf(x), 'k-', lw=0.5, label='帕累托分布PDF')
plt.show()
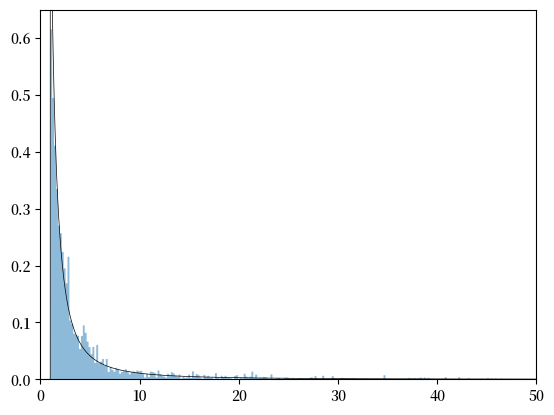
帕累托分布更适合数据集的右尾部。
45.4.3. 到底什么才是最好的分布?#
如刚才所言,没有“最好”的分布——每个选择都只是一种假设。
我们只需要检验我们认为合理的分布。
一种检验方法是,将数据与拟合分布进行绘图,如我们刚才所做的。
还有其他更严谨的测试方法,比如科尔莫格罗夫一斯米尔诺夫拟合优度检验。
我们省略了这些更深入的主题(但我们鼓励读者在完成这些讲座后研究它们)。
45.5. 练习#
Exercise 45.1
假设我们假设财富是以参数 \(\lambda > 0\) 的指数分布。
\(\lambda\) 的最大似然估计为
计算我们初始样本的 \(\hat{\lambda}\)。
使用 \(\hat{\lambda}\) 来计算总收入
Solution to Exercise 45.1
λ_hat = 1/np.mean(sample)
λ_hat
0.15234120963403971
dist_exp = expon(scale = 1/λ_hat)
tr_expo = total_revenue(dist_exp)
tr_expo
55246978.53427645
Exercise 45.2
绘制指数分布曲线,与样本比较并讨论它的拟合效果。
Solution to Exercise 45.2
fig, ax = plt.subplots()
ax.set_xlim(-1, 20)
ax.hist(sample, density=True, bins=5000, histtype='stepfilled', alpha=0.5)
ax.plot(x, dist_exp.pdf(x), 'k-', lw=0.5, label='指数分布PDF')
ax.legend()
plt.show()
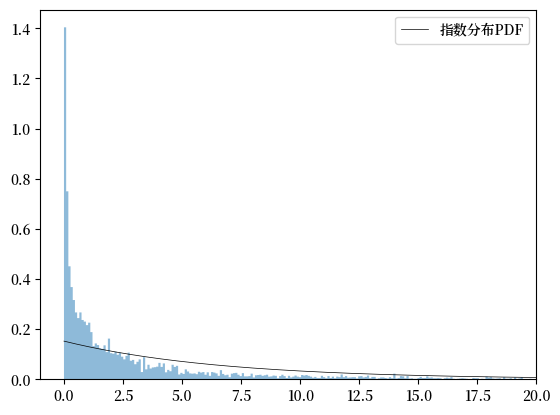
显然,这个分布对数据的拟合效果并不好。